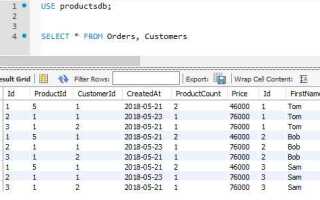
В реляционных базах данных данные редко хранятся в одной таблице. Например, сведения о заказах часто распределены между таблицами orders, customers и products. Чтобы извлечь полную картину, требуется объединение этих таблиц. SQL предоставляет для этого ключевые конструкции: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL JOIN.
INNER JOIN – наиболее распространённый тип объединения. Он возвращает только те строки, для которых есть совпадения по ключевым столбцам в обеих таблицах. Например, при объединении orders и customers по полю customer_id будут выбраны только те заказы, у которых есть информация о клиенте.
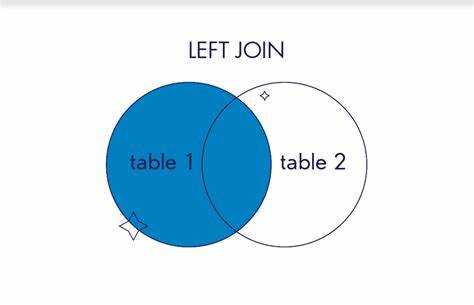
Если нужно сохранить все строки из одной таблицы, даже при отсутствии соответствующих записей в другой, используется LEFT JOIN. Это полезно, когда нужно отобразить все заказы, даже если некоторые клиенты были удалены из базы. RIGHT JOIN работает аналогично, но с приоритетом правой таблицы.
FULL JOIN объединяет обе таблицы, включая все строки независимо от наличия соответствующих записей. Это применимо при анализе неполных данных, когда необходимо понять, какие записи не совпадают.
Для достижения максимальной эффективности следует использовать индексы на соединяемых полях, избегать дублирующихся объединений и по возможности ограничивать выборку с помощью WHERE и LIMIT. Также важно учитывать, что избыточные JOIN’ы могут привести к экспоненциальному росту объема данных на выходе, особенно при множественных связях «один-ко-многим».
Когда использовать INNER JOIN и чем он отличается от других JOIN
INNER JOIN применяют, когда нужны только те строки, которые имеют соответствие в обеих объединяемых таблицах. Это фильтрация на этапе объединения: строки без совпадений исключаются из результата сразу, что уменьшает объем возвращаемых данных и ускоряет работу запроса при большом объеме таблиц.
В отличие от LEFT JOIN, который возвращает все строки из левой таблицы независимо от наличия совпадений в правой, INNER JOIN гарантирует, что результат содержит только логически связанные записи. Это особенно важно при построении отчетов, где нужны только актуальные и полные данные, например: клиенты, у которых есть заказы; сотрудники, закрепленные за проектами.
RIGHT JOIN аналогичен LEFT JOIN, но приоритет отдается правой таблице. Его используют реже, и в большинстве случаев можно обойтись LEFT JOIN с перестановкой таблиц. FULL JOIN возвращает все строки из обеих таблиц с null-значениями там, где нет совпадений. Его целесообразно использовать, только если нужна полная картина несоответствий между таблицами.
INNER JOIN – лучший выбор, если нужна высокая точность соответствия и отсутствуют ситуации, где нужно анализировать отсутствие связи между данными. Он предотвращает включение в выборку нерелевантных строк и упрощает последующую агрегацию и фильтрацию.
Как объединить таблицы с помощью LEFT JOIN и получить все данные из основной таблицы
Оператор LEFT JOIN используется, когда необходимо сохранить все строки из основной (левой) таблицы, даже если в присоединяемой таблице нет соответствующих значений. Это позволяет анализировать данные, включая случаи отсутствия связи между таблицами.
Пример: есть таблица users с пользователями и таблица orders с заказами. Нужно получить список всех пользователей, включая тех, кто не сделал ни одного заказа:
SELECT
users.id,
users.name,
orders.id AS order_id,
orders.total
FROM
users
LEFT JOIN
orders ON users.id = orders.user_id;
Если у пользователя нет заказов, поля order_id и total будут содержать NULL. Это особенно важно при построении отчетов с отсутствующими значениями.
