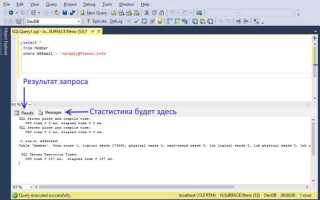
Одним из важнейших аспектов работы с базами данных является производительность SQL запросов. Проблемы с медленным выполнением запросов часто связаны с неэффективной структурой данных или неправильной настройкой запросов. Чтобы снизить время отклика системы, важно правильно настроить индексы, оптимизировать схемы таблиц и минимизировать количество операций в запросах.
Прежде всего, стоит обратить внимание на индексы. Они позволяют значительно ускорить поиск данных, однако чрезмерное количество индексов может замедлить операции вставки и обновления. Для ускорения выборок стоит использовать составные индексы, которые охватывают несколько колонок одновременно, особенно когда запросы часто используют несколько полей для фильтрации данных. Также важно регулярно проводить перестроение индексов, чтобы избежать фрагментации и улучшить их эффективность.
Не менее важным аспектом является правильное проектирование запросов. Для повышения их производительности следует избегать использования SELECT * и всегда указывать только те колонки, которые действительно необходимы. Дополнительно, использование JOIN должно быть оптимизировано, чтобы минимизировать количество соединений и данных, обрабатываемых в каждом шаге. Важно помнить, что использование подзапросов может существенно замедлить выполнение запроса, и их следует заменять на эффективные соединения или временные таблицы.
Одним из ключевых моментов оптимизации является кеширование. Использование кеширования запросов помогает снизить нагрузку на базу данных, так как повторяющиеся запросы могут быть обслужены непосредственно из памяти. Для этого стоит настроить кеширование на уровне базы данных или использовать сторонние решения, такие как Redis, для кеширования наиболее часто запрашиваемых данных.
Оптимизация индексов для ускорения поиска данных
Индексы играют ключевую роль в оптимизации запросов в базе данных, обеспечивая быстрый доступ к данным. Однако неправильное использование или отсутствие индексов может существенно замедлить выполнение запросов. Для достижения наилучших результатов важно понимать, когда и как их применять.
1. Выбор правильных столбцов для индексации: Не все столбцы требуют индексирования. Индексы следует создавать только для столбцов, по которым часто выполняются операции поиска, сортировки или фильтрации. Например, если запросы часто используют фильтрацию по полю «дата», индексирование этого поля ускорит поиск.
2. Использование составных индексов: Когда запросы часто включают несколько столбцов в условиях WHERE, создание составного индекса (индекса на несколько столбцов) может существенно ускорить выполнение таких запросов. Например, индекс на комбинацию полей «дата» и «категория» обеспечит более быстрый доступ, чем отдельные индексы на каждое поле.
3. Отказ от избыточных индексов: Избыточные индексы не только замедляют операции вставки и обновления данных, но и увеличивают объем хранимых данных. Проверьте наличие индексов, которые не используются в запросах, и удалите их. Использование команд анализа производительности, таких как EXPLAIN в MySQL или PostgreSQL, помогает выявить неэффективные индексы.
4. Использование уникальных индексов: Когда в столбце должны быть уникальные значения, создание уникального индекса позволяет не только ускорить поиск, но и гарантировать, что данные в столбце остаются уникальными. Это также ускоряет выполнение операций с данным столбцом в условиях сортировки.
5. Обновление статистики индексов: Важно следить за статистикой индексов, так как она влияет на план выполнения запроса. Регулярное обновление статистики помогает серверу базы данных эффективно использовать индексы для составления плана запроса. В большинстве СУБД есть команды для автоматического обновления статистики.
6. Параллельная обработка запросов: В современных СУБД существует возможность создания индексов, поддерживающих параллельную обработку. Это может значительно повысить производительность при выполнении запросов на больших объемах данных. Такие индексы могут использовать несколько ядер процессора для параллельной обработки поиска.
