Одной из распространенных задач при работе с базами данных является объединение нескольких строк в одну. Это может быть полезно при агрегации данных, преобразовании строковых значений или подготовке отчетности. В SQL существует несколько способов решения этой задачи, каждый из которых имеет свои особенности и области применения. Рассмотрим, как эффективно объединять строки в зависимости от ситуации.
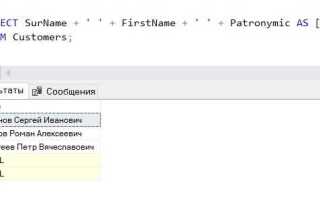
Функция GROUP_CONCAT – это один из самых удобных инструментов для агрегации строк в MySQL. Она позволяет объединять все значения в одну строку, разделяя их заданным символом. Например, если нужно объединить все имена сотрудников в один список, разделенный запятой, можно использовать следующий запрос:
SELECT GROUP_CONCAT(name SEPARATOR ', ') FROM employees;В PostgreSQL аналогичной функцией является string_agg, которая работает по тому же принципу, но имеет немного другую синтаксическую структуру:
SELECT string_agg(name, ', ') FROM employees;Для Microsoft SQL Server также существует метод, который позволяет объединять строки с использованием FOR XML PATH. Это решение часто используется в старых версиях SQL Server, так как в более новых версиях добавлена функция STRING_AGG, которая значительно упрощает процесс:
SELECT STRING_AGG(name, ', ') FROM employees;Важно помнить, что при объединении строк могут возникать проблемы с производительностью, особенно при работе с большими объемами данных. В таких случаях следует внимательно выбирать подходящий метод и оптимизировать запросы.
Использование функции GROUP_CONCAT в MySQL для объединения строк
Функция GROUP_CONCAT в MySQL позволяет объединить значения нескольких строк в одну строку. Это полезно при анализе данных, когда нужно сгруппировать результаты по какому-либо признаку и представить их в виде единой строки. Рассмотрим, как эффективно использовать эту функцию.
GROUP_CONCAT работает внутри агрегатных функций GROUP BY, и ее синтаксис следующий:
GROUP_CONCAT(expression [ORDER BY ...] [SEPARATOR 'separator'])
- expression – выражение, значения которого будут объединяться.
- ORDER BY – не обязательный параметр, позволяющий задать порядок объединяемых значений.
- SEPARATOR – разделитель, который будет использоваться для разделения строк (по умолчанию – запятая).
Пример использования GROUP_CONCAT:
SELECT department, GROUP_CONCAT(employee_name) AS employees FROM employees GROUP BY department;
В этом примере объединяются имена сотрудников по отделам. Результат будет содержать один столбец с именами сотрудников, разделенными запятой для каждого отдела.
Настройка разделителей
SELECT department, GROUP_CONCAT(employee_name SEPARATOR ' ') AS employees FROM employees GROUP BY department;
Теперь имена сотрудников будут разделяться пробелом, а не запятой.
Использование ORDER BY

Для сортировки значений перед их объединением можно использовать параметр ORDER BY. Например, чтобы получить список сотрудников в алфавитном порядке, можно применить следующее:
SELECT department, GROUP_CONCAT(employee_name ORDER BY employee_name) AS employees FROM employees GROUP BY department;
Это поможет привести результаты в нужный порядок перед объединением.
Ограничения функции GROUP_CONCAT
Функция GROUP_CONCAT имеет ограничения по длине результирующей строки. По умолчанию максимальная длина строки ограничена 1024 байтами, но это значение можно увеличить с помощью параметра group_concat_max_len. Для этого нужно выполнить следующую команду:
SET SESSION group_concat_max_len = 10000;
Если длина объединенной строки превышает установленные лимиты, данные будут обрезаны.
Использование GROUP_CONCAT с различными типами данных
Функция GROUP_CONCAT может работать с любыми типами данных, поддерживаемыми MySQL. Однако стоит помнить, что при работе с числовыми значениями или датами они будут автоматически преобразованы в строковый формат.
Для работы с датами можно использовать функцию DATE_FORMAT, чтобы привести их к удобному виду:
SELECT department, GROUP_CONCAT(DATE_FORMAT(start_date, '%Y-%m-%d') ORDER BY start_date) AS start_dates FROM employees GROUP BY department;
Такой подход позволяет объединять даты в нужном формате, упрощая их анализ.