Для фильтрации только тех записей, где нет совпадений, можно добавить условие:
SELECT
users.id,
users.name
FROM
users
LEFT JOIN
orders ON users.id = orders.user_id
WHERE
orders.id IS NULL;
LEFT JOIN сохраняет структуру левой таблицы, независимо от содержимого правой. Это критично в случаях, когда правая таблица может быть неполной или временно недоступной.
Если в левой таблице повторяющиеся значения ключа, результат будет содержать соответствующее количество строк на каждое совпадение или NULL, если совпадений нет. Это следует учитывать при агрегации данных:
SELECT
users.id,
users.name,
COUNT(orders.id) AS order_count
FROM
users
LEFT JOIN
orders ON users.id = orders.user_id
GROUP BY
users.id, users.name;
При работе с LEFT JOIN важно правильно указывать условия связывания, иначе результат может содержать некорректные дубликаты или пустые строки. Всегда проверяйте, что соединение основано на ключах, обеспечивающих логическую связь между таблицами.
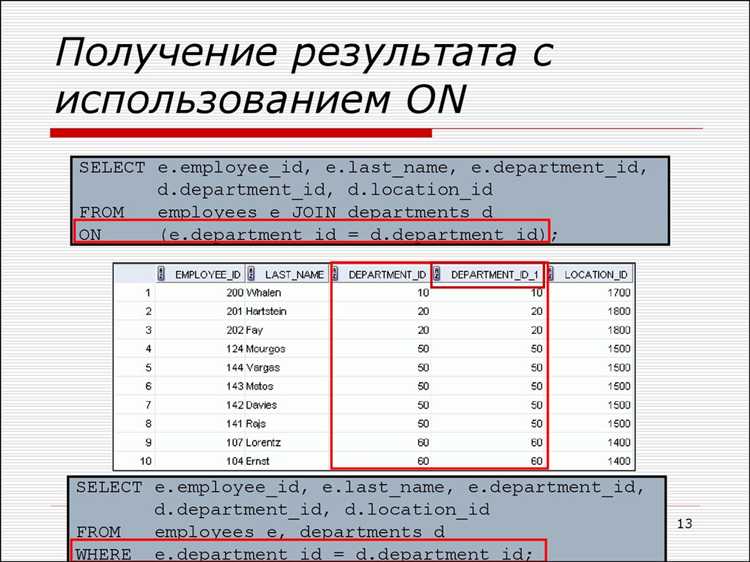
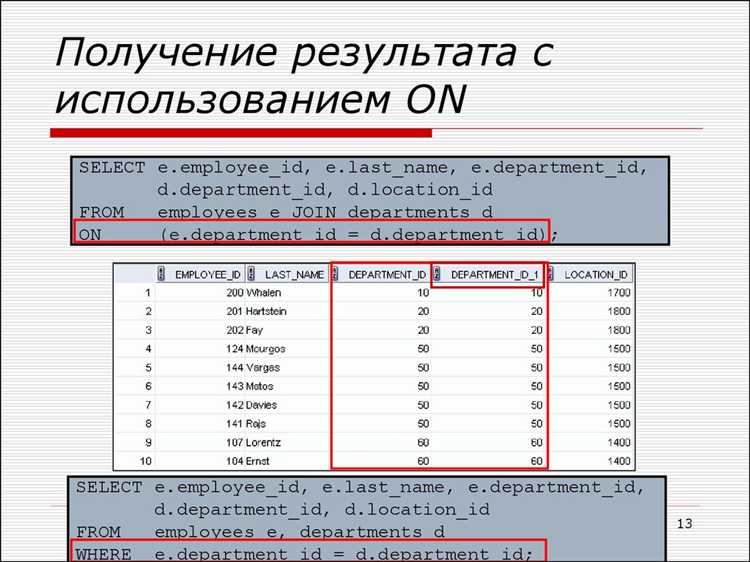
Пример использования RIGHT JOIN при работе с неполными данными
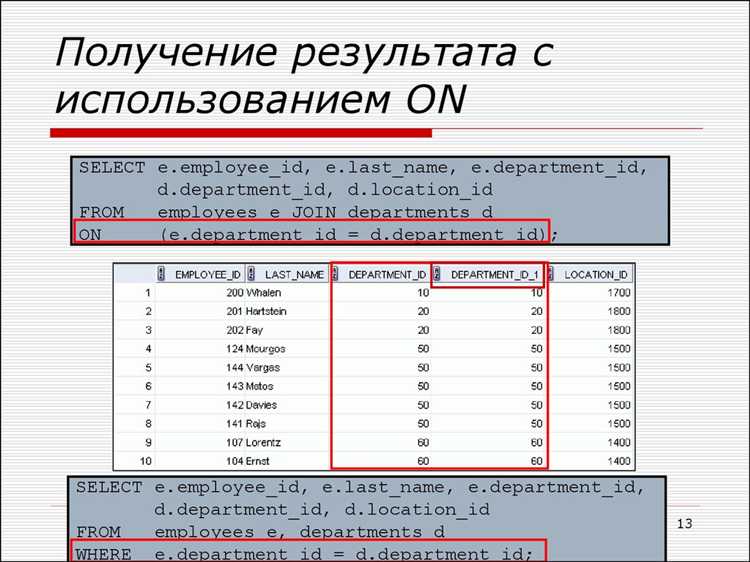
Допустим, в базе данных есть две таблицы: orders (заказы) и customers (клиенты). Не все заказы привязаны к существующим клиентам, так как часть записей могла быть удалена или создана вручную без проверки целостности данных.
Чтобы получить все заказы, включая те, у которых нет соответствующего клиента, используется RIGHT JOIN:
SELECT
o.order_id,
o.order_date,
c.customer_name
FROM
customers c
RIGHT JOIN
orders o ON c.customer_id = o.customer_id;
Рекомендуется явно обрабатывать NULL-значения для отображения понятной информации:
SELECT
o.order_id,
o.order_date,
