В крупных инсталляциях MS SQL Server диск I/O может составлять до 70 % общей задержки запросов. Регулярный мониторинг счётчиков Disk Reads/sec и Disk Writes/sec с помощью Performance Monitor или встроенного отчёта «System Dashboard» помогает выявить узкие места. При уровне >200 операций чтения или записи в секунду стоит перейти к детальному анализу.
Одним из эффективных способов оптимизации является перестройка индексов. Увеличение порога фрагментации до 30 % для операции REORGANIZE и до 5 % для операции REBUILD позволяет снизить нагрузку на диск до 20–30 % без избыточных затрат ресурсов. Используйте команду ALTER INDEX … REBUILD WITH (ONLINE = ON) в пиковые часы для минимального простоя.
Настройка порядка размещения файлов данных и журналов в разных физических томах уменьшает конкуренцию за I/O. Разнесите файлы MDF/NDF и LDF на отдельные RAID-массивы: оптимально – RAID 10 для данных и RAID 1 для транзакционных журналов. Это снижает латентность записи логов до 1–5 мс и повышает устойчивость к пиковым нагрузкам.
Использование Buffer Pool Extension на быстрых NVMe-дисках способно автоматически кэшировать горячие страницы, сокращая обращения к основному хранилищу на 40 –60 %. При объёме ОЗУ менее 32 ГБ внедрение BPE улучшает общую производительность, но требует мониторинга использования файлов BPE через DMV sys.dm_os_buffer_descriptors.
Настройка параметров автосборки статистики для минимизации I/O
Автосборка статистики в MS SQL Server по умолчанию запускается при изменении ≥20% строк в таблице. Для крупных объектов это приводит к всплескам I/O. Снизить нагрузку позволяет точечная настройка порога с помощью параметра AUTO_UPDATE_STATISTICS_ASYNC и опций базы.
1. Включите асинхронное обновление статистики:
ALTER DATABASE [ИмяБД]
SET AUTO_UPDATE_STATISTICS_ASYNC ON;
Асинхронный режим позволяет снизить пиковую нагрузку, поскольку обновление статистики выполняется после завершения запросов, а не блокирует их исполнение.
2. Измените порог срабатывания автосборки для конкретных таблиц с помощью фильтра:
ALTER INDEX ALL ON dbo.ЦелеваяТаблица
REBUILD WITH (STATISTICS_NORECOMPUTE = OFF);
UPDATE STATISTICS dbo.ЦелеваяТаблица
WITH SAMPLE 10 PERCENT, RESAMPLE;
Значение SAMPLE 10 PERCENT ограничит чтение данных 10% строк, сокращая I/O при обновлении.
3. Установите на уровне базы минимальный порог изменения строк:
EXEC sp_dboption @dbname = N'ИмяБД',
@optname = N'auto update statistics',
@optvalue = N'true';
DBCC TRACEON (2371, -1);
Трассировка 2371 снижает порог автосборки для таблиц >25 000 строк пропорционально размеру (новый порог ≈ 1,000,000 / количество строк). Это позволяет более часто обновлять только действительно активно изменяемые объекты.
4. Настройте Job в SQL Server Agent для ручного обновления статистики в «тихие» часы:
Создайте задание с T-SQL:
EXECUTE sp_MSforeachtable
'UPDATE STATISTICS ? WITH FULLSCAN';
Запуск ночью гарантирует минимальную конкуренцию за диск.
5. Мониторьте длительность и объем чтения статистики через DMV:
SELECT object_name(s.object_id) AS TableName,
stats_id,
last_updated,
modification_counter
FROM sys.dm_db_stats_properties(s.object_id, s.stats_id) AS s;
При увеличении modification_counter на 10 000–20 000 и росте last_updated более суток – повышайте частоту Job или снижайте порог трассировкой 2371.
Оптимизация индексов: выбор между кластерными и некластерными
Кластерный индекс задаёт физический порядок строк в таблице. При наличии частых диапазонных запросов (BETWEEN, >, <) на поле с высокой селективностью, кластерный индекс уменьшает число операций чтения, группируя соседние данные подряд. Например, для таблицы продаж с ежемесячным отчётом по дате целесообразно кластеризовать по полю SaleDate, что сократит физические переходы диска до 30–50%.
Некластерный индекс хранит копии заданных колонок и указатели на исходные строки. Он выгоден, когда запросы используют конкретные значения (равенства) на нескольких полях. При использовании составных некластерных индексов (до 16 ключей) важно соблюдать порядок колонок: сначала наиболее селективные, затем – часто фильтруемые. В выборке из таблицы клиентов с миллионом записей индекс по (Country, City) снизит количество чтений на 40–60% при запросе фильтрации по обоим полям.
