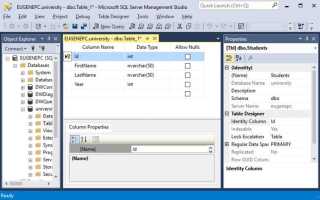
Правильное название для колонки в SQL – это не просто вопрос удобства, но и залог успешной работы с базой данных в будущем. Имена колонок должны быть понятными, логичными и легко воспринимаемыми как для разработчиков, так и для администраторов баз данных. Неверно выбранное название может стать причиной путаницы и ошибок, которые трудно будет отследить и исправить на поздних этапах работы с проектом.
Используйте описательные имена. Название колонки должно максимально точно отражать содержимое. Например, вместо абстрактного «value» лучше использовать «order_total» для колонки, содержащей общую сумму заказа. Это не только делает структуру данных понятной, но и упрощает задачу другим участникам проекта, которые могут не быть знакомы с конкретным контекстом.
Соблюдайте консистентность. Важно придерживаться единого подхода в именовании. Это касается как стиля написания (например, использование нижнего подчеркивания для разделения слов или в camelCase), так и выбора терминов. Например, если вы решили использовать «created_at» для даты создания в одном месте, не используйте «date_created» в другом. Это помогает избежать путаницы при работе с запросами и в дальнейшем облегчит масштабирование системы.
Избегайте использования зарезервированных слов. Некоторые слова, такие как «select», «order» или «group», имеют специальное значение в SQL. Их использование в качестве имен колонок может привести к ошибкам и трудности в написании запросов. Вместо этого лучше использовать синонимы или уточняющие добавления, например, «order_number» или «group_id».
Обратите внимание на длину и читаемость. Слишком длинные имена колонок усложняют работу с базой данных, а слишком короткие могут сделать их непонятными. Найдите баланс между краткостью и информативностью. Имена, которые слишком длинные или трудные для восприятия, могут быть источником ошибок в будущем, особенно когда данные активно используются в запросах или отчетах.
Как выбрать имя для колонки, отражающее её содержание?

При выборе имени для колонки важно точно отразить её роль в базе данных, чтобы облегчить понимание её содержания и назначения другим разработчикам или аналитикам. Правильное имя должно быть понятным и однозначным, избегая избыточных слов.
Во-первых, имя должно быть коротким, но информативным. Например, для колонки, содержащей данные о возрасте пользователя, имя типа «age» будет значительно проще и понятнее, чем «user_age_value». Чем короче и лаконичнее, тем легче воспринимать и использовать это имя в запросах.
Во-вторых, важно использовать правильную терминологию, соответствующую предметной области. Если колонка хранит дату рождения, используйте «birth_date», а не абстрактное «date1». Это поможет избежать путаницы, особенно если в базе данных есть несколько дат (например, дата регистрации или дата последнего визита).
В-третьих, избегайте использования сокращений, которые могут быть непонятными для других разработчиков. Например, «phone_num» или «usr_adrs» могут вызвать сомнения в значении. Используйте полные и общепринятые формы, такие как «phone_number» и «user_address».
Также учитывайте, что имена колонок должны быть логически структурированными и отражать иерархию данных. Если у вас есть колонка, содержащая город, и другая – страну, их имена могут быть «city» и «country», что ясно показывает их взаимосвязь и различие.
Наконец, старайтесь избегать слишком общих или многозначных названий, таких как «data» или «value». Эти имена не дают представления о содержимом колонки и могут привести к путанице, особенно в больших проектах с множеством таблиц.
Названия колонок: почему важно избегать пробелов и спецсимволов?
При выборе названия для колонки в SQL, важно учитывать, что пробелы и спецсимволы могут стать причиной ряда проблем, влияющих на работоспособность запросов и на удобство работы с базой данных в будущем. Рассмотрим основные причины, почему следует избегать таких символов.
1. Проблемы с синтаксисом SQL-запросов
В SQL пробелы и спецсимволы могут требовать дополнительных кавычек, чтобы правильно обработать имя колонки. Например, если название колонки включает пробелы, оно должно быть обрамлено в двойные кавычки или квадратные скобки, в зависимости от диалекта SQL. Это добавляет лишние сложности при написании запросов, увеличивает шанс на ошибку и снижает читаемость кода.
2. Совместимость с различными СУБД
Не все системы управления базами данных одинаково обрабатывают пробелы и спецсимволы в именах колонок. Например, MySQL требует использования обратных кавычек для выделения таких имен, в то время как PostgreSQL использует двойные кавычки. Если вы планируете переносить базу данных между разными СУБД, лучше избегать этих символов, чтобы избежать дополнительных затрат на адаптацию кода.