COALESCE(c.customer_name, 'Неизвестный клиент') AS customer_name
FROM
customers c
RIGHT JOIN
orders o ON c.customer_id = o.customer_id;
Такой подход помогает выявить нарушения целостности данных и обеспечить корректную аналитику, не теряя заказы без привязки к клиентам.
Как работает FULL OUTER JOIN и в каких случаях он нужен
Оператор FULL OUTER JOIN объединяет строки из двух таблиц по условию соединения, включая все записи, даже если нет соответствий. Если совпадения не найдены, недостающие значения заполняются NULL.
Синтаксис:
SELECT *
FROM таблица1
FULL OUTER JOIN таблица2
ON таблица1.ключ = таблица2.ключ;Принцип работы:
- Возвращаются строки, у которых есть совпадения по ключу в обеих таблицах.
- Добавляются строки из первой таблицы без соответствий во второй – с
NULLв полях второй таблицы. - Добавляются строки из второй таблицы без соответствий в первой – с
NULLв полях первой таблицы.
FULL OUTER JOIN целесообразно использовать:
- При анализе различий между двумя источниками данных. Например, список заказов в CRM и учетной системе: позволяет выявить, какие заказы не синхронизированы.
- Для построения отчетов по активности пользователей, когда данные частично присутствуют в разных таблицах, например, регистрации и действия на сайте.
- В задачах миграции данных, чтобы проверить полноту и соответствие записей между старой и новой системами.
- При разработке диагностики данных – чтобы увидеть, где происходят потери или дублирование информации.
Рекомендации:
- Учитывайте, что
FULL OUTER JOINможет создавать большое количествоNULL-значений – важно грамотно обрабатывать их в выражениях и фильтрации. - Оптимизируйте запросы: используйте индексы на соединяемых полях и избегайте избыточных данных в выборке.