Комбинированная стратегия: оставить кластерный индекс на поле, по которому проходит большинство диапазонных операций, и добавить 2–3 некластерных для самых затратных запросов по детализации. Регулярно анализировать DMV sys.dm_db_index_usage_stats и sys.dm_db_index_physical_stats: при низком avg_fragmentation_in_percent (<10%) нечего перестраивать, при >30% выполнять REBUILD, а в диапазоне 10–30% – REORGANIZE.
Учет объёма свободного пространства: для таблиц >100 ГБ рекомендуем держать fillfactor в пределах 80–90% для непредвиденных вставок, чтобы избежать частых страничных расколок и дополнительных I/O. При внезапном росте лог-файла мониторить Page Splits/sec через PerfMon и корректировать fillfactor.
При проектировании новых таблиц опирайтесь на ожидаемый характер нагрузки: для OLTP-систем выбор в пользу некластерных индексов по часто обновляемым полям уменьшит конкуренцию блокировок, а для OLAP-сценариев – кластеризация по ключевым столбцам для ускорения сканирования.
Планирование фоновых задач с помощью Resource Governor
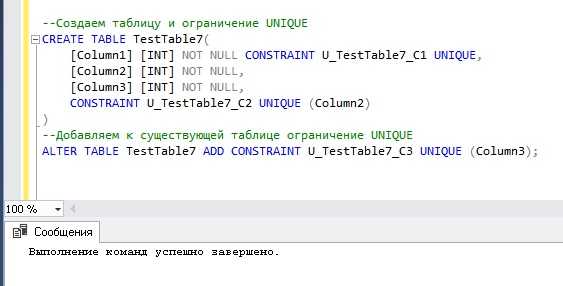
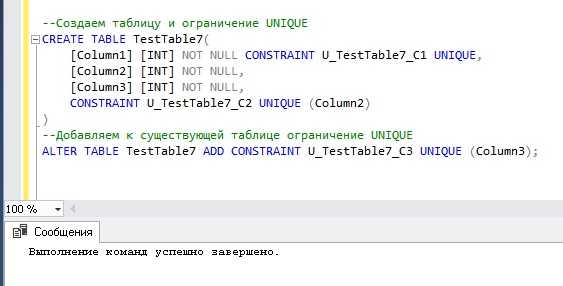
Разделите фоновые операции (архивацию, индексацию, выгрузку логов) в отдельный пул ресурсов: создайте класс workload группы “BG_TASKS” и назначьте для него ограничение I/O до 20 MB/s. Пример:
CREATE WORKLOAD GROUP BG_TASKS
USING [default]
WITH (MAX_IOPS = 0, MAX_MB_PER_SEC = 20);
ALTER RESOURCE GOVERNOR RECONFIGURE;
Привяжите фоновые процедуры к этой группе через функцию APPLICATION_NAME в connection string или через контекст SESSION_CONTEXT. В скрипте запуска укажите:
EXEC sp_set_session_context @key = N’resource_group’, @value = N’BG_TASKS’;
Ограничение в 20 MB/s снижает пиковую нагрузку, но не останавливает задачу: процесс выдерживает стабильную пропускную способность и равномерно расходует I/O. Для тонкой настройки измеряйте фактический объём чтения/записи раз в час через DMV sys.dm_io_virtual_file_stats и при необходимости изменяйте лимит каждые 24 ч.
Пример мониторинга:
SELECT database_id, file_id, num_of_reads, num_of_writes, io_stall_read_ms, io_stall_write_ms
FROM sys.dm_io_virtual_file_stats(NULL, NULL);
Переопределяйте при пиковых нагрузках в будние часы (09:00–18:00) до 10 MB/s, а в ночное время (00:00–06:00) повышайте до 50 MB/s. Для автоматизации используйте SQL Agent Job с двумя шагами:
1. Скрипт изменения MAX_MB_PER_SEC для BG_TASKS в 09:00 и 18:00.
2. Скрипт альтернативных значений в 00:00 и 06:00.
Убедитесь, что после каждого изменения выполнена команда:
ALTER RESOURCE GOVERNOR RECONFIGURE;
Перенос журналов транзакций на отдельные физические диски
Размещение файлов журналов транзакций (.ldf) на отдельных физических дисках снижает конкуренцию за I/O и повышает пропускную способность. Если основная база данных и журналы транзакций находятся на одном томе, каждое синхронное сбросное событие блокирует операции чтения/записи. В типичных OLTP-нагрузках журнал генерирует до 70 % операций записи.