3. Совместимость с другими инструментами и языками
При интеграции с внешними системами или использованием колонок в API, имена с пробелами и спецсимволами могут привести к ошибкам при сериализации данных, обработке JSON или взаимодействии с другими языками программирования. Такие имена требуют дополнительной обработки, что может затруднить автоматизацию и повысить риск ошибок.
4. Уменьшение читаемости и удобства работы с кодом
Колонки с пробелами и спецсимволами затрудняют чтение кода. Названия становятся громоздкими, их сложнее воспринимать, особенно если они часто используются в запросах. К тому же использование таких имен требует лишних символов (кавычек), что делает запросы более тяжёлыми для восприятия и редактирования.
5. Риски при использовании индексов и создания связей
Имена с пробелами и спецсимволами могут повлиять на производительность запросов, особенно при создании индексов или внешних ключей. В некоторых случаях такие имена могут вызвать проблемы при попытке оптимизации запросов или использовании функций баз данных, таких как связывание таблиц или выполнение агрегатных операций.
Рекомендации:
- Используйте нижнее подчеркивание (_) вместо пробела для разделения слов в имени колонки.
- Ограничьтесь буквами, цифрами и нижними подчеркиваниями, избегая символов вроде $, @, !, &, и т.д.
- Для имен используйте однозначные и простые в понимании слова, избегая лишней сложности.
Следуя этим рекомендациям, вы обеспечите более устойчивую и удобную структуру базы данных, которая будет легче поддерживаться и интегрироваться с другими системами.
Использование сокращений в названиях колонок: когда это оправдано?
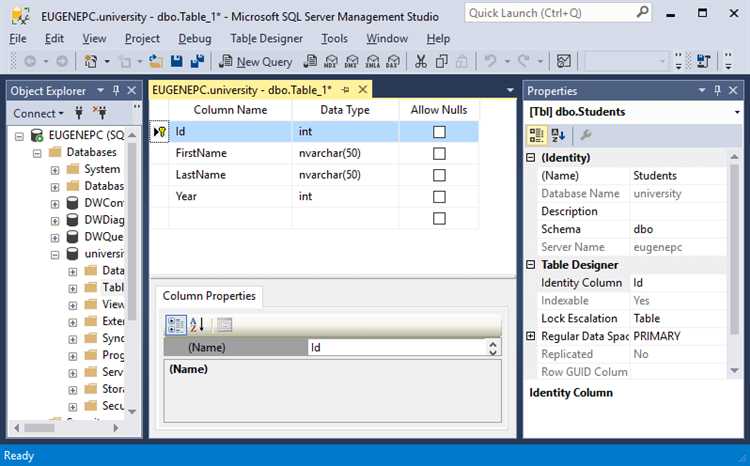
Сокращения в названиях колонок могут быть полезными, но они требуют осторожности. Когда сокращение не несет потери информации и легко воспринимается, оно может повысить читаемость и упростить запросы. Однако злоупотребление сокращениями снижает ясность и может затруднить понимание схемы базы данных для новых пользователей или разработчиков.
Сокращения оправданы, когда название колонки слишком длинное или содержит часто используемые слова, которые легко сокращаются без потери смысла. Например, поле, содержащее дату последнего обновления, можно назвать «upd_dt» вместо «last_updated_date». В таких случаях сокращения делают код чище и удобнее.
Однако важно помнить, что сокращения должны быть общеизвестными и интуитивно понятными. Использование редких или нестандартных сокращений может вызвать путаницу. Например, сокращение «qty» для количества товаров будет понятно большинству разработчиков, но если же используется сокращение, такое как «no», которое может означать как «number», так и «notification», это создаст двусмысленность.
Для обеспечения максимальной читаемости и удобства работы с базой данных, стоит ограничиваться стандартными и широко используемыми сокращениями, такими как «id» для идентификаторов, «qty» для количества, «dt» для даты. Когда же невозможно избежать неоднозначности, лучше оставить полные формы слов.
Как выбрать стиль именования для разных типов данных?
При создании колонок в SQL важно учитывать тип данных, так как это помогает избежать путаницы и повысить читаемость кода. Название колонки должно четко отражать, какие данные в ней содержатся. Для различных типов данных существуют свои рекомендации по именованию.
