При работе с базами данных важно избегать дублирования данных в результатах запросов. Повторяющиеся значения могут не только искажать информацию, но и приводить к неоптимальному использованию ресурсов, таким как процессорное время и память. В SQL есть несколько эффективных методов для предотвращения таких ситуаций, и понимание их помогает повысить производительность запросов.
Одним из основных инструментов для исключения повторов является ключевое слово DISTINCT. Оно позволяет выбрать только уникальные строки из таблицы. Например, запрос SELECT DISTINCT column_name FROM table_name; вернёт только те строки, где значения в столбце column_name не повторяются. Однако стоит помнить, что использование DISTINCT может быть дорогостоящим с точки зрения производительности, особенно в больших таблицах. Поэтому его следует применять с осторожностью.
Кроме того, в некоторых случаях может быть полезно воспользоваться функциями агрегации, такими как COUNT(), SUM(), MAX() и MIN(), для обработки данных без дублирования. Эти функции позволяют агрегировать данные по уникальным значениям и, таким образом, избегать повторений в итоговых результатах.
Также, для предотвращения повторных значений в процессе выборки, можно применять фильтрацию на уровне JOIN операций. Если необходимо соединить несколько таблиц, важно грамотно выбирать тип соединения, чтобы избежать появления лишних строк. Например, использование INNER JOIN с правильными условиями соединения исключит строки, которые не соответствуют условиям.
Использование DISTINCT для удаления дублирующихся строк
Оператор DISTINCT в SQL используется для фильтрации повторяющихся строк из результатов запроса. Он гарантирует, что каждая строка в результирующем наборе будет уникальной по комбинации значений всех колонок, указанных в SELECT.
Применение DISTINCT эффективно в случаях, когда важно получить только уникальные значения из одного или нескольких столбцов. Например, если в таблице сотрудников хранятся записи с повторяющимися значениями по городу проживания, можно использовать DISTINCT для выборки уникальных городов:
SELECT DISTINCT city FROM employees;
Такой запрос вернет только уникальные города, без дублирующихся записей.
Однако стоит учитывать, что использование DISTINCT может значительно повлиять на производительность при работе с большими таблицами, так как требует дополнительных вычислительных ресурсов для обработки и удаления дубликатов. В некоторых случаях более оптимальным решением может быть использование группировки (GROUP BY), особенно когда нужно провести агрегацию данных, например, подсчитать количество записей по каждому уникальному значению:
SELECT city, COUNT(*) FROM employees GROUP BY city;
При этом важно помнить, что DISTINCT будет работать на уровне всей строки, то есть если хотя бы одно из значений в строке отличается, то такая строка будет считаться уникальной. Это может повлиять на результаты запроса, если необходимо учитывать только отдельные столбцы.
Для более сложных запросов с несколькими условиями лучше использовать DISTINCT в сочетании с другими SQL-операторами, такими как JOIN или WHERE, чтобы минимизировать количество избыточных данных, которые могут попасть в итоговый набор. Например:
SELECT DISTINCT city FROM employees WHERE department = 'Sales';
Этот запрос вернет уникальные города только для сотрудников из отдела продаж.
Таким образом, DISTINCT – это мощный инструмент для исключения дублирующих данных в запросах, но его использование требует внимательного подхода, особенно при работе с большими объемами информации.
Как применить GROUP BY для группировки данных без повторений
Оператор GROUP BY в SQL позволяет агрегировать строки данных, приводя их к уникальным значениям по выбранным столбцам. Чтобы избежать повторений, важно правильно выбирать столбцы для группировки и применять функции агрегирования, такие как COUNT(), SUM(), AVG(), которые обеспечивают обработку данных без избыточных значений.
Основной принцип работы с GROUP BY заключается в том, чтобы сгруппировать записи по значениям в одном или нескольких столбцах, тем самым исключая дублирование данных. Например, если у вас есть таблица с заказами, вы можете сгруппировать данные по клиентам, чтобы увидеть количество заказов, сделанных каждым клиентом, без повторяющихся строк.
Пример SQL запроса, который группирует данные по клиентам, при этом исключает повторения:
SELECT customer_id, COUNT(order_id) FROM orders GROUP BY customer_id;
Этот запрос даст вам уникальные идентификаторы клиентов с количеством заказов от каждого. Важно отметить, что в запросах с GROUP BY возвращаются только те поля, которые участвуют в группировке или агрегируются. Это автоматически исключает повторение данных, так как строки, имеющие одинаковые значения в группируемых столбцах, комбинируются в одну.