Рекомендации по конфигурации: 1) Выделите отдельный RAID-массив (минимум RAID 1+0) под журналы – оптимально 4–6 SSD с показателем IOPS не ниже 10 000 на диск. 2) В настройках SQL Server укажите для логических файлов журнала полного пути на новый том. 3) Ограничьте размер файла журнала вручную: задайте начальный размер примерно на 20 % больше среднего недельного прироста транзакций, чтобы избежать автогроу в пиковые часы.
Пример T‑SQL-скрипта для переноса одного из лог-файлов:
ALTER DATABASE [ИмяБД] MODIFY FILE (NAME = N’ИмяЛогическогоФайла’, FILENAME = N’E:\MSSQLLogs\ИмяБД_Log.ldf’);
DBCC SHRINKFILE (N’ИмяЛогическогоФайла’, 1024);
ALTER DATABASE [ИмяБД] SET OFFLINE;
ALTER DATABASE [ИмяБД] SET ONLINE;
Примените команду DBCC SQLPERF(LOGSPACE) для мониторинга заполнения: при достижении 80 % следует выполнить бэкап логов и оценить необходимость расширения тома. Рекомендуется автоматизировать проверку через SQL Agent Job раз в час.
При высокой нагрузке на журналы стоит рассмотреть Delayed Durability (режим ALWAYS или ALLOWED) для снижения синхронных задержек записи. Однако внедряйте этот режим только после тестирования на предмет потери данных и обеспечения требований RPO.
Использование компрессии данных для уменьшения объема записей
- Row Compression – минимизирует накладные расходы на хранение фиксированных полей (INT, DATETIME и т. д.), упрощая внутреннее представление.
- Page Compression – включает row compression и дополнительно использует повторное использование префиксов и слов (prefix, dictionary), сокращая повторяющиеся фрагменты.
Алгоритм внедрения:
- Оценка эффекта:
- Выполнить
sp_estimate_data_compression_savingsна целевых таблицах/индексах. - Сравнить результаты «page_compression» и «row_compression» по столбцам
compressed_page_countиsize_with_current_compression_setting.
- Выполнить
- Выбор режима:
- Если оценка показывает снижение размера ≥ 30 %, выбирать page compression.
- Иначе использовать row compression для минимального CPU‑overhead (~5 %).
- Применение:
- Для существующего индекса:
ALTER INDEX [ИмяИндекса] ON [Схема].[Таблица] REBUILD WITH (DATA_COMPRESSION = PAGE); - Новый кластерный индекс:
CREATE CLUSTERED INDEX [Имя] ON [Схема].[Таблица] (...) WITH (DATA_COMPRESSION = ROW);
- Для существующего индекса:
- Мониторинг:
- Отслеживать
avg_fragmentation_in_percentиpage_countвsys.dm_db_index_physical_stats. - Сравнивать статистику IO до и после:
sys.dm_io_virtual_file_stats.
- Отслеживать
- Учёт ресурсов:
- CPU‑нагрузка при page compression может вырасти на 10–20 %. Планировать операцию на «оконный» период.
- Рекомендован ночной «batch window» с ограничением
MAXDOP = 1для минимизации влияния на OLTP.
Примерный выигрыш: при page compression на таблице с 100 млн записей и размером 200 ГБ ожидаем сокращение до 120–140 ГБ и снижение операций чтения на 35 %. Применение row compression в среднем уменьшает объём на 15 %.
Настройка уровня изоляции транзакций для снижения блокировок
Уровень изоляции транзакций в MS SQL Server определяет, как данные, измененные одной транзакцией, будут видны другим. Он напрямую влияет на производительность, особенно на уровень блокировок, которые могут возникать при параллельном выполнении транзакций. Правильная настройка уровня изоляции помогает снизить количество блокировок и повысить производительность системы.
В MS SQL Server доступны следующие уровни изоляции:
- Read Uncommitted – позволяет читать данные, которые не были зафиксированы другими транзакциями. Это минимизирует блокировки, но может привести к чтению «грязных» данных, что недопустимо в большинстве случаев.
- Read Committed – позволяет читать только зафиксированные данные, но транзакции могут блокировать строки данных, с которыми работают другие транзакции. Это стандартный уровень изоляции в MS SQL Server.
- Repeatable Read – обеспечивает, чтобы данные, считанные транзакцией, не изменялись другими транзакциями до завершения первой. Этот уровень изоляции вызывает блокировки, но предотвращает фантомные чтения.
- Serializable – гарантирует максимальную изоляцию, блокируя все строки, которые могут быть затронуты транзакцией. Это самый строгий уровень изоляции, который минимизирует конкурентный доступ, но также увеличивает нагрузку на систему.
- Snapshot – использует версионность данных, позволяя транзакциям работать с консистентной версией данных без блокировок. Это снижает количество блокировок и повышает производительность, особенно в системах с высокими требованиями к параллельному выполнению транзакций.
