При обработке больших объемов данных в SQL часто возникает необходимость выполнить повторяющиеся операции для нескольких записей. Стандартный SQL не поддерживает явные циклы, как в других языках программирования, однако существуют различные подходы для реализации цикличности с помощью доступных инструментов, таких как процедуры и функции.
Хранимые процедуры и циклические конструкции позволяют обрабатывать данные в цикле, например, для выполнения операций обновления, вставки или удаления строк в зависимости от состояния данных. Наиболее распространенным способом организации цикла в SQL является использование конструкции WHILE, которая выполняет блок команд до тех пор, пока не выполняется заданное условие.
Для примера, в SQL Server или MySQL можно создать цикл, который будет обрабатывать записи, начиная с первой и заканчивая последней, обновляя значения в таблице по определенному алгоритму. Однако важно учитывать, что циклические операции могут значительно увеличить время выполнения запросов, особенно на больших объемах данных. В таких случаях стоит оптимизировать структуру запросов и рассматривать возможность выполнения операций пакетно.
Кроме того, для работы с циклическими операциями можно использовать курсоры, которые обеспечивают построчную обработку данных. Это позволяет пройтись по всем строкам результата запроса и выполнить необходимые действия. Несмотря на это, курсоры могут быть менее эффективными в сравнении с массовыми операциями, поскольку требуют больше ресурсов для работы с каждым отдельным элементом.
При организации циклов в SQL важно всегда помнить о возможности оптимизации работы с данными. Интенсивное использование циклов может приводить к значительным нагрузкам на сервер, поэтому часто целесообразнее искать альтернативные способы обработки, такие как использование агрегатных функций или выполнение операций пакетно, а не построчно.
Как использовать конструкцию WHILE для циклической обработки данных
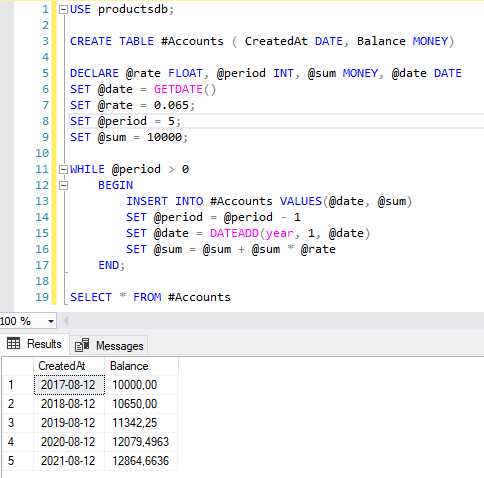
Конструкция WHILE в SQL позволяет выполнять повторяющиеся операции, пока выполняется заданное условие. Она полезна для обработки данных в случаях, когда количество итераций заранее неизвестно, а условие завершения цикла зависит от результата промежуточных вычислений.
Основной синтаксис конструкции WHILE следующий:
WHILE <условие> BEGIN -- SQL-операторы END
Пример использования WHILE для итерации по записям таблицы:
DECLARE @counter INT = 1; DECLARE @max INT; SELECT @max = COUNT(*) FROM Employees; WHILE @counter <= @max BEGIN -- Здесь выполняется обработка данных для каждой записи PRINT 'Обрабатываем запись номер ' + CAST(@counter AS VARCHAR); scssEditSET @counter = @counter + 1; END
Этот цикл будет выполняться до тех пор, пока переменная @counter не достигнет значения переменной @max, которая определяет общее количество записей в таблице Employees.
Некоторые важные моменты при использовании WHILE:
- Каждый цикл должен изменять состояние переменных, чтобы избежать бесконечного выполнения.
- Важно контролировать условия выхода из цикла, чтобы предотвратить блокировку базы данных.
- Использование WHILE может повлиять на производительность, особенно при обработке большого объема данных.
Оптимизация выполнения цикла:
- Используйте индексы для улучшения производительности выборки данных перед циклом.
- Если необходимо выполнить сложные вычисления в цикле, постарайтесь минимизировать количество операций внутри каждого шага.
- Для больших объемов данных рассмотрите возможность использования пакетной обработки, разбивая цикл на несколько частей.
Пример с условием остановки по конкретному результату:
DECLARE @counter INT = 1; DECLARE @max INT; DECLARE @result INT; SELECT @max = COUNT(*) FROM Employees; WHILE @counter <= @max BEGIN SELECT @result = Salary FROM Employees WHERE EmployeeID = @counter; sqlEditIF @result > 100000 BEGIN PRINT 'Сотрудник с ID ' + CAST(@counter AS VARCHAR) + ' имеет зарплату выше 100000'; BREAK; END SET @counter = @counter + 1; END
Этот пример завершит выполнение цикла, если будет найден сотрудник с зарплатой более 100000. Использование команды BREAK позволяет досрочно завершить цикл, если выполнены необходимые условия.
