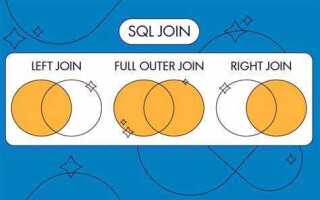
В SQL часто требуется объединять несколько запросов для получения более сложных данных или для повышения эффективности работы с базой данных. Для этого существуют различные подходы, такие как использование JOIN, UNION и SUBQUERY. Знание того, какой метод выбрать в зависимости от ситуации, позволяет значительно улучшить производительность запросов и упростить код.
Когда нужно объединить данные из нескольких таблиц, наиболее часто используется JOIN. Этот оператор позволяет «связать» строки из разных таблиц по общему признаку. Например, для того чтобы получить информацию о заказах и клиентах, можно использовать INNER JOIN, который возвращает только те записи, где есть совпадения в обеих таблицах. Важно помнить, что при неправильном использовании JOIN может возникать избыточность данных, что приведет к значительному ухудшению производительности.
Если задача заключается в объединении результатов разных запросов, а не таблиц, то следует использовать UNION. Этот оператор позволяет объединить несколько наборов данных в один, устраняя дублирование. Примером может служить создание отчетов по данным из разных временных периодов, когда каждый запрос возвращает данные за определенный месяц, а UNION помогает объединить все месячные отчеты в один.
Для более сложных сценариев, когда требуется вложенность запросов или выполнение нескольких операций над данными до их объединения, стоит использовать SUBQUERY. Подзапросы позволяют изолировать части логики и применять их к основным данным. Например, можно сначала получить список клиентов, сделавших заказ, а затем в основном запросе выполнить анализ их покупок за последний месяц.
Как использовать UNION для объединения результатов различных запросов
Оператор UNION в SQL позволяет объединить результаты нескольких запросов в один набор данных. Это особенно полезно, когда необходимо извлечь информацию из различных таблиц или выполнить несколько фильтраций с разными критериями. Главное условие при использовании UNION – одинаковое количество и типы столбцов в каждом запросе. Это гарантирует правильность объединённого результата.
Каждый запрос внутри оператора UNION должен возвращать одинаковое количество столбцов, и типы данных этих столбцов должны быть совместимы. Например, если в одном запросе возвращается столбец с типом данных VARCHAR, то и в других запросах столбцы должны иметь такой же тип данных.
По умолчанию оператор UNION удаляет дублирующиеся строки из объединённого результата. Для сохранения всех строк, включая дубликаты, используется оператор UNION ALL. Это может быть полезно, если требуется сохранить все записи без фильтрации повторений.
Пример использования UNION:
SELECT имя, возраст FROM сотрудники
UNION
SELECT имя, возраст FROM клиенты;
В этом примере два запроса объединяются с помощью UNION, и результат будет включать имена и возраст как сотрудников, так и клиентов, при этом дубликаты будут исключены.
Когда используются различные запросы с фильтрацией данных, следует быть внимательным к порядку, в котором они выполняются, и к тому, какие данные могут быть исключены. Для повышения производительности можно использовать UNION ALL, если уверены, что дублирование данных не станет проблемой.
Важно помнить, что порядок строк в объединённом результате не гарантируется, если не используется оператор ORDER BY. Чтобы отсортировать результаты по конкретному столбцу, нужно указать сортировку в конце запроса.
Пример с сортировкой:
SELECT имя, возраст FROM сотрудники
UNION
SELECT имя, возраст FROM клиенты
ORDER BY возраст DESC;
Таким образом, использование UNION позволяет гибко работать с несколькими наборами данных, объединяя их в одном запросе, и это можно делать как с фильтрацией, так и с сортировкой данных для удобства анализа.