Для более сложных запросов можно использовать несколько столбцов для группировки. В таком случае SQL будет собирать уникальные комбинации значений в этих столбцах, не дублируя данные:
SELECT customer_id, product_id, COUNT(order_id) FROM orders GROUP BY customer_id, product_id;
Этот запрос поможет вам узнать, сколько заказов сделано каждым клиентом для каждого товара. Группировка по нескольким столбцам позволяет исключить повторы, так как создаются уникальные комбинации значений.
Использование GROUP BY позволяет эффективно управлять данными и получать точную информацию без дублирования, но важно правильно выбирать поля для группировки и применять нужные функции для агрегирования, чтобы результат был максимально информативным.
Использование оконных функций для выявления уникальных записей
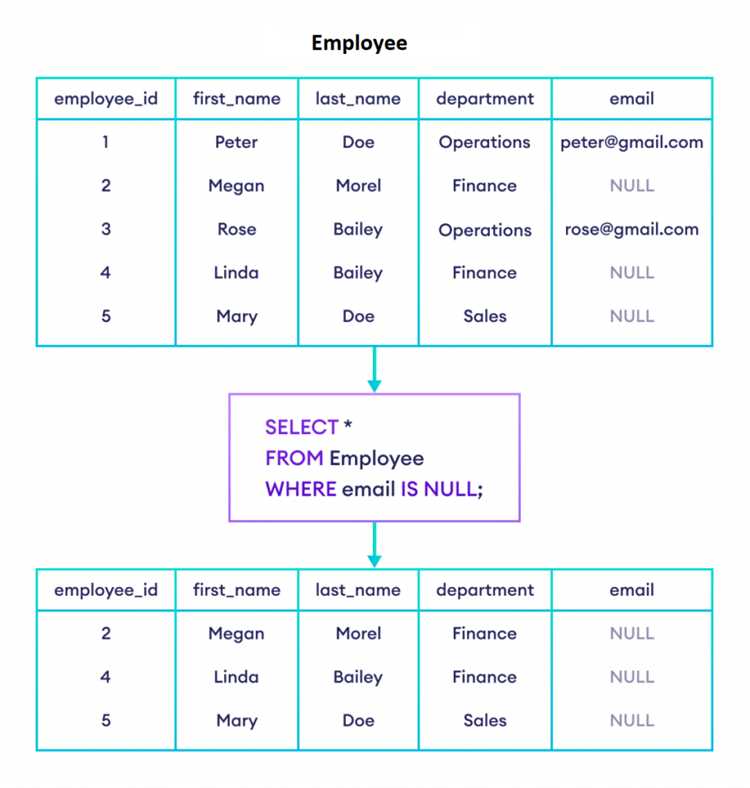
Оконные функции в SQL позволяют выполнять вычисления в пределах набора строк, которые связаны с текущей строкой, без необходимости агрегации данных. Это делает их идеальными для выявления уникальных записей в случае сложных запросов, когда необходимо учитывать контекст, а не просто фильтровать дубликаты.
Основное преимущество оконных функций в поиске уникальных записей заключается в том, что они позволяют работать с каждым элементом выборки, учитывая его положение в контексте всей выборки. Например, используя функцию ROW_NUMBER(), можно легко определить первую или последнюю уникальную запись в группе, что часто используется для устранения дубликатов без использования дополнительных подзапросов или агрегаций.
Пример запроса, который использует ROW_NUMBER() для выявления уникальных записей по комбинации двух столбцов:
WITH ranked_data AS ( SELECT id, name, ROW_NUMBER() OVER (PARTITION BY name ORDER BY id) AS rn FROM users ) SELECT id, name FROM ranked_data WHERE rn = 1;
В данном примере для каждого имени генерируется номер строки (rn), который повторяется для одинаковых значений в столбце name. Выборка ограничена строками, где rn = 1, что позволяет получить только уникальные имена с минимальным id. Это позволяет избежать дублирования данных, не прибегая к агрегации.
Также полезной может быть функция DENSE_RANK(), которая, в отличие от ROW_NUMBER(), не пропускает номера строк при наличии дублирующихся значений. Это полезно, если необходимо сохранить все уникальные записи, но с их порядковыми номерами.
Еще одним вариантом является использование функции COUNT() с оконным фреймом. В этом случае можно подсчитать количество появлений каждого значения в пределах определенной группы, что позволяет фильтровать записи, которые встречаются только один раз:
SELECT id, name FROM ( SELECT id, name, COUNT(*) OVER (PARTITION BY name) AS name_count FROM users ) AS counts WHERE name_count = 1;
Этот запрос вернет только те записи, где имя встречается в таблице всего один раз, эффективно устраняя повторяющиеся значения.