- Фильтруйте результат с помощью
WHERE, если требуется получить только несовпадающие строки, например:WHERE таблица1.ключ IS NULL OR таблица2.ключ IS NULL.
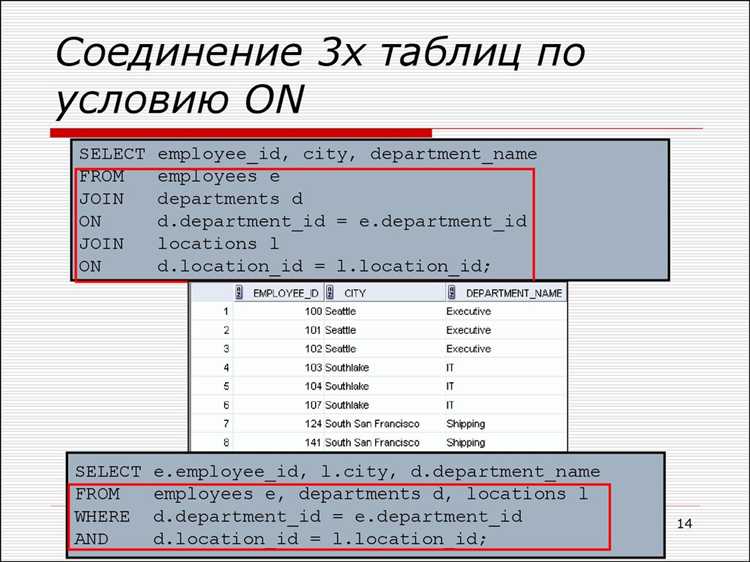
Объединение более двух таблиц в одном SQL-запросе
Для объединения трёх и более таблиц применяются последовательные JOIN-операции. Каждое новое соединение добавляется к результату предыдущего, при этом необходимо чётко определять условия связи, чтобы избежать избыточных строк или потерь данных.
Например, при работе с базой данных интернет-магазина можно объединить таблицы orders, customers и payments следующим образом:
SELECT o.id, c.name, p.amount
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN payments p ON o.id = p.order_id;
Ключевым моментом является логика объединения. Каждый JOIN должен быть обоснован структурой данных и бизнес-требованиями. Использование псевдонимов сокращает код и повышает читаемость. Объединения могут быть как INNER, так и OUTER – выбор зависит от необходимости включения или исключения записей без совпадений.
При большом числе таблиц важно избегать неявных связей и дублирующихся имён столбцов. Явное указание имени таблицы или псевдонима перед именем столбца устраняет неоднозначность и предотвращает ошибки выполнения запроса.
При использовании LEFT JOIN следует помнить, что условия фильтрации в WHERE могут неявно превращать внешнее соединение во внутреннее. Для сохранения всех строк основной таблицы используйте фильтрацию в блоке ON.
Для оптимизации сложных объединений применяйте индексы на соединяемые поля. Это значительно сокращает время выполнения запроса, особенно при работе с большими объёмами данных.
Фильтрация данных после объединения таблиц с помощью WHERE и ON
При объединении таблиц в SQL важно не только правильно указать условия соединения, но и отфильтровать данные, чтобы получить нужный результат. Это можно сделать с помощью операторов WHERE и ON. Каждый из них имеет свои особенности, которые важно учитывать.
Пример использования WHERE:
SELECT employees.name, departments.name FROM employees JOIN departments ON employees.department_id = departments.id WHERE employees.salary > 50000;
В этом запросе сначала выполняется соединение таблиц employees и departments, а затем результат фильтруется по условию зарплаты сотрудников выше 50,000.
Пример использования ON:
SELECT employees.name, departments.name FROM employees LEFT JOIN departments ON employees.department_id = departments.id AND employees.salary > 50000;
Здесь объединение таблиц происходит с фильтрацией сотрудников, чья зарплата превышает 50,000, на этапе соединения, а не после получения результата.