Заключение
Применение функции STRING_AGG в PostgreSQL для склеивания данных
Функция STRING_AGG в PostgreSQL используется для объединения значений из нескольких строк в одну. Это особенно полезно при необходимости создания списка значений или агрегирования данных в текстовый формат, что сокращает количество строк в результатах запроса.
Основной синтаксис функции выглядит следующим образом:
STRING_AGG(expression, delimiter) Где:
expression– столбец или выражение, значения которого нужно объединить;delimiter– разделитель, который будет вставлен между значениями.
Пример использования:
SELECT STRING_AGG(name, ', ')
FROM employees;
Этот запрос объединяет все значения из столбца name в одну строку, разделяя их запятой и пробелом.
В PostgreSQL STRING_AGG позволяет также использовать ORDER BY внутри агрегатной функции для сортировки значений перед объединением. Например:
SELECT STRING_AGG(name, ', ' ORDER BY name)
FROM employees;
Этот запрос создаст строку из имен сотрудников, отсортированных в алфавитном порядке.
Одним из преимуществ использования STRING_AGG является возможность работы с большими объемами данных. Функция оптимизирована для эффективной работы с большими наборами строк, что делает её отличным выбором для агрегации текстовых данных.
Важное замечание: если в результате объединения строк возникает слишком длинная строка, PostgreSQL может вернуть ошибку, если длина строки превышает максимально допустимый размер. В таких случаях рекомендуется использовать тип данных TEXT вместо VARCHAR.
Пример с ограничением длины строки:
SELECT STRING_AGG(name, ', ' ORDER BY name)
FROM employees
WHERE LENGTH(name) < 1000;
Таким образом, STRING_AGG – это мощный инструмент для эффективного агрегационного объединения строк в PostgreSQL, который можно настроить под различные нужды в запросах.
Объединение строк с помощью оператора FOR XML PATH в SQL Server

В SQL Server оператор FOR XML PATH используется для объединения значений нескольких строк в одну строку. Это особенно полезно, когда нужно собрать данные из нескольких записей в одно поле, например, для формирования списка значений или создания строки с разделителями.
Чтобы использовать FOR XML PATH для объединения строк, необходимо выполнить запрос, который выбирает данные, а затем применяет этот оператор для агрегирования строк в одну. Пример базового синтаксиса:
SELECT STUFF((
SELECT ',' + column_name
FROM table_name
FOR XML PATH('')
), 1, 1, '') AS combined_string;
Здесь:
- SELECT – используется для выборки данных из таблицы.
- STUFF – используется для удаления первого символа (например, запятой), которая появляется из-за объединения строк.
В примере выше сначала объединяются значения столбца column_name из таблицы table_name, и все значения разделяются запятой. Затем функция STUFF убирает ведущую запятую, которая появляется из-за первого объединенного значения.
Для разделителей можно использовать любой символ, например, точку с запятой, пробел или даже строку. Для этого достаточно заменить символ в выражении ',' на нужный.
Пример для объединения с использованием другого разделителя:
SELECT STUFF((
SELECT '; ' + column_name
FROM table_name
FOR XML PATH('')
), 1, 2, '') AS combined_string;
Использование FOR XML PATH также имеет важные нюансы, например, если данные содержат специальные символы XML (такие как <, >, &, и т. д.), они будут автоматически экранированы. Это может потребовать дополнительных манипуляций, чтобы избежать нежелательного форматирования.
Важно помнить, что использование FOR XML PATH работает только в том случае, если результат можно представить в виде XML. В некоторых случаях, когда требуется более сложное преобразование данных, могут понадобиться дополнительные функции или методы агрегации.
Как использовать CONCAT и CONCAT_WS для объединения строк в SQL
Функции CONCAT и CONCAT_WS в SQL предназначены для объединения строк в одно значение, но имеют различия в синтаксисе и использовании. Понимание этих функций помогает эффективно работать с текстовыми данными в запросах.
Функция CONCAT объединяет два или более выражений в одну строку. Если одно из выражений является NULL, оно игнорируется, и результатом будет строка, состоящая только из ненулевых значений. Пример использования:
SELECT CONCAT('Привет, ', 'мир!');Этот запрос вернет строку: 'Привет, мир!'. Важно, что если одно из значений было бы NULL, результат не стал бы NULL. Например:
SELECT CONCAT('Привет, ', NULL, 'мир!');Этот запрос вернет строку: 'Привет, мир!'. Это поведение особенно полезно при работе с данными, где некоторые значения могут быть пустыми.