Применение оператора CONTINUE для пропуска итераций в SQL-цикле
Оператор CONTINUE используется в SQL для пропуска текущей итерации цикла и перехода к следующей. Это полезно, когда необходимо пропустить обработку некоторых данных на основе определённых условий без выхода из цикла.
Применение CONTINUE особенно важно в случаях, когда обработка данных требует пропуска определённых шагов, например, когда значения в столбцах не удовлетворяют заданным критериям или когда необходимо пропустить пустые строки.
Пример использования CONTINUE
Предположим, что необходимо обработать таблицу с данными о продажах, но игнорировать записи с нулевыми или отрицательными значениями по полю amount. В этом случае оператор CONTINUE будет пропускать такие строки, ускоряя выполнение цикла и избегая ненужных вычислений.
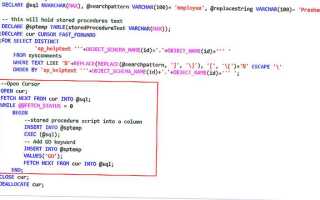
DECLARE @SaleAmount INT
DECLARE @SaleCursor CURSOR FOR
SELECT amount FROM sales
OPEN @SaleCursor
FETCH NEXT FROM @SaleCursor INTO @SaleAmount
WHILE @@FETCH_STATUS = 0
BEGIN
IF @SaleAmount <= 0
BEGIN
FETCH NEXT FROM @SaleCursor INTO @SaleAmount
CONTINUE
END
-- Здесь выполняется обработка данных, если значение положительное
PRINT 'Обрабатываю продажу на сумму: ' + CAST(@SaleAmount AS VARCHAR)
FETCH NEXT FROM @SaleCursor INTO @SaleAmount
END
CLOSE @SaleCursor
DEALLOCATE @SaleCursor
В приведённом примере, если значение поля amount меньше или равно нулю, оператор CONTINUE пропускает текущую итерацию и переходит к следующей строке. Это позволяет избежать ненужной обработки данных и улучшить производительность.
Рекомендации по использованию CONTINUE
- Использование с условиями: Оператор
CONTINUEдолжен применяться в блоках с условием, чтобы избежать ненужного пропуска итераций по незначительным причинам. - Чёткая логика условий: Убедитесь, что условие для пропуска итерации правильно настроено, чтобы избежать случайных пропусков важных данных.
- Оптимизация циклов:
CONTINUEпозволяет ускорить выполнение циклов, особенно когда часть данных не требует обработки.
Когда не использовать CONTINUE
- Излишнее использование: Частое применение
CONTINUEможет привести к сложной логике и затруднить поддержку кода. - Ошибки в логике: Если условие для пропуска итерации некорректно, это может привести к пропуску важных шагов или даже к неправильным результатам.
Как управлять условием завершения цикла с помощью BREAK в SQL
Оператор BREAK в SQL используется для немедленного завершения выполнения цикла, независимо от того, достигнут ли его предел или нет. Этот оператор часто применяют для оптимизации работы с данными, когда выполнение цикла больше не имеет смысла по каким-либо условиям.
Основная цель применения BREAK – это избегание лишней обработки данных и ускорение выполнения запросов. Например, если в процессе обработки данных найдено условие, которое делает дальнейшее выполнение цикла избыточным или ненужным, BREAK позволяет прекратить итерации до окончания всех шагов.
Пример использования BREAK в SQL:
DECLARE @Counter INT = 1; WHILE @Counter <= 100 BEGIN IF @Counter = 50 BEGIN BREAK; END PRINT @Counter; SET @Counter = @Counter + 1; END
В данном примере цикл будет завершён на 50-й итерации, после чего дальнейшие шаги не выполняются. Это значительно экономит ресурсы, если условия для прекращения цикла могут быть предсказаны заранее.
Основные рекомендации при использовании BREAK:
- Применяйте
BREAKдля ускорения обработки больших объемов данных, если вы знаете, что после определённого условия дальнейшее выполнение цикла не имеет смысла. - Не злоупотребляйте
BREAKв циклах с малым количеством итераций, так как это может привести к излишней сложности кода. - Используйте
BREAKв сочетании с чёткими условиями для контроля логики выполнения цикла.
Важно помнить, что после выполнения оператора BREAK цикл завершится, и любые действия после оператора уже не будут выполнены. В случае необходимости можно использовать дополнительные проверки, чтобы убедиться, что цикл завершился корректно и обработка данных была выполнена полностью.