Для строковых данных (например, VARCHAR или TEXT) принято использовать имена, которые ясно указывают на текстовый контент. Имена должны быть понятными и легко интерпретируемыми. Например, вместо name лучше использовать first_name, last_name или email_address, что сразу указывает на содержание колонки. Также можно использовать префикс или суффикс для указания на единицу измерения, например, phone_number или postal_code.
Для числовых данных (например, INT, FLOAT, DECIMAL) стоит использовать имена, которые однозначно описывают, что именно измеряется. Названия, такие как price, quantity, total_amount или average_rating, сразу дают понять, что эти колонки содержат числовую информацию. Если значение может быть отрицательным или с плавающей точкой, важно в названии указать, что это за величина, например, balance или temperature_celsius.
Для временных данных (например, DATE, DATETIME) имена должны подчеркивать временную природу данных. Обычно используются такие названия, как created_at, updated_at, start_date, end_time. Это позволяет избежать путаницы, если в проекте имеются несколько временных меток для разных событий.
Для логических данных (например, BOOLEAN) следует использовать имена, которые точно отражают двоичный характер значений. Наиболее распространенные варианты: is_active, is_verified, has_access. Это дает четкое понимание того, что колонка хранит значение «истина/ложь».
При использовании сложных типов данных, таких как JSON или ARRAY, важно добавить в название, что колонка содержит коллекцию или структурированные данные. Например, user_preferences для JSON-данных или product_ids для массива. Это помогает избежать недоразумений и помогает понять, что данные в колонке требуют специальной обработки.
Также стоит избегать использования аббревиатур, если они не являются общеизвестными и могут сбивать с толку. Лучше использовать полные слова, чтобы название колонки было максимально понятно всем пользователям базы данных.
Подходы к именованию колонок в разных СУБД
Именование колонок в SQL может зависеть от особенностей и стандартов различных систем управления базами данных (СУБД). Рассмотрим, как различные СУБД влияют на выбор подхода к именованию столбцов.
В MySQL часто используется стиль с нижним подчеркиванием для разделения слов в имени колонки. Этот подход связан с рекомендациями самого разработчика MySQL, который считает такой стиль наиболее читаемым. Например, колонка для хранения даты рождения может быть названа как date_of_birth.
В PostgreSQL также применяется стиль с нижним подчеркиванием. Однако, стоит отметить, что PostgreSQL более гибок в отношении регистрозависимости имен. В отличие от MySQL, в PostgreSQL идентификаторы по умолчанию преобразуются в нижний регистр, что делает работу с именами колонок менее чувствительной к регистру. Например, CustomerName и customername будут восприняты как одно и то же имя.
В Oracle традиционно используется стиль с слиянием слов, когда каждое слово в имени начинается с заглавной буквы (CamelCase). Это отражает историю использования Oracle и требования к совместимости с другими языками программирования. Например, колонка с названием FirstName будет писаться с заглавной буквы в начале каждого слова.
В SQL Server применяется комбинированный подход, где используется как стиль с нижним подчеркиванием, так и PascalCase. Однако в последние годы наблюдается тенденция к переходу на использование стиля с нижним подчеркиванием, что позволяет улучшить совместимость с другими системами и стандартами. Например, колонка может быть названа как Employee_ID.
В SQLite, как и в MySQL, часто используется стиль с нижним подчеркиванием. SQLite ориентирован на простоту и переносимость, поэтому большинство практик в этой СУБД сходны с рекомендациями MySQL. Это делает использование нижнего подчеркивания стандартом для именования столбцов.
Важно отметить, что выбор подхода к именованию зависит не только от СУБД, но и от корпоративных стандартов. В большинстве случаев рекомендуется придерживаться единого стиля именования на протяжении всего проекта для улучшения читаемости и поддерживаемости кода.
Влияние именования колонок на читаемость SQL-запросов
Правильное именование колонок играет ключевую роль в восприятии SQL-запросов. Это влияет не только на удобство разработки, но и на поддерживаемость кода. Хорошо выбранное имя помогает быстро понять, что хранится в столбце, и как его можно использовать в запросах.
Основные принципы именования колонок:
- Ясность и однозначность – Имя должно точно отражать содержимое столбца. Например, если колонка хранит дату создания записи, то имя «created_at» будет гораздо понятнее, чем «date».
- Избегать аббревиатур – Использование аббревиатур может привести к путанице, особенно если они не являются общепринятыми. Например, «user_id» будет более понятно, чем «usr_id» или «u_id».
- Использование одного стиля именования – Нужно придерживаться единого стиля: либо использовать snake_case (например, «user_name»), либо camelCase (например, «userName»), чтобы избежать путаницы и повысить читаемость кода.