7. Оптимизация типов данных: Индексы могут работать быстрее, если столбцы имеют подходящий тип данных. Например, индекс на строке длиной 255 символов будет работать медленнее, чем индекс на числовом столбце. Выбор правильных типов данных помогает уменьшить размер индекса и улучшить скорость поиска.
8. Фрагментация индексов: Со временем индексы могут фрагментироваться, что снижает их эффективность. Регулярная реорганизация индексов помогает поддерживать их эффективность, особенно в системах с высоким уровнем операций вставки и удаления данных.
Использование ограничений и фильтров в запросах для уменьшения объема данных
- Ограничение выборки с помощью
LIMITилиTOP:
Использование операторовLIMIT(MySQL, PostgreSQL) илиTOP(SQL Server) позволяет задавать максимальное количество строк в результате запроса. Это особенно важно, когда нужно работать с большими наборами данных, но нужно только ограниченное количество строк для анализа или отображения. - Фильтрация данных с помощью
WHERE:
Использование фильтров в условииWHEREпомогает сократить объем данных, извлекаемых из таблицы. Важно применять фильтры по индексированным колонкам, чтобы запросы выполнялись быстрее. Например, фильтрация по дате или числовым диапазонам может значительно уменьшить количество строк в выборке. - Использование
JOINс фильтрами:
При работе с несколькими таблицами важно фильтровать данные до того, как они будут объединены. Это сокращает объем данных, которые нужно обрабатывать в процессе соединения. Рекомендуется сначала фильтровать данные в подзапросах, а затем выполнятьJOIN. - Использование
INиBETWEENдля более точной фильтрации:
ПрименениеINпозволяет эффективно фильтровать данные по множеству значений, аBETWEEN– по диапазону значений. Эти операторы часто быстрее, чем использование нескольких операторовOR, поскольку они оптимизируются на уровне исполнения запроса. - Фильтрация по индексированным полям:
Индексация значительных колонок ускоряет поиск и фильтрацию. Использование индексов на колонках, часто встречающихся в условияхWHERE, позволяет значительно уменьшить время выполнения запроса. Обратите внимание на необходимость правильной настройки индексов и регулярную их оптимизацию. - Ограничение столбцов:
Когда не требуется извлечение всех данных из таблицы, всегда указывайте только нужные столбцы вSELECT. Избыточный выбор колонок увеличивает объем передаваемых данных и нагрузку на систему.
Снижение объема данных на ранних этапах обработки запроса позволяет значительно улучшить его производительность. Важно помнить, что каждый запрос можно оптимизировать с учетом специфики базы данных, структуры данных и используемых индексов. В результате, правильно использованные фильтры и ограничения могут сократить время выполнения запросов и повысить общую производительность системы.
Правильный выбор типа данных и их длины для ускорения обработки
Выбор типа данных и их длины напрямую влияет на производительность SQL-запросов. Важно учитывать, что слишком большой размер данных или использование неподобающего типа могут существенно замедлить выполнение запросов и увеличить нагрузку на систему. Оптимизация начинается с правильного выбора типа данных, соответствующего реальным потребностям.
Первое, что нужно учитывать, это минимизация объема занимаемой памяти. Например, использование типа INT для хранения значений, которые могут быть представлены в пределах типа TINYINT, приводит к излишнему потреблению памяти. TINYINT занимает всего 1 байт, тогда как INT – 4 байта. В больших таблицах это может оказать значительное влияние на производительность. Подобные подходы применимы не только к числовым типам, но и к строковым данным.
Для строковых данных, таких как CHAR и VARCHAR, выбор между ними зависит от предполагаемой длины данных. Если длина строк в поле неизменна, следует использовать CHAR, так как оно всегда использует фиксированный размер, что ускоряет обработку запросов. В случае же, когда длина строк варьируется, предпочтительнее использовать VARCHAR, поскольку он экономит место, выделяя только необходимое количество памяти для каждого значения.