Заключение: BREAK – мощный инструмент для управления логикой работы цикла в SQL. Его правильное использование позволяет ускорить процесс обработки данных и сделать код более читабельным и эффективным.
Как использовать курсоры для работы с большими наборами данных в цикле
Курсоры в SQL позволяют обрабатывать строки набора данных по одной или нескольким за раз, что делает их полезными при работе с большими объемами информации. Особенно это актуально для операций, которые требуют последовательной обработки записей, например, при выполнении сложных вычислений или изменении данных в базе.
Основной принцип работы курсора заключается в том, что он «перемещается» по результатам запроса и предоставляет доступ к каждой строке для выполнения операций. Это особенно полезно в случае, когда нельзя или нецелесообразно загрузить весь набор данных в память сразу. Курсор позволяет обрабатывать строки по одной, минимизируя нагрузку на память.
Для использования курсора в SQL нужно выполнить несколько шагов: объявить курсор, открыть его, обработать данные, а затем закрыть и освободить ресурсы. Рассмотрим процесс на примере простого сценария.
1. Объявление курсора – в этом шаге указывается SQL-запрос, результаты которого будут обрабатываться. Например:
DECLARE my_cursor CURSOR FOR
SELECT id, name FROM employees WHERE department = 'Sales';
2. Открытие курсора – после того как курсор объявлен, его необходимо открыть для извлечения данных:
OPEN my_cursor;
3. Обработка данных – данные из курсора извлекаются построчно в цикле. Это можно сделать с помощью оператора FETCH:
FETCH NEXT FROM my_cursor INTO @id, @name;
WHILE @@FETCH_STATUS = 0
BEGIN
-- здесь выполняется обработка данных
PRINT @name; -- пример обработки данных
FETCH NEXT FROM my_cursor INTO @id, @name;
END
4. Закрытие и освобождение ресурсов – после завершения обработки данных важно закрыть курсор и освободить ресурсы:
CLOSE my_cursor;
DEALLOCATE my_cursor;
При использовании курсоров важно помнить, что они могут негативно влиять на производительность, особенно при обработке очень больших наборов данных. Для минимизации таких рисков следует ограничивать количество данных, обрабатываемых курсором за один раз, а также оптимизировать SQL-запросы, на основе которых курсор извлекает данные.
Одним из важных аспектов является правильное закрытие курсора. Не закрытый курсор может привести к утечке памяти и блокировке ресурсов. Рекомендуется всегда использовать пару операторов `CLOSE` и `DEALLOCATE` для завершения работы с курсором.
Также стоит учитывать, что курсоры не всегда являются лучшим выбором для всех типов задач. В случае, когда операции можно выполнить с помощью одномоментных операций SQL, таких как UPDATE или INSERT с использованием условий и JOIN-ов, курсоры могут быть заменены более эффективными решениями.
Если курсор все же необходим, можно рассмотреть альтернативы, такие как использование временных таблиц или Common Table Expressions (CTE), которые позволяют выполнять похожие операции, но могут быть более эффективными с точки зрения производительности.
Как реализовать циклическую обработку с использованием временных таблиц
Для реализации циклической обработки данных в SQL с использованием временных таблиц можно создать механизм, который будет хранить промежуточные результаты и позволять их обрабатывать поэтапно. Такой подход помогает минимизировать нагрузку на основную базу данных и ускорить выполнение операций.
Сначала создаём временную таблицу, которая будет использоваться для хранения промежуточных данных. В SQL это можно сделать с помощью команды CREATE TABLE #temp_table (...), где # указывает на временную таблицу, существующую только в течение сессии. Например:
CREATE TABLE #temp_table (
id INT PRIMARY KEY,
value INT
);Далее, необходимо загрузить начальные данные в временную таблицу. Это может быть сделано через обычный INSERT INTO, выбрав нужные данные из основной таблицы:
INSERT INTO #temp_table (id, value)
SELECT id, value FROM main_table WHERE condition;После этого, для циклической обработки данных, используем конструкцию WHILE. Например, можно обновлять значения в таблице поочередно, используя идентификаторы или другие ключевые параметры:
DECLARE @counter INT = 1;
DECLARE @max_id INT;
SELECT @max_id = MAX(id) FROM #temp_table;
WHILE @counter <= @max_id
BEGIN
UPDATE #temp_table
SET value = value * 2
WHERE id = @counter;
SET @counter = @counter + 1;
END;Цикл будет продолжаться до тех пор, пока не обработаются все строки в таблице. Это позволяет гибко изменять логику обработки и обновлять данные поэтапно. Такой подход удобно использовать для различных сценариев, например, для вычислений, обновлений статусов или перемещения данных между таблицами.