Когда использовать WHERE, а когда ON? Рекомендуется использовать ON для фильтрации условий соединения и WHERE для фильтрации данных после объединения. Это важно для правильного формирования запросов, особенно когда используются сложные соединения, такие как LEFT JOIN, RIGHT JOIN и другие.
- ON следует использовать, когда необходимо уточнить, какие строки из обеих таблиц должны быть соединены (например, если соединение зависит от значений из обеих таблиц).
- WHERE лучше использовать для фильтрации данных, уже полученных после соединения, особенно когда нужно исключить или выбрать конкретные строки в финальном наборе.
Также стоит отметить, что использование WHERE и ON в различных типах соединений (INNER JOIN, LEFT JOIN и других) может давать разные результаты, поскольку в некоторых случаях строка из одной из таблиц может быть исключена при фильтрации, в других – наоборот, включена, если это соединение LEFT JOIN или RIGHT JOIN.
Как избежать дублирования строк при объединении таблиц
1. Использование оператора DISTINCT
Для устранения дубликатов можно использовать оператор DISTINCT. Он позволяет отфильтровать повторяющиеся строки в результате объединения. Однако стоит учитывать, что применение DISTINCT может привести к снижению производительности, особенно при работе с большими объёмами данных.
2. Правильное использование JOIN
При объединении таблиц с помощью JOIN важно правильно настроить условия соединения. Например, использование неверных или недостаточно специфичных условий в ON может привести к множественным совпадениям и дублированию строк. Чтобы избежать этого, всегда проверяйте уникальность ключей в обеих таблицах, а также используйте INNER JOIN вместо LEFT JOIN, если вам не нужны строки без совпадений.
3. Уникальные ключи и индексы
Если столбцы, которые вы используете для объединения, не являются уникальными, это может быть причиной дублирования. В таких случаях стоит либо добавить уникальные индексы, либо пересмотреть структуру данных и определить, какие из столбцов должны быть уникальными.
4. Правильное использование оператора UNION
При объединении нескольких наборов данных с помощью UNION дубликаты удаляются автоматически. Однако если требуется сохранить все строки, включая дубликаты, следует использовать UNION ALL. Это важно, чтобы понимать, что UNION сам по себе устраняет дубли, а UNION ALL не делает этого.
5. Агрегация данных
В некоторых случаях дублирование строк можно избежать через агрегацию данных с помощью функций GROUP BY. Это особенно полезно, когда вы хотите получить уникальные комбинации значений по определённым столбцам. Например, можно группировать строки по ключевым полям и агрегировать остальные данные с помощью функций, таких как SUM, COUNT, AVG.
6. Проверка источников данных
Важно проверить сами таблицы перед объединением. Например, если одна из таблиц уже содержит дублирующиеся строки, это обязательно повлияет на итоговый результат. В таких случаях можно заранее удалить дубликаты с помощью DELETE или ROW_NUMBER, чтобы гарантировать уникальность строк перед объединением.
Используя эти методы, можно значительно снизить риск дублирования строк и улучшить качество работы с объединёнными таблицами.
Использование подзапросов и CTE для объединения таблиц со сложной логикой
При необходимости объединить несколько таблиц с учетом сложной логики, часто применяются подзапросы и Common Table Expressions (CTE). Эти методы позволяют более гибко и читаемо строить запросы, когда стандартные JOIN не дают нужного результата или сильно усложняют структуру запроса.
Подзапросы могут быть использованы как в SELECT, так и в FROM или WHERE частях запроса. Важно помнить, что подзапросы, вложенные в FROM, часто называют деривационными таблицами. Такие подзапросы выполняются до основного запроса и могут использоваться как временные таблицы для объединения данных.
Пример подзапроса в FROM:
SELECT main.id, main.name, sub.total_sales FROM employees main JOIN (SELECT employee_id, SUM(sales_amount) AS total_sales FROM sales GROUP BY employee_id) sub ON main.id = sub.employee_id;
В данном примере подзапрос вычисляет сумму продаж для каждого сотрудника, и результат этого подзапроса затем используется в основном запросе для соединения с таблицей employees.