Оконные функции дают широкие возможности для работы с уникальными записями в SQL, позволяя точно настроить выборку данных, не требуя сложных агрегаций или дополнительных подзапросов. При правильном применении они значительно упрощают работу с большими наборами данных и обеспечивают гибкость в их обработке.
Оптимизация индексов для предотвращения дублирования данных

Для эффективного предотвращения дублирования данных в SQL запросах важно правильно настроить индексы. В первую очередь, индексы должны быть созданы на уникальных столбцах или на группах столбцов, которые гарантируют уникальность значений. Это минимизирует риск вставки повторяющихся записей в базу данных.
Первое, на что стоит обратить внимание, – это использование уникальных индексов. Они не только ускоряют поиск, но и автоматически предотвращают добавление дублирующих значений. Пример: для столбца email, который должен быть уникальным в системе, необходимо создать уникальный индекс, что исключит возможные повторения.
Во-вторых, важно правильно выбирать составные индексы. Индекс, состоящий из нескольких столбцов, может предотвратить дублирование данных, если эти столбцы в совокупности определяют уникальность записи. Например, комбинация user_id и transaction_date может быть использована для предотвращения повторных транзакций того же пользователя в один день.
Однако создание индекса на слишком большом количестве столбцов может снизить производительность. Поэтому следует избегать избыточных индексов. Вместо этого лучше создавать индексы только на тех столбцах, которые часто участвуют в запросах с условиями WHERE и JOIN.
Важной рекомендацией является регулярный анализ индексов. С течением времени, индексы могут становиться менее эффективными, особенно если структура данных изменяется. Использование инструмента анализа производительности (например, EXPLAIN в PostgreSQL) позволяет выявить неоптимальные индексы и исключить дублирование данных.
Еще одной стратегией является использование триггеров, которые проверяют наличие дублирующих записей перед вставкой данных. Однако такой подход требует дополнительных вычислительных ресурсов, и его стоит применять только в тех случаях, когда оптимизация индексов не обеспечивает необходимого результата.
Как использовать подзапросы для исключения повторяющихся значений

Один из способов использования подзапросов для исключения дубликатов – это фильтрация с помощью оператора NOT IN или NOT EXISTS. Эти операторы позволяют исключить строки, которые уже присутствуют в результате подзапроса, предотвращая повторение значений.
Пример использования подзапроса с оператором NOT IN:
SELECT id, name
FROM employees
WHERE id NOT IN (SELECT employee_id FROM contracts WHERE status = 'terminated');В этом запросе основная выборка employees исключает сотрудников, которые имеют записи в таблице contracts с состоянием «terminated». Подзапрос возвращает список employee_id, которые затем используются для фильтрации основного запроса.
Другим подходом является использование NOT EXISTS, который в некоторых случаях может работать быстрее, особенно при больших объемах данных, так как избегает выполнения подзапроса для каждой строки в основной таблице:
SELECT id, name
FROM employees e
WHERE NOT EXISTS (
SELECT 1
FROM contracts c
WHERE c.employee_id = e.id AND c.status = 'terminated'
);Этот запрос аналогичен предыдущему, но NOT EXISTS проверяет существование строки в подзапросе для каждого сотрудника. Если для сотрудника нет записи в таблице contracts с состоянием «terminated», его данные попадают в результат.
Использование подзапросов также помогает в случае, когда необходимо исключить дубликаты в нескольких колонках. Например, можно использовать подзапрос для извлечения уникальных значений, которые затем будут фильтровать основной запрос:
SELECT name
FROM products
WHERE category_id NOT IN (
SELECT category_id
FROM categories
WHERE active = 0
);Здесь подзапрос исключает категории товаров, которые имеют статус «неактивен». В результате выбираются только те товары, которые принадлежат активным категориям.
Подзапросы не всегда являются единственным способом решения задачи исключения повторов. Однако в сложных случаях с несколькими связями и дополнительными условиями они могут значительно улучшить читаемость запроса и ускорить его выполнение. Главное – правильно выбирать подходящий тип подзапроса, ориентируясь на структуру данных и требования к производительности.
Роль JOIN и ON для правильного связывания данных без повторов
Для предотвращения появления повторяющихся значений при использовании SQL-запросов, важно правильно настроить соединения между таблицами. Ключевую роль в этом процессе играют операторы JOIN и ON.
Основная задача при использовании этих операторов – четко установить, как данные из разных таблиц должны быть связаны. Неправильная настройка связей может привести к дублированию строк, что исказит результаты запроса.