Примеры плохих и хороших имен колонок:
- Плохо: «col1», «col2», «field_1» – такие имена не дают никакой информации о содержимом столбца.
- Хорошо: «first_name», «last_name», «email_address» – сразу понятно, что содержится в каждом из этих столбцов.
Правильное именование также помогает при написании сложных запросов с множеством соединений. Например, если в запросе используются таблицы с похожими колонками, такие как «users.first_name» и «orders.first_name», хорошее имя столбца позволяет избежать путаницы и ошибочных ассоциаций.
Следует помнить, что названия колонок должны быть максимально информативными, но при этом не слишком длинными. Имена не должны быть сокращены до такой степени, чтобы потерять свою ясность. Например, «address» будет лучше, чем «addr» или «adrs».
Влияние плохих имен на читаемость:
- Увеличивает время на разбор запроса и исправление ошибок.
- Создает путаницу при добавлении новых столбцов в таблицы или в процессе работы с большим количеством данных.
- Трудности в поддержке кода при передаче его другим разработчикам.
В конечном итоге, хорошее именование колонок помогает улучшить не только читаемость SQL-запросов, но и повысить эффективность работы с базами данных в долгосрочной перспективе.
Как соблюдать согласованность в наименованиях колонок в проекте?
1. Выбор стиля именования
Основным решением будет выбор между snake_case и camelCase. В большинстве случаев для SQL проектов рекомендуется использовать snake_case, так как этот стиль более привычен для SQL-запросов и способствует лучшей читаемости, особенно в более длинных именах.
2. Последовательность и стандарт
После выбора стиля важно установить строгие правила, которым должны следовать все члены команды. Например, если выбрали стиль snake_case, то все имена колонок должны следовать этому правилу. Важно избегать отклонений, например, в виде смешанных стилей или случайных заглавных букв в именах.
3. Использование четких и однозначных имен
Имена колонок должны быть максимально понятными и описательными. Например, вместо использования общего термина date используйте более конкретное наименование, такое как created_at или updated_at, чтобы не возникло путаницы с другими датами в базе данных.
4. Избегание сокращений
Сокращения могут привести к недопониманию, особенно если проект развивается и новые разработчики подключаются к проекту. Рекомендуется использовать полные и понятные слова, чтобы избежать неясности.
5. Регулярный аудит и ревизия
Для поддержания согласованности важно проводить регулярные аудиты наименований колонок, особенно в больших проектах. Это поможет вовремя обнаружить и устранить несоответствия в наименованиях, которые могут возникнуть при добавлении новых данных или изменений в структуре базы данных.
Вопрос-ответ:
Как выбрать правильное название для колонки в SQL?
Правильное название для колонки в SQL должно быть понятным и логичным, чтобы облегчить восприятие структуры данных и её использование. Например, если колонка хранит информацию о дате рождения, название должно быть ясным, например «birth_date» или «dob» (от англ. date of birth). Названия лучше делать в едином стиле и избегать использования сокращений, если они не очевидны.
Какие принципы нужно учитывать при выборе названия для колонки в SQL?
Основные принципы при выборе названия колонки — ясность, читаемость и последовательность. Название должно отражать содержание данных в колонке, например, если колонка хранит цены, она может называться «price» или «amount». Также важно придерживаться единого стиля в базе данных: использовать только нижний регистр, если выбрали такую практику, или избегать пробелов, заменяя их подчеркиваниями.
Почему важно правильно называть колонки в SQL?
Правильные названия колонок помогают избежать путаницы в будущем и облегчить понимание структуры базы данных. Это особенно важно, если с базой работает несколько человек. Четкие и логичные названия ускоряют процесс разработки и минимизируют количество ошибок, связанных с неправильным использованием данных.
Как выбрать название для колонки с числовыми данными в SQL?
Название колонки с числовыми данными должно быть простым и точным, чтобы сразу было понятно, что именно измеряется или хранится в этой колонке. Например, если колонка содержит количество товаров на складе, её можно назвать «stock_count». Если же это сумма транзакций, то лучше использовать «transaction_total» или «amount_spent».
Какие ошибки нужно избегать при выборе названия колонки в SQL?
При выборе названия для колонки важно избегать слишком общих или абстрактных названий, таких как «data» или «info», так как они не дают чёткого представления о содержимом. Также стоит избегать использования специальных символов, пробелов и чрезмерных сокращений, которые могут усложнить работу с базой данных, особенно если с ней будут работать другие разработчики.