Подключение нескольких таблиц с помощью JOIN
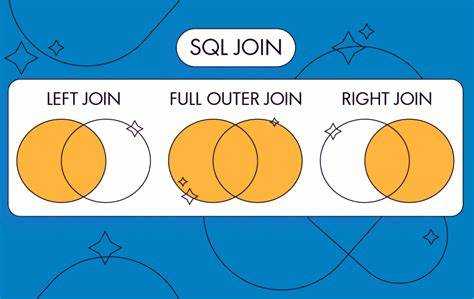
INNER JOIN – это стандартное соединение, при котором в результирующем наборе данных присутствуют только те строки, которые соответствуют условию соединения в обеих таблицах. Если в одной из таблиц нет подходящего значения, соответствующая строка не попадёт в результат. Пример запроса:
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id;
Здесь мы соединяем таблицу orders с таблицей customers по полю customer_id, получая список заказов с именами клиентов, которые сделали эти заказы.
LEFT JOIN (или LEFT OUTER JOIN) соединяет таблицы таким образом, что все строки из левой таблицы попадут в результат, а строки из правой таблицы будут добавляться только в том случае, если найдено соответствие. Если соответствий нет, то в полях правой таблицы будут возвращены NULL значения. Пример:
SELECT customers.customer_name, orders.order_id
FROM customers
LEFT JOIN orders ON customers.customer_id = orders.customer_id;
RIGHT JOIN (или RIGHT OUTER JOIN) работает аналогично LEFT JOIN, но в этом случае все строки из правой таблицы попадут в результат, а строки из левой таблицы будут отображаться только при наличии соответствия. Пример:
SELECT orders.order_id, customers.customer_name
FROM orders
RIGHT JOIN customers ON orders.customer_id = customers.customer_id;
Этот запрос вернёт все заказы, даже если в таблице orders нет информации о некоторых клиентах, в таком случае поле order_id будет содержать NULL.
FULL JOIN (или FULL OUTER JOIN) объединяет строки из обеих таблиц, включая те, для которых нет соответствий в другой таблице. Строки из обеих таблиц будут отображаться с NULL в местах, где нет соответствующих данных. Пример:
SELECT employees.employee_name, departments.department_name
FROM employees
FULL JOIN departments ON employees.department_id = departments.department_id;
Использование JOIN значительно упрощает работу с данными, особенно в случаях, когда необходимо анализировать взаимосвязи между несколькими таблицами. Важно правильно выбирать тип соединения в зависимости от того, какие данные нужно получить: все ли строки из обеих таблиц или только те, для которых существует соответствие.
Использование подзапросов для объединения данных
Когда основной запрос требует данных, которые могут быть извлечены через отдельный запрос, подзапросы становятся эффективным решением. Например, подзапросы могут быть использованы для фильтрации результатов, агрегации данных или получения значений из нескольких таблиц одновременно. Подзапросы в WHERE позволяют динамично фильтровать строки, основываясь на значениях, полученных из другой таблицы. Использование подзапроса в SELECT может быть полезным для извлечения вычисленных значений, например, для подсчёта средней зарплаты сотрудника внутри подзапроса, который затем используется в основном запросе для анализа.
Один из распространённых случаев использования подзапросов – это объединение данных из разных источников. Например, если нужно найти сотрудников, чья зарплата выше средней по всей компании, подзапрос можно использовать для вычисления средней зарплаты, а затем фильтровать сотрудников с зарплатой выше этого значения:
SELECT name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
Подзапросы также часто используются для работы с агрегированными данными. Например, чтобы получить список всех продуктов, у которых цена выше средней цены товаров в категории, можно использовать подзапрос в WHERE или HAVING:
SELECT product_name, price FROM products WHERE price > (SELECT AVG(price) FROM products WHERE category_id = 1);
Важно помнить, что подзапросы могут существенно влиять на производительность запроса, особенно если они выполняются для каждой строки основного запроса. Поэтому следует учитывать возможность оптимизации, например, заменив подзапрос на JOIN, если это возможно.
В некоторых случаях подзапросы можно заменить на соединения (JOIN), что может улучшить производительность, особенно при работе с большими объемами данных. Например, использование LEFT JOIN может быть более эффективным, чем подзапросы для извлечения информации из связанной таблицы.
Таким образом, подзапросы в SQL являются мощным инструментом для объединения данных, однако важно правильно выбирать между подзапросами и другими методами соединений, чтобы обеспечить оптимизацию запросов.