Функция CONCAT_WS имеет схожий синтаксис, но отличается тем, что позволяет добавлять разделитель между объединяемыми строками. В качестве первого параметра указывается разделитель, который будет вставлен между всеми объединяемыми строками. Например:
SELECT CONCAT_WS(', ', 'яблоки', 'бананы', 'груши');Результат выполнения запроса: 'яблоки, бананы, груши'. В отличие от CONCAT, здесь можно явно указать разделитель, который будет использован между всеми строками. Если одно из значений равно NULL, оно игнорируется, как и в CONCAT.
Пример с NULL:
SELECT CONCAT_WS(', ', 'яблоки', NULL, 'груши');Этот запрос вернет строку: 'яблоки, груши'. Использование CONCAT_WS удобно для создания строк с разделителями, например, при формировании списков или адресов, где разделение данных играет важную роль.
В результате, CONCAT лучше использовать, когда нужно просто соединить строки, а CONCAT_WS – когда необходима настройка разделителей между значениями. Обе функции позволяют обрабатывать данные без риска получения значения NULL в результате, если хотя бы одно из объединяемых выражений отсутствует.
Объединение строк с учётом разделителей в различных СУБД
В PostgreSQL для объединения строк с разделителями используется функция string_agg(). Этот метод позволяет легко указать разделитель между значениями. Например, для объединения значений столбца с разделением запятой запрос будет выглядеть так:
SELECT string_agg(column_name, ', ') FROM table_name;
Для MySQL задача объединения строк с разделителем решается с помощью функции GROUP_CONCAT(). Здесь также можно указать разделитель, используя параметр SEPARATOR. Пример:
SELECT GROUP_CONCAT(column_name SEPARATOR ', ') FROM table_name;
Важно учитывать, что в MySQL по умолчанию разделитель является запятой, и если не указать SEPARATOR, то разделитель будет использоваться стандартный. Кроме того, стоит помнить, что в MySQL по умолчанию ограничение на длину строки, возвращаемой GROUP_CONCAT(), составляет 1024 символа, и это может повлиять на результаты при обработке больших наборов данных.
В Microsoft SQL Server для объединения строк с разделителями используется функция STRING_AGG(), которая была введена в версии SQL Server 2017. Пример использования:
SELECT STRING_AGG(column_name, ', ') FROM table_name;
Для более старых версий SQL Server, где функция STRING_AGG() недоступна, можно воспользоваться методами с использованием XML. Например:
SELECT column_name = STUFF((SELECT ', ' + column_name FROM table_name FOR XML PATH('')), 1, 2, '');
В Oracle для объединения строк с учётом разделителей применяется функция LISTAGG(). Пример использования в запросе:
SELECT LISTAGG(column_name, ', ') WITHIN GROUP (ORDER BY column_name) FROM table_name;
Обратите внимание, что в Oracle функция LISTAGG() имеет ограничение по длине строки, которое составляет 4000 символов. В случае превышения этого лимита будет вызвана ошибка. Для обхода этой проблемы можно использовать методы разбивки данных на более мелкие части или использовать другие подходы в зависимости от специфики задачи.
При выборе подходящей функции для объединения строк следует учитывать не только синтаксис, но и возможные ограничения и особенности работы с данными в каждой конкретной СУБД. Важно понимать, что производительность может варьироваться в зависимости от используемого метода, особенно при обработке больших объемов данных.
Работа с NULL значениями при объединении строк в SQL
При объединении строк в SQL, особенно с использованием оператора CONCAT() или операторов || (в зависимости от СУБД), необходимо учитывать влияние значений NULL. В стандартном поведении SQL, любая операция с NULL возвращает результат NULL, что может привести к нежелательным результатам при объединении строк.
Для корректной работы с NULL значениями существует несколько подходов. Один из них – использование функции COALESCE(). Эта функция позволяет заменять NULL значением по умолчанию. Пример:
SELECT CONCAT(COALESCE(column1, ''), column2) FROM table;
В данном примере, если column1 содержит NULL, то COALESCE заменяет его на пустую строку, обеспечивая корректное объединение строк.
Для замены NULL на конкретное значение можно использовать также IFNULL() (MySQL) или NVL() (Oracle). Это позволяет настраивать обработку NULL в зависимости от требований бизнес-логики:
SELECT CONCAT(IFNULL(column1, 'Нет данных'), column2) FROM table;
Важно понимать, что при использовании этих функций поведение будет зависеть от конкретной СУБД. В некоторых случаях может потребоваться настройка параметров соединения или выполнения запросов для более гибкой обработки NULL значений.