CTE (Common Table Expressions) представляют собой удобный способ организации сложных запросов. С помощью CTE можно разделить логику запроса на несколько частей, улучшив читаемость и облегчая отладку. CTE особенно полезны, когда требуется использовать одну и ту же выборку несколько раз в одном запросе или когда необходимо организовать рекурсивные запросы.
Пример использования CTE для объединения таблиц:
WITH EmployeeSales AS ( SELECT employee_id, SUM(sales_amount) AS total_sales FROM sales GROUP BY employee_id ) SELECT e.id, e.name, es.total_sales FROM employees e JOIN EmployeeSales es ON e.id = es.employee_id;
В этом примере CTE EmployeeSales сначала вычисляет общую сумму продаж для каждого сотрудника. Основной запрос затем объединяет таблицы employees и EmployeeSales, что делает структуру запроса более логичной и упрощает поддержку.
Для сложных логик, например, при необходимости динамического изменения условий фильтрации или агрегации, CTE позволяет сократить дублирование кода и упростить модификации запроса.
Рекурсивные CTE позволяют работать с иерархическими данными. В таких случаях CTE может быть использован для выполнения итераций до тех пор, пока не будут получены все нужные данные. Это полезно при запросах, связанных с деревьями или графами, например, для получения подчинённых сотрудников.
WITH RECURSIVE EmployeeHierarchy AS ( SELECT id, manager_id, name FROM employees WHERE manager_id IS NULL UNION ALL SELECT e.id, e.manager_id, e.name FROM employees e JOIN EmployeeHierarchy eh ON e.manager_id = eh.id ) SELECT * FROM EmployeeHierarchy;
Здесь рекурсивный CTE строит иерархию сотрудников, начиная с высшего руководства и продолжая до подчинённых, что позволяет эффективно работать с иерархическими данными без использования сложных вложенных запросов.
Комбинирование подзапросов и CTE открывает широкий спектр возможностей для построения запросов с многосложной логикой. Важно выбирать между этими подходами в зависимости от сложности запроса, структуры данных и требований к производительности.
Вопрос-ответ:
Как объединять несколько таблиц в SQL?
Для объединения нескольких таблиц в SQL обычно используют оператор JOIN. Он позволяет объединять данные из разных таблиц на основе общего столбца. Существует несколько типов JOIN: INNER JOIN, LEFT JOIN, RIGHT JOIN и FULL OUTER JOIN, каждый из которых работает по-разному в зависимости от того, какие строки нужно включать в результат. Например, INNER JOIN объединяет только те строки, которые есть в обеих таблицах, а LEFT JOIN включает все строки из левой таблицы, даже если соответствующих данных в правой таблице нет.
Как объединить таблицы, если между ними нет явных общих столбцов?
Если между таблицами нет явных общих столбцов, то можно использовать кросс-объединение с помощью оператора CROSS JOIN. Этот тип объединения создаёт декартово произведение, т.е. каждая строка из первой таблицы будет соединяться с каждой строкой из второй таблицы. В результате вы получите все возможные комбинации строк, что может привести к большому объему данных. Этот метод подходит, если нужно создать все возможные сочетания строк из разных таблиц, но в большинстве случаев его используют крайне осторожно, чтобы не перегрузить систему.
Как избежать дублирования данных при объединении таблиц с помощью SQL?
Чтобы избежать дублирования данных при объединении таблиц, можно использовать оператор DISTINCT в SQL. Он позволяет выбрать только уникальные строки из результата объединения. Например, если вы используете INNER JOIN или LEFT JOIN, добавив DISTINCT в запрос, вы получите только уникальные комбинации строк. Также важно убедиться, что соединяемые столбцы содержат уникальные значения в каждой из таблиц, если дублирование не является необходимым. В некоторых случаях, чтобы избежать дублирования, можно использовать подзапросы или другие методы фильтрации данных.