Важно отметить, что работа с временными таблицами может быть полезной, когда нужно ограничить область видимости промежуточных данных и не нагружать основную базу. После завершения работы с временной таблицей она автоматически удаляется, но также можно использовать DROP TABLE #temp_table для явного удаления, если необходимо.
Преимущества такого подхода заключаются в повышении производительности за счет минимизации блокировок и меньшей нагрузке на систему в целом, а также в возможности гибкой настройки обработки данных с использованием вспомогательных структур.
Как отлаживать SQL-циклы и предотвращать их бесконечное выполнение
Для отладки SQL-циклов важно заранее определить возможные точки выхода из цикла и убедиться, что они срабатывают в каждом случае. Один из основных методов – использование условия завершения, которое должно быть проверено на каждом шаге цикла. Например, если цикл работает с данными, которые могут изменяться, стоит добавлять дополнительные проверки, чтобы убедиться, что данные не приводят к зацикливанию.
Если цикл предназначен для обработки данных в таблице, убедитесь, что в запросе используется правильный механизм обновления или вставки данных. Одним из методов защиты от бесконечного выполнения является ограничение количества итераций. Например, можно ввести переменную-счётчик, которая будет увеличиваться при каждом цикле, и задать максимально допустимое значение. Если счётчик превышает это значение, цикл прекращает выполнение.
Проблемы могут возникать при обновлении данных внутри самого цикла, когда обновление одного поля может повлиять на другие строки, что может вызвать зацикливание. В этом случае стоит использовать подзапросы или временные таблицы для изоляции данных от основной логики цикла.
Для повышения надежности и предотвращения бесконечного выполнения необходимо записывать логи на каждом шаге цикла. В логе можно отслеживать, какие данные были обработаны, и на каком шаге произошла ошибка или зацикливание. Это поможет быстро выявить узкие места в логике цикла.
Если цикл зависит от динамически меняющихся данных, важно использовать блокировки или транзакции, чтобы избежать ситуации, при которой другие операции могут повлиять на выполнение цикла. Применение блокировок обеспечит целостность данных и предотвратит возможные гонки за ресурсами.
Наконец, рекомендуется периодически тестировать цикл на наборе данных с различной структурой и объемом. Это позволит выявить ошибки, которые могут быть неочевидными при работе с реальными данными. Важно помнить, что цикл, который работает на тестовых данных, не всегда будет корректно работать на реальных данных, поэтому тщательная проверка на всех этапах разработки критична для предотвращения бесконечных циклов.
Вопрос-ответ:
Что такое цикл в SQL и зачем его использовать для обработки данных?
Цикл в SQL — это структура, которая позволяет повторять одну и ту же операцию несколько раз, пока не будет выполнено какое-то условие. Использование цикла важно, когда нужно обработать большие объемы данных, провести множественные вычисления или выполнить похожие действия несколько раз. Однако в SQL стандартно нет прямых циклов, как, например, в языках программирования, поэтому такие действия можно реализовывать с помощью конструкций типа WHILE, FOR или с использованием курсоров.
Когда использование курсоров в SQL оправдано при обработке данных?
Курсоры в SQL применяются, когда необходимо обрабатывать строки данных поочередно, например, при выполнении операций, требующих обращения к каждой строке отдельно. Это может быть необходимо, когда невозможно выполнить операцию на всех строках одновременно, или когда обработка данных требует состояния между итерациями. Однако курсоры могут быть менее эффективными, чем другие методы, так как они замедляют выполнение запросов, особенно при большом объеме данных.
Можно ли использовать цикл в SQL для обработки нескольких таблиц одновременно?
В SQL можно использовать цикл для обработки нескольких таблиц, но это требует определенной логики, так как SQL не предоставляет встроенных механизмов для итерации по таблицам. Один из вариантов — это использовать несколько вложенных циклов для каждой таблицы, либо объединять данные из нескольких таблиц в одном запросе, используя JOIN, и уже затем обрабатывать эти объединенные данные. Однако, если таблицы сильно различаются по структуре, то лучше использовать подход с курсорами или хранить логику на уровне программного кода, а не в SQL-запросах.
Какие возможные проблемы могут возникнуть при использовании цикла в SQL для обработки данных?
Одной из главных проблем при использовании цикла в SQL может быть производительность. Циклы могут значительно замедлить выполнение запросов, особенно при большом объеме данных. Это связано с тем, что каждый шаг цикла требует отдельного выполнения запроса или действия. Также при неправильной настройке условия выхода из цикла можно столкнуться с бесконечным циклом, который не завершится. Для улучшения производительности рекомендуется минимизировать использование циклов и по возможности заменить их на операции с набором данных, такие как операции с JOIN или агрегатные функции.