Для снижения блокировок на практике стоит использовать уровень Read Committed Snapshot Isolation (RCSI) или Snapshot Isolation. Они позволяют избежать блокировок чтения, одновременно сохраняя консистентность данных. Однако важно помнить, что использование Snapshot требует дополнительной настройки базы данных и может увеличить нагрузку на систему из-за необходимости хранения версий данных.
Для включения RCSI в базе данных можно выполнить следующую команду:
ALTER DATABASE [имя_базы_данных] SET READ_COMMITTED_SNAPSHOT ON;
Это позволит транзакциям, работающим в режиме Read Committed, использовать снимки данных, что минимизирует блокировки при параллельной обработке запросов.
В некоторых сценариях, когда необходимы минимальные блокировки, уровень изоляции Read Uncommitted может быть полезен, однако его следует использовать с осторожностью, так как он позволяет читать «грязные» данные, что может привести к ошибкам и непредсказуемому поведению приложения.
Правильный выбор уровня изоляции зависит от конкретных требований к приложению и базы данных. Важно проводить тестирование на реальных данных, чтобы оценить влияние на производительность и блокировки. Настройка изоляции транзакций – это один из ключевых методов управления нагрузкой на диск и оптимизации работы с базой данных в MS SQL Server.
Вопрос-ответ:
Какие методы можно использовать для уменьшения нагрузки на диск в MS SQL Server?
Для снижения нагрузки на диск в MS SQL Server стоит обратить внимание на несколько аспектов. Во-первых, необходимо следить за правильной настройкой индексов. Неоптимизированные индексы могут создавать дополнительную нагрузку при запросах. Во-вторых, важно организовать правильное разделение данных на различные диски, особенно для журналов транзакций и данных. Это поможет распределить нагрузку и ускорить работу базы. Также стоит регулярно чистить логи транзакций и использовать архивирование данных, что поможет снизить объем хранения на основных дисках. Важно отслеживать и анализировать запросы, чтобы избежать чрезмерной загрузки дисков из-за неэффективных операций.
Как индексирование влияет на нагрузку на диск в SQL Server и как это можно улучшить?
Индексирование в SQL Server играет ключевую роль в ускорении выполнения запросов. Однако чрезмерное или неправильное использование индексов может привести к излишней нагрузке на диск, так как индексы требуют дополнительного места для хранения и обновления. Чтобы улучшить ситуацию, нужно анализировать существующие индексы, удалять неиспользуемые или дублирующие индексы, а также проверять их эффективность с помощью системных представлений, таких как `sys.dm_db_index_usage_stats`. Также рекомендуется выполнять регулярное дефрагментирование индексов, чтобы обеспечить их оптимальную работу и минимизировать излишние ресурсы.
Какую роль в снижении нагрузки на диск в MS SQL Server играют операции с журналами транзакций?
Журнал транзакций в MS SQL Server записывает все изменения в базе данных, что необходимо для обеспечения целостности данных и возможности восстановления после сбоев. Однако, если журнал транзакций не контролировать должным образом, его размер может существенно увеличиться, что приведет к дополнительной нагрузке на диск. Для решения этой проблемы важно регулярно выполнять резервное копирование журнала транзакций и настраивать правильный режим восстановления базы данных. Это поможет избежать излишнего накопления данных в журнале и обеспечит более эффективное использование дискового пространства.
Как можно организовать хранение данных и журналов на разных физических дисках для улучшения работы MS SQL Server?
Разделение данных и журналов транзакций на разные физические диски может значительно снизить нагрузку на каждый из них и улучшить общую производительность SQL Server. Лучше всего размещать файлы данных и журналы транзакций на отдельных дисках, чтобы операции записи в журнал не мешали операции чтения/записи данных. Можно использовать быстрые диски для журналов транзакций, так как они требуют высокой скорости записи. Для хранения данных подойдет более вместительный диск, на котором можно разместить таблицы и индексы. Такой подход позволяет уменьшить конкуренцию за ресурсы и повысить скорость выполнения запросов и транзакций.
Как регулярная оптимизация запросов помогает снизить нагрузку на диск в MS SQL Server?
Регулярная оптимизация запросов позволяет существенно снизить нагрузку на диск в SQL Server. Это связано с тем, что плохо оптимизированные запросы могут генерировать избыточное количество операций ввода-вывода (I/O), что сильно нагружает дисковую подсистему. Оптимизация может включать переписывание запросов для более эффективного использования индексов, устранение ненужных подзапросов, использование правильных типов данных и улучшение планов выполнения. Также важно следить за статистикой и анализировать планы выполнения запросов с помощью инструментов SQL Server, таких как `SQL Server Profiler` или `Execution Plan`, чтобы своевременно выявить и исправить проблемы.