Объединение запросов с различными типами данных
Объединение запросов с различными типами данных требует внимательности при согласовании типов в SQL. Использование операторов объединения, таких как UNION или JOIN, с различными типами данных может привести к ошибкам или некорректным результатам, если типы не приведены к совместимым форматам.
При использовании оператора UNION важно, чтобы столбцы в объединяемых запросах имели одинаковые типы данных. Например, если один запрос возвращает столбец типа INTEGER, а второй – VARCHAR, необходимо привести один из них к нужному типу с помощью функции CAST или CONVERT. Несоответствие типов вызовет ошибку.
Пример приведения типов при объединении запросов:
SELECT id, name FROM employees UNION SELECT CAST(employee_id AS INTEGER), CAST(employee_name AS VARCHAR) FROM contractors;
При объединении запросов с различными типами данных с использованием оператора JOIN, важно учитывать, что SQL не выполнит соединение по несовместимым типам данных. Например, соединение числового значения с текстом может привести к ошибке или неожиданным результатам. В таких случаях также используется приведение типов для согласования данных.
Пример использования JOIN с приведением типов:
SELECT e.id, e.name, c.contract_id FROM employees e JOIN contractors c ON e.id = CAST(c.employee_id AS INTEGER);
Для сложных типов данных, таких как DATE или DATETIME, важно учитывать формат и использование функций преобразования. Иногда требуется привести даты к единому формату, чтобы избежать ошибок при сравнении.
При объединении данных с различными типами, таких как строковые и числовые значения, можно использовать функции типа COALESCE или NULLIF для обработки значений NULL, что позволит избежать ошибок при обработке пустых или некорректных данных.
В целом, при объединении запросов с различными типами данных следует проверять совместимость типов и, если необходимо, использовать явное приведение типов для получения корректных результатов.
Использование GROUP BY после объединения запросов
Когда объединяются несколько запросов с помощью оператора UNION или JOIN, важно учитывать, как использование GROUP BY влияет на итоговый результат. В большинстве случаев, применение GROUP BY после объединения запросов позволяет агрегировать данные, полученные из различных таблиц, по определённым столбцам. Этот прием эффективен для получения сводной информации по объединённым результатам.
Если используются операторы UNION или UNION ALL, то агрегировать данные можно как в каждом отдельном запросе, так и в целом после объединения. В случае UNION ALL дублированные строки не удаляются, что может повлиять на результаты агрегации. Если же используется UNION, то дублирующиеся строки автоматически исключаются, и GROUP BY уже будет работать с уникальными значениями.
Пример использования GROUP BY после объединения запросов через UNION:
SELECT department, COUNT(*) as total FROM employees GROUP BY department UNION SELECT department, COUNT(*) as total FROM contractors GROUP BY department;
В данном примере два запроса объединяются с помощью UNION, после чего результат агрегируется по столбцу department. Таким образом, мы получаем общее количество сотрудников и подрядчиков по каждому отделу.
Когда используется JOIN, GROUP BY позволяет агрегировать данные, полученные из нескольких таблиц. Например, для получения общей суммы заказов по каждому клиенту после объединения таблиц клиентов и заказов через INNER JOIN:
SELECT customers.name, SUM(orders.amount) as total_sales FROM customers INNER JOIN orders ON customers.id = orders.customer_id GROUP BY customers.name;
В данном случае, данные по клиентам и заказам объединяются с помощью JOIN, а затем агрегация происходит по имени клиента.
Важно помнить, что GROUP BY должен следовать за всеми объединениями запросов. Попытка использовать GROUP BY до объединения запросов может привести к некорректным результатам. Для правильной агрегации следует учитывать, что вся логика группировки должна быть применена после завершения всех объединений запросов.
Как управлять порядком объединения данных с помощью ORDER BY

Команда ORDER BY используется для сортировки результатов SQL-запроса. Она определяет порядок, в котором строки будут возвращены в результате объединения данных из разных таблиц. Порядок сортировки можно настроить по одному или нескольким столбцам, а также указать направление сортировки (по возрастанию или по убыванию).