Также стоит помнить, что при объединении строк с использованием || в некоторых СУБД результат может быть NULL даже если только один из элементов является NULL. В таких случаях следует применять функции, обеспечивающие замену NULL на значения по умолчанию.
Еще одним полезным инструментом является использование выражений CASE, что позволяет детально настроить поведение с NULL в условиях более сложных бизнес-правил:
SELECT CASE WHEN column1 IS NULL THEN 'Нет данных' ELSE column1 END || column2 FROM table;
Это особенно актуально при сложных запросах, где необходимо контролировать каждое значение перед его объединением. Так можно избежать неявных ошибок и гарантировать предсказуемость результатов.
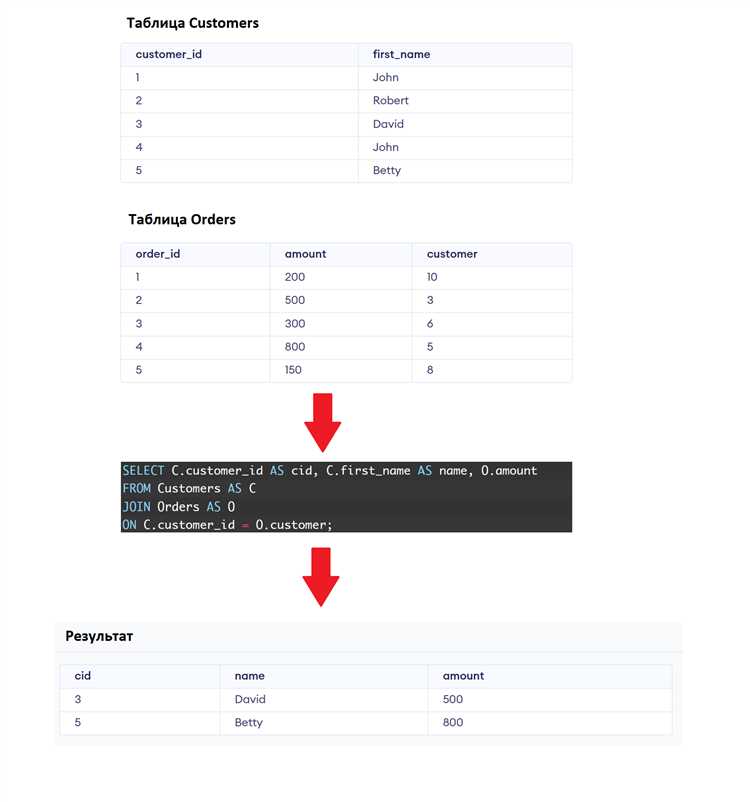
Пример использования объединения строк в подзапросах
В SQL объединение строк в подзапросах часто используется для агрегирования данных или формирования уникальных строковых значений из нескольких источников. Рассмотрим пример, где необходимо объединить имена сотрудников в одной строке для каждой группы, используя подзапрос.
Предположим, что у нас есть таблица employees, в которой хранятся данные о сотрудниках, и нам нужно вывести список всех сотрудников, работающих в одной команде, в виде одной строки. В SQL можно использовать функцию GROUP_CONCAT (для MySQL) или аналогичные функции в других СУБД, чтобы объединить строки.
Пример запроса для MySQL:
SELECT team_id,
(SELECT GROUP_CONCAT(employee_name SEPARATOR ', ')
FROM employees
WHERE team_id = teams.team_id) AS team_members
FROM teams;
Здесь мы используем подзапрос, который для каждой команды извлекает всех сотрудников с идентификатором team_id и объединяет их имена в одну строку, разделяя запятой. Внешний запрос выбирает все команды из таблицы teams и для каждой команды выполняет подзапрос.
Этот метод эффективно агрегирует данные, но важно помнить, что при использовании GROUP_CONCAT или аналогичных функций нужно учитывать ограничения на длину результата, так как в некоторых системах могут быть установлены ограничения на количество символов в объединенной строке.
Аналогичные техники объединения строк можно применять и в других СУБД, таких как PostgreSQL с функцией STRING_AGG или SQL Server с использованием FOR XML PATH.
Оптимизация запросов с объединением строк для больших наборов данных
Объединение строк в SQL при работе с большими наборами данных может существенно повлиять на производительность запроса. Применение неправильных методов для таких операций может привести к значительным задержкам, особенно если используется большое количество строк. Для оптимизации запросов необходимо учитывать несколько ключевых аспектов.