Определение правильной длины для строковых типов данных также критично. Например, если поле VARCHAR(255) используется для хранения строк длиной не более 50 символов, то это избыточно и увеличивает нагрузку на индексирование. Оптимальным будет выбор длины, которая соответствует реальным данным, например VARCHAR(50).
Не следует забывать и про типы для хранения дат и времени. Типы DATE, DATETIME и TIMESTAMP могут занять от 3 до 8 байт в зависимости от конкретной реализации. Для хранения времени, если точность до миллисекунд не требуется, лучше использовать DATE или TIME, так как они занимают меньше памяти и ускоряют операции сравнения и сортировки.
Также важно учитывать использование индексов. Для числовых типов данных и строк меньшей длины индексы создаются быстрее, так как с ними работает меньше данных. Применение индексов к полям с чрезмерной длиной строк или большими значениями может замедлить запросы на вставку и обновление, так как необходимо обновлять индекс, что требует дополнительных вычислительных ресурсов.
В конечном итоге, правильный выбор типа данных и их длины – это не просто вопрос экономии памяти, но и ключевая составляющая для улучшения производительности SQL-запросов. Правильно настроенная схема данных позволяет ускорить выполнение запросов, уменьшить нагрузку на сервер и обеспечить масштабируемость системы.
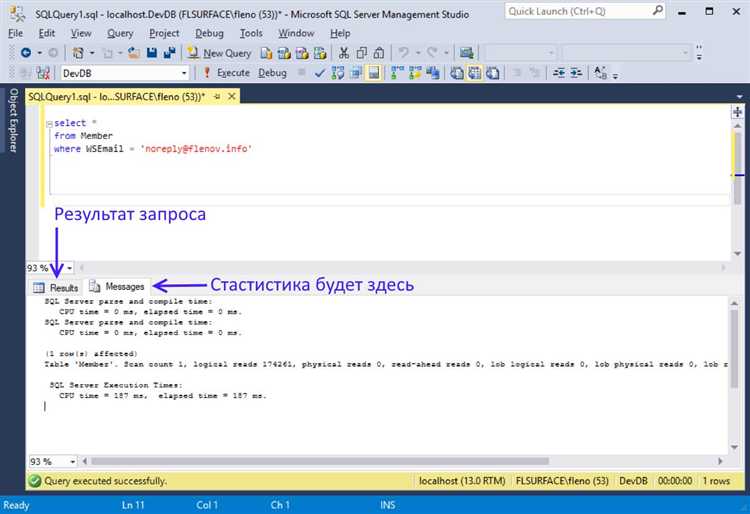
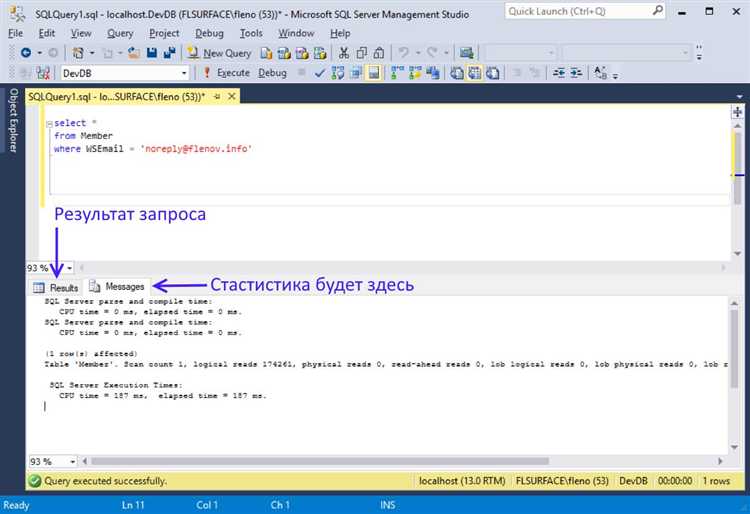
Как использовать EXPLAIN для анализа и улучшения выполнения запросов
Для начала, достаточно добавить перед запросом ключевое слово EXPLAIN. Пример: EXPLAIN SELECT * FROM orders WHERE customer_id = 123;. Результат будет содержать информацию о каждом шаге выполнения запроса, включая тип соединения, количество строк и использование индексов.