Чтобы правильно использовать ORDER BY в запросах с объединением (JOIN), важно понимать несколько ключевых аспектов:
- Указание столбцов для сортировки: В запросах с объединением данные могут поступать из разных таблиц, и ORDER BY следует применять к столбцам, которые наиболее логично отражают нужный порядок. Например, если вы объединяете таблицу заказов с таблицей клиентов, может быть полезно сортировать по дате заказа или фамилии клиента.
- Направление сортировки: По умолчанию SQL сортирует данные по возрастанию (ASC). Если вам нужно изменить порядок на убывающий, используйте ключевое слово DESC. Например, сортировка по дате может быть выполнена с параметром ORDER BY date DESC для отображения последних записей вверху.
- Сортировка по нескольким столбцам: Если необходимо, чтобы данные сортировались по нескольким признакам, можно указать несколько столбцов. Например, сначала по фамилии клиента, затем по дате заказа:
ORDER BY customer_name ASC, order_date DESC. - Сортировка при объединении: При объединении данных из нескольких таблиц важно учитывать, что SQL будет сортировать строки после объединения, а не до. Это может повлиять на порядок в случае, если одна из таблиц содержит большое количество данных, что влияет на эффективность запроса.
- Производительность: Сортировка данных может сильно повлиять на производительность, особенно при больших объемах данных. Если сортировка выполняется после объединения (например, с помощью JOIN), она может быть ресурсоемкой. В таких случаях рекомендуется проверять планы выполнения запросов и использовать индексы для ускорения сортировки.
Важно помнить, что если ORDER BY применяется после JOIN, то сначала происходит объединение данных, а затем сортировка по указанным столбцам. Это может быть полезно, если важно получить данные в определенном порядке после объединения, но стоит учитывать, что если сортировка выполняется по столбцам, которые присутствуют в нескольких таблицах, следует уточнить, из какой таблицы брать данные.
Работа с фильтрацией данных при объединении запросов
При объединении запросов в SQL важно учитывать, как фильтрация данных влияет на результаты. В зависимости от типа объединения (INNER JOIN, LEFT JOIN, RIGHT JOIN и других) фильтрация может существенно изменить конечный набор данных. Рассмотрим основные моменты, которые следует учитывать при фильтрации данных в объединённых запросах.
Когда используются операторы соединения, фильтрация данных может происходить как до, так и после объединения таблиц. Рассмотрим два основных подхода:
- Фильтрация до объединения: Этот подход предполагает использование условия фильтрации в
WHEREдо выполнения объединения таблиц. В таком случае фильтрация будет происходить только в одной из таблиц. Например, если вы хотите отфильтровать только тех клиентов, которые совершили покупки в определённый период, фильтрация должна происходить до объединения с таблицей заказов. - Фильтрация после объединения: Когда условие фильтрации применяется после объединения таблиц, то фильтрация будет учитываться для всей результирующей выборки. Это особенно важно, если вам нужно отфильтровать строки, которые содержат данные из обеих таблиц, а не только из одной.
Пример:
SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id WHERE orders.order_date >= '2023-01-01';
В данном случае фильтрация происходит после объединения таблиц, что означает, что в результирующем наборе данных будут только те строки, где заказ был сделан после 1 января 2023 года.
Если фильтрация должна касаться только одной из таблиц до объединения, то необходимо использовать конструкцию WHERE до JOIN:
SELECT * FROM customers LEFT JOIN orders ON customers.id = orders.customer_id WHERE customers.country = 'USA';
Этот запрос возвращает всех клиентов из США, включая тех, у кого нет заказов, но только после того, как данные из таблицы клиентов были отфильтрованы по стране.
При работе с фильтрацией данных следует быть внимательным к типам объединений:
- INNER JOIN: Фильтрация обычно происходит после объединения, так как только строки, удовлетворяющие условию объединения, попадают в результат.
- LEFT JOIN: Если фильтрация применяется до объединения, то в результирующем наборе останутся все строки из левой таблицы, даже если соответствующие данные из правой таблицы отсутствуют.
- RIGHT JOIN: В случае фильтрации до объединения будут возвращены все строки из правой таблицы, даже если нет соответствующих строк в левой.