Первое, что стоит учитывать, это выбор функции объединения строк. В разных СУБД существуют различные методы для этого. В PostgreSQL рекомендуется использовать функцию string_agg(), которая позволяет объединять строки с разделителями в одну строку, минимизируя количество проходов по данным. В MySQL и MariaDB для аналогичной задачи можно использовать функцию GROUP_CONCAT(), но следует быть внимательным к ограничению длины результата, которое по умолчанию составляет 1024 символа. В случае, если необходимо обработать большие объемы данных, можно увеличить это ограничение с помощью параметра group_concat_max_len.
Для повышения эффективности выполнения запросов важно оптимизировать индексацию. Использование индексов на колонках, участвующих в операции объединения, позволяет ускорить извлечение данных, что особенно важно при работе с большими таблицами. Индексы могут снизить время выполнения запроса, если они правильно подобраны для условий фильтрации или группировки.
Также важно учитывать использование оконных функций. В некоторых случаях можно использовать оконные функции для предварительной агрегации данных, что может сократить количество строк, передаваемых в операцию объединения. Это особенно эффективно, если операция объединения осуществляется по результатам предварительных вычислений.
Немаловажным аспектом является применение правильной структуры данных. Например, использование таблиц с нормализованной схемой позволяет уменьшить избыточность данных и снизить нагрузку на сервер при объединении строк. Для больших наборов данных следует также избегать операций, которые приводят к дублированию данных, например, избыточных соединений (JOIN), особенно если они не оптимизированы.
Для работы с большими объемами данных рекомендуется разбивать запросы на несколько частей, используя пагинацию или ограничение выборки с помощью LIMIT. Это позволяет избежать обработки слишком большого количества данных за один раз и ускоряет выполнение запросов. Важно также отслеживать производительность с помощью инструментов профилирования запросов, чтобы точно выявить узкие места в выполнении операций объединения строк.
Когда необходимо объединить строки из нескольких таблиц, полезно использовать методики предвычисления и кэширования промежуточных результатов. В случае частых операций с одинаковыми данными можно сохранить результаты объединений в виде временных таблиц или индексов, что позволяет существенно сократить время выполнения запросов.
И, наконец, стоит учитывать использование параллельных вычислений, если СУБД поддерживает такие возможности. Разделение работы на несколько потоков может существенно ускорить выполнение операций объединения строк, особенно при обработке больших объемов данных. Важно следить за балансом нагрузки между потоками, чтобы избежать проблем с блокировками или конкуренцией за ресурсы.
Вопрос-ответ:
Что такое объединение строк в одну в SQL и когда это может быть полезно?
Объединение нескольких строк в одну в SQL — это процесс комбинирования значений нескольких строк в одну строку. Это может быть полезно, например, когда необходимо получить все значения из нескольких строк в одном поле, чтобы упростить представление данных или подготовить их для отчетности. Это часто используется в случаях, когда необходимо составить список или текст из значений столбцов, которые распределены по нескольким записям.
Какие функции в SQL позволяют объединять строки в одну?
Для объединения строк в SQL можно использовать функцию `CONCAT()` или оператор `||` в некоторых базах данных, таких как PostgreSQL или Oracle. Функция `CONCAT()` позволяет объединить несколько строковых значений в одно. Например, запрос `SELECT CONCAT(Имя, ' ', Фамилия) FROM Сотрудники;` вернет полное имя каждого сотрудника в одной строке. Также для этого существует функция `GROUP_CONCAT()` в MySQL, которая объединяет значения из нескольких строк в одну с разделителями.
Можно ли использовать объединение строк в SQL в группировках?
Да, в SQL можно использовать объединение строк в сочетании с операциями группировки. Для этого обычно применяется функция `GROUP_CONCAT()` в MySQL или аналогичные функции в других СУБД. Например, если нужно собрать все имена сотрудников в одну строку для каждого отдела, можно написать запрос вида `SELECT отдел, GROUP_CONCAT(имя) FROM сотрудники GROUP BY отдел;`. Это объединит имена сотрудников в одном поле для каждого отдела.
Как избежать избыточности при объединении строк в SQL?
Чтобы избежать избыточности при объединении строк в SQL, можно использовать различные способы фильтрации данных перед объединением. Например, можно применить оператор `DISTINCT`, чтобы исключить дублирующиеся значения, или фильтровать строки на уровне запроса с помощью `WHERE`. Это помогает получить уникальные значения при объединении строк и предотвращает дублирование. Пример: `SELECT GROUP_CONCAT(DISTINCT имя) FROM сотрудники;`.