2. Использование индексов. EXPLAIN отображает, какой индекс используется в запросе. Если индекс не используется, стоит подумать о его создании для часто запрашиваемых колонок. Также важно следить за тем, чтобы индексы были актуальными и не избыточными. Использование более одного индекса на таблице может привести к излишним накладным расходам.
3. Количество строк. Столбец «rows» показывает, сколько строк планируется обработать на каждом этапе выполнения запроса. Чем больше строк, тем дольше будет выполняться запрос. Это может быть индикатором того, что индексы недостаточно эффективны или что фильтры запроса не оптимальны.
4. Доступ к данным (Filtered). Значение в этом столбце указывает на процент строк, которые были отфильтрованы на этом этапе выполнения. Если это значение близко к 100%, это может означать, что база данных должна просматривать множество ненужных строк, что замедляет выполнение. В таких случаях оптимизация запросов и индексация помогут сократить количество обрабатываемых строк.
5. Дополнительные фильтры и операции. Важно анализировать дополнительные операции, такие как сортировка (Sort) или агрегация (Aggregation). Они могут существенно замедлить запрос, особенно если нет соответствующих индексов для полей, участвующих в этих операциях. Использование индексов для сортировки или группировки может ускорить выполнение.
Регулярно использовать EXPLAIN на практике важно, чтобы выявить возможности для улучшения, даже если запросы кажутся быстрыми. С каждым изменением в структуре данных или бизнес-логике запросов производительность может измениться, и EXPLAIN поможет отслеживать эти изменения.
Разделение больших запросов на меньшие для повышения скорости выполнения
Процесс разделения заключается в разбивке запросов на несколько логических частей, которые могут быть выполнены параллельно или поочередно, в зависимости от конкретной ситуации. Например, если запрос включает в себя сложные объединения (JOIN) нескольких таблиц или большое количество данных, то можно разделить его на несколько частей, каждая из которых будет обрабатывать только часть данных. Такой подход позволяет избежать перегрузки и ускорить выполнение.
Для этого можно использовать подзапросы или временные таблицы. Разбивка на подзапросы позволяет обрабатывать данные в несколько этапов, а затем результаты каждого этапа объединяются в финальный результат. В случае с временными таблицами данные могут быть сохранены на промежуточных этапах, что снижает нагрузку на основную таблицу и уменьшает время отклика запросов.
Примером такого подхода может быть использование операции UNION для объединения результатов нескольких запросов. Вместо того, чтобы делать один запрос на все данные, можно выполнить несколько запросов для разных диапазонов значений и затем объединить их результаты. Это также помогает уменьшить нагрузку на сервер, особенно если данные могут быть разделены по ключевым аттрибутам или диапазонам времени.
Не стоит забывать о возможности оптимизации через индексы. Разделение запроса на части может быть более эффективным, если каждая часть запроса будет использовать свой набор индексов. Это позволяет уменьшить время поиска данных и повысить общую производительность выполнения запросов.
Кроме того, важно учитывать логику выполнения. Для некоторых операций, таких как агрегации (SUM, AVG и т.д.), разделение запроса на меньшие части может значительно ускорить выполнение, так как вычисления будут производиться на меньших объемах данных. Результаты промежуточных запросов можно будет агрегировать в финальный результат.
Такой подход требует внимательности при проектировании запросов, так как слишком мелкое деление может привести к излишнему количеству операций, а слишком крупные части – снова к потерям в производительности. Баланс между размерами запросов и общей нагрузкой на сервер является ключевым для успешной реализации стратегии разделения запросов.