Использование фильтрации в объединённых запросах требует внимательности, так как неправильно расположенные условия могут повлиять на производительность и точность результатов. Важно учитывать, что фильтрация на разных этапах может приводить к разным результатам в зависимости от структуры запроса и целей анализа.
Проблемы производительности при объединении запросов и способы их решения
Одним из способов решения этой проблемы является создание индексов на колонках, которые участвуют в соединениях. Это позволяет сократить количество операций, необходимых для поиска совпадений. Однако, создание индексов на больших таблицах может занять значительное время и требует дополнительных ресурсов при обновлении данных.
Другая проблема возникает, когда запросы объединяют несколько крупных таблиц, и сервер не оптимизирует их выполнение должным образом. В таких случаях можно использовать подзапросы, чтобы уменьшить объем данных, которые обрабатываются на каждом этапе выполнения запроса. Это помогает избежать обработки лишних строк и ускоряет выполнение.
Особое внимание следует уделить использованию INNER JOIN и LEFT JOIN, поскольку неправильный выбор типа соединения может привести к увеличению объема данных, передаваемых между операциями. Например, если используется LEFT JOIN на большом наборе данных, где большинство строк не имеют совпадений, это приведет к ненужному увеличению результата запроса. Рекомендуется использовать INNER JOIN, когда необходимо вернуть только строки с совпадениями.
В случаях, когда объединение запросов невозможно оптимизировать с помощью индексов и подзапросов, стоит рассмотреть возможность разбиения запроса на несколько меньших запросов. Каждый из этих запросов может быть выполнен поочередно, что уменьшит нагрузку на сервер и ускорит выполнение операций. Однако это решение может потребовать дополнительных усилий для обработки промежуточных данных и их агрегирования.
Также стоит учитывать возможность использования анализаторов запросов и профилирования, чтобы понять, где именно возникают узкие места в процессе выполнения запроса. Современные СУБД, такие как PostgreSQL и MySQL, предлагают средства для выполнения объяснений планов запросов, что позволяет выявить проблемные участки и оптимизировать их.
Наконец, важно помнить о том, что любые изменения в запросах должны быть протестированы на реальных данных, чтобы убедиться в повышении производительности. В противном случае, внесение изменений может привести к неожиданным результатам и ухудшению работы системы.
Вопрос-ответ:
Как объединить несколько SQL-запросов в один?
Для объединения нескольких запросов в один можно использовать операторы `UNION`, `JOIN` или `WITH`. В зависимости от задачи, вы можете выбрать подходящий способ. Например, если нужно объединить результаты из разных таблиц, можно использовать `UNION`. Если необходимо соединить таблицы по общим полям, тогда подойдёт `JOIN`. С помощью `WITH` можно создать временные таблицы для упрощения сложных запросов.
Что такое оператор JOIN и как его использовать для объединения запросов?
Оператор `JOIN` используется для объединения строк из двух и более таблиц на основе общего поля. Например, если в одной таблице хранится информация о клиентах, а в другой — заказы, можно использовать `JOIN`, чтобы получить все заказы конкретного клиента. Пример запроса: `SELECT * FROM customers JOIN orders ON customers.id = orders.customer_id;` В данном случае строки из обеих таблиц будут объединены, если их значения в полях `id` и `customer_id` совпадают.
Как объединить запросы с разными столбцами в одном запросе?
Если необходимо объединить запросы, которые возвращают разные столбцы, можно использовать оператор `UNION`. Он соединяет результаты нескольких SELECT-запросов в один, но важно, чтобы количество и типы столбцов в этих запросах совпадали. Если столбцы различаются, можно привести их к одному виду с помощью выражений или `NULL` в местах, где данные отсутствуют.
Как объединить несколько SQL-запросов в один?
Чтобы объединить несколько запросов в один, можно использовать операторы SQL, такие как `UNION`, `JOIN` или подзапросы, в зависимости от задачи. Например, для объединения данных из двух таблиц с одинаковой структурой (количеством столбцов и типами данных) можно использовать оператор `UNION`, который добавляет результаты одного запроса к результатам другого. Если же требуется соединить данные из разных таблиц по общему полю, следует использовать `JOIN`. Каждый метод имеет свои особенности, которые зависят от структуры данных и целей запроса.