Типы JOIN и их влияние на повторения
В зависимости от того, какой тип соединения используется, результаты запроса могут значительно отличаться. Рассмотрим основные типы JOIN:
INNER JOIN– соединяет только те строки, которые имеют соответствие в обеих таблицах. Это минимизирует риск появления дублированных строк, так как исключаются записи без совпадений.LEFT JOIN(илиLEFT OUTER JOIN) – включает все строки из левой таблицы, даже если для них нет соответствующих строк в правой таблице. При этом, если в правой таблице нет совпадений, будут добавлены пустые значения (NULL), что не всегда приводит к повторению данных.RIGHT JOIN(илиRIGHT OUTER JOIN) – аналогичен LEFT JOIN, но включает все строки из правой таблицы. Этот тип соединения может привести к появлению дублирующихся значений, если в левой таблице несколько строк соответствуют одной строке в правой.FULL JOIN(илиFULL OUTER JOIN) – объединяет все строки из обеих таблиц, включая NULL для отсутствующих данных. Такой тип соединения может привести к значительному увеличению количества строк и повторений, если обе таблицы содержат данные с частичными совпадениями.
Оптимизация связей с помощью ON
После выбора типа JOIN, важно правильно настроить условие связывания с помощью оператора ON. В большинстве случаев, дублирование значений происходит из-за того, что условие связывания слишком общее или некорректно отражает реальную логику данных.
- Убедитесь, что условия в
ONчетко определяют уникальность связей. Например, использование нескольких столбцов для связывания таблиц может значительно уменьшить вероятность повторений. - Используйте фильтрацию данных через
WHEREдля исключения ненужных записей. Это поможет минимизировать объем возвращаемых данных и избежать случайных дублированных строк. - При соединении таблиц с одним столбцом, который может быть общим для множества строк (например, внешний ключ), добавление дополнительных условий может значительно улучшить качество результата и избежать повторов.
Практические рекомендации
- При использовании
JOINвсегда проверяйте, что ваша связь логична и не приводит к неожиданным дублированиям. - Для связи по нескольким столбцам всегда уточняйте это в условии
ON, чтобы избежать неправильных пересечений данных. - Если необходимо соединить таблицы с большим объемом данных, рассмотрите возможность использования агрегатных функций для объединения и группировки данных, что позволит избежать дублирования.
Правильное использование JOIN и ON позволяет не только избежать повторений, но и эффективно организовать работу с большими объемами данных, минимизируя избыточные записи в итоговом наборе.
Вопрос-ответ:
Какие причины могут привести к повторяющимся значениям в SQL запросах?
Повторяющиеся значения могут возникать по нескольким причинам. Например, это может быть связано с отсутствием уникальных ограничений на столбцы, неправильной настройкой связей между таблицами или неверным использованием операторов JOIN. Также ошибки могут возникать при неправильной фильтрации данных, когда условия в WHERE не исключают дублирующие строки.
Как можно избежать появления дублированных данных при выполнении SQL запроса?
Для предотвращения повторяющихся данных можно использовать оператор DISTINCT, который исключает дубли в результирующем наборе. Однако это решение не всегда подходит, если нужно учитывать все строки, включая повторяющиеся. В таком случае можно пересмотреть структуру базы данных, например, создать уникальные индексы или использовать ограничения на уникальность данных в таблицах.
Когда лучше использовать GROUP BY, чтобы избежать повторяющихся данных?
Оператор GROUP BY полезен, когда необходимо сгруппировать строки по определённому критерию и агрегировать данные. Это поможет избежать повторяющихся строк в результатах запроса. Например, при подсчёте суммы или среднего значения для каждой группы данных, можно сгруппировать данные по уникальному идентификатору, что исключит повторения.
Может ли использование JOIN привести к повторению данных в SQL запросах?
Да, использование операторов JOIN может привести к повторяющимся данным, если они не настроены должным образом. Например, при соединении двух таблиц по полям, которые могут содержать несколько совпадающих значений, результат будет включать повторяющиеся строки. Чтобы избежать этого, можно уточнить условия соединения или использовать ключи, которые гарантируют уникальность связей.
Как гарантировать уникальность данных в SQL запросах при работе с несколькими таблицами?
Чтобы гарантировать уникальность данных при работе с несколькими таблицами, важно правильно настроить соединения между таблицами, используя подходящие ключи (например, первичные и внешние ключи). Также можно использовать операторы DISTINCT или агрегатные функции с GROUP BY. Важно следить за тем, чтобы данные в таблицах были корректно нормализованы и не содержали избыточных или повторяющихся значений.