Использование кэширования запросов для снижения нагрузки на базу данных

Кэширование запросов позволяет значительно ускорить выполнение повторных запросов и снизить нагрузку на базу данных. При правильной настройке кэширование может минимизировать необходимость выполнения сложных операций каждый раз, когда поступает запрос с одинаковыми параметрами.
Одним из основных преимуществ кэширования является сокращение времени отклика, так как данные, которые уже были запрошены и сохранены в кэше, могут быть возвращены гораздо быстрее, чем при повторном выполнении запроса к базе данных.
Методы кэширования запросов
- Кэширование на уровне приложения: Запросы к базе данных выполняются один раз, и результаты сохраняются в памяти приложения. Пример – использование Redis или Memcached. Это позволяет избежать излишних запросов, пока данные не изменятся.
- Кэширование на уровне СУБД: Некоторые СУБД, такие как MySQL или PostgreSQL, предоставляют встроенные механизмы кэширования запросов. Это обычно включает кэширование результатов SELECT-запросов или кэширование планов выполнения запросов.
- Кэширование на уровне веб-сервера: Кэширование результатов на уровне веб-сервера или прокси-сервера (например, Varnish или Nginx) помогает уменьшить нагрузку на базу данных, особенно при работе с часто запрашиваемыми данными.
Рекомендации по эффективному кэшированию
- Выбор правильных данных для кэширования: Кэшировать следует только те данные, которые часто запрашиваются и не меняются часто. Это могут быть статические отчёты, результаты агрегаций или данные, которые имеют долгий срок жизни.
- Настройка времени жизни кэша: Установите разумное время жизни (TTL) для кэша, чтобы избежать использования устаревших данных. Для данных, которые часто обновляются, TTL должен быть минимальным.
- Очистка устаревших данных: Важно внедрить механизм удаления устаревших данных из кэша, чтобы избежать переполнения и ухудшения производительности. Это можно делать как по расписанию, так и на основе определённых триггеров.
- Разделение кэша по типам запросов: Разделите кэшированные данные на различные категории в зависимости от типа запросов и их важности. Это позволит точнее управлять кэшированием и улучшить производительность при различных типах нагрузки.
Когда не стоит использовать кэширование
- Если данные изменяются слишком часто, и кеширование не оправдывает себя.
- При работе с небольшими объёмами данных, где накладные расходы на кэширование могут быть выше, чем выгоды от него.
- Если есть высокая вероятность того, что кэшированные данные могут стать источником ошибок или несоответствий.
Заключение

Использование кэширования запросов – эффективный способ улучшить производительность системы и снизить нагрузку на базу данных. Однако необходимо тщательно подходить к выбору данных для кэширования, настроить время жизни кэша и мониторить актуальность хранимых данных для достижения максимальной эффективности.
Настройка параметров базы данных для повышения производительности
1. Память и кэширование
Один из ключевых параметров – это размер буферного кеша. В большинстве СУБД этот параметр называется innodb_buffer_pool_size (для MySQL) или shared_buffers (для PostgreSQL). Он определяет объём памяти, выделенной для хранения данных, что влияет на скорость выполнения запросов. Увеличение этого значения позволяет СУБД работать с данными в памяти, минимизируя обращения к диску. Рекомендуется установить его в 70-80% от общего объёма оперативной памяти, если на сервере работает только база данных.
3. Индексы
Индексы значительно ускоряют поиск и выборку данных, но их неправильная настройка может ухудшить производительность. Важно использовать индексы для часто выполняемых запросов, например, для колонок, которые часто участвуют в условиях WHERE или используются в операциях JOIN. Параметры типа innodb_large_prefix (для MySQL) могут быть полезны для оптимизации работы с длинными индексами. Также стоит учитывать настройки уникальности индексов и их восстановление после сбоев, что может влиять на время выполнения запросов.
4. Конкурентность и блокировки
Настройка уровней изоляции транзакций и параметров блокировок имеет важное значение для производительности при высокой нагрузке. В MySQL параметры innodb_lock_wait_timeout и innodb_deadlock_detect могут быть использованы для настройки таймаутов ожидания блокировок и автоматического обнаружения взаимных блокировок, что снижает вероятность возникновения задержек в выполнении запросов. В PostgreSQL параметры lock_timeout и statement_timeout позволяют контролировать время ожидания блокировок и выполнение долгих запросов соответственно.
5. Настройка параллельных операций
Для улучшения производительности на многозадачных системах важно настроить использование параллельных процессов. В PostgreSQL параметры max_parallel_workers и max_parallel_workers_per_gather контролируют количество потоков, которые могут работать параллельно при выполнении запросов. Эти настройки могут значительно ускорить выполнение запросов, особенно при обработке больших объёмов данных. В MySQL параллельные запросы также поддерживаются, но для их настройки необходимо учитывать версию СУБД и возможности оборудования.
6. Параметры журналирования
Параметры журналирования также оказывают влияние на производительность. В MySQL и PostgreSQL важным параметром является уровень журналирования запросов. В PostgreSQL можно настроить log_statement для записи только важных запросов, что снижает нагрузку на систему. В MySQL важно правильно настроить slow_query_log, чтобы фиксировать только те запросы, которые требуют оптимизации.
Внесение изменений в параметры базы данных требует тщательного мониторинга и тестирования, поскольку некорректные настройки могут вызвать непредсказуемое поведение системы. Регулярное профилирование и настройка под текущие задачи позволяют достичь максимальной производительности.
Вопрос-ответ:
Как уменьшить время выполнения SQL запросов?
Для ускорения работы SQL запросов необходимо сначала проанализировать текущие запросы и их структуру. Один из первых шагов – это использование индексов для часто запрашиваемых колонок. Индексы помогают сократить время поиска данных в таблицах. Также стоит обратить внимание на оптимизацию самих запросов: например, избегать использования подзапросов, если можно использовать JOIN. Еще одна важная практика – уменьшение количества данных, которые обрабатываются запросом, с помощью фильтрации на уровне WHERE.
Какие индексы стоит использовать для ускорения работы с базой данных?
Для ускорения работы запросов можно использовать несколько типов индексов. Наиболее популярным является B-tree индекс, который идеально подходит для большинства запросов, включающих операторы сравнения (например, <, >, =). Также полезным может быть использование индексов на колонках, часто использующихся в операциях JOIN или WHERE. В некоторых случаях стоит рассмотреть использование полнотекстовых индексов для текстовых данных или индексирования дат для временных диапазонов. Важно также регулярно пересматривать актуальность индексов, чтобы избежать их избыточности и ненужных затрат на хранение.
Почему запросы могут работать медленно, если данные в таблице увеличиваются?
Когда объем данных в таблице увеличивается, производительность запросов может значительно снизиться из-за того, что базам данных становится сложнее обрабатывать запросы на больших объемах информации. Причины могут заключаться в отсутствии индексов на часто используемых колонках, необходимости сканирования всей таблицы при выполнении запроса, а также в том, что статистика базы данных может устаревать, что влияет на выбор оптимального плана выполнения запроса. Рекомендуется регулярно обновлять статистику базы данных, а также использовать партиционирование таблиц, чтобы разделить данные на более мелкие и легко управляемые части.
Как определить, какой запрос замедляет работу базы данных?
Для поиска медленных запросов можно использовать инструменты профилирования базы данных, такие как EXPLAIN в MySQL или SQL Server Profiler. Они позволяют увидеть, какой именно запрос занимает больше всего времени на выполнение, а также какие индексы или операции используются. Также стоит обратить внимание на запросы, которые часто выполняются, но не приносят нужных результатов (например, большие объединения или запросы без фильтрации). Если база данных поддерживает логи выполнения, можно анализировать их для выявления повторяющихся или долгих операций.