

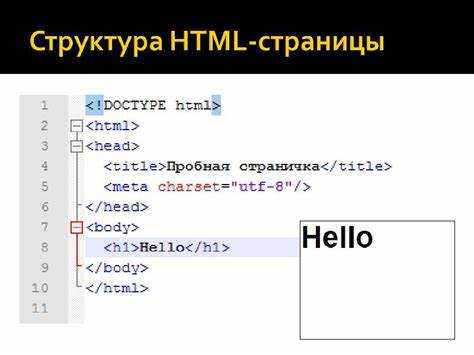
Перевод HTML кода в текстовый формат может быть полезным при необходимости извлечь или отобразить только текстовую информацию, без элементов форматирования, ссылок и других HTML-структур. Этот процесс бывает необходим при обработке веб-страниц, а также в случае, если нужно сохранить чистый текст для последующей работы, например, для парсинга или индексации. Простой HTML-код можно преобразовать в текстовый формат с помощью нескольких инструментов и методов.
Основной задачей при переводе HTML в текст является удаление всех тегов, оставив лишь содержимое внутри них. Существует несколько подходов для этого: от использования специализированных онлайн-инструментов до применения языков программирования, таких как Python, с библиотеками для работы с HTML. Один из самых популярных способов – это использование регулярных выражений, которые могут быстро извлечь только текст, игнорируя HTML-теги.
Если задача заключается в преобразовании HTML в текст без использования программирования, можно использовать различные онлайн-сервисы, которые автоматически очищают код от тегов. Для более точного контроля и автоматизации процесса можно применить язык Python с библиотеками BeautifulSoup или lxml, которые позволяют эффективно обрабатывать и извлекать текст из HTML-структур. Важно помнить, что результат обработки зависит от корректности кода HTML, а также от использования правильно настроенных инструментов.
Использование стандартных функций браузера для копирования текста
Для более продвинутых пользователей есть возможность копировать текст через консоль разработчика. Включив инструменты разработчика (обычно это можно сделать через F12 или правый клик – «Исследовать элемент»), можно найти нужный текст в структуре HTML и вручную скопировать его из кода. Это полезно, если текст скрыт стилями или JavaScript-сценариями.
В браузерах на основе Chromium (например, Google Chrome) также доступна функция «Копировать как HTML». Это позволяет не только сохранить текст, но и всю его разметку, что полезно при переносе контента в другие редакторы или системы управления контентом.
Для автоматизации этого процесса можно использовать расширения или встроенные скрипты. Например, с помощью JavaScript можно создать собственный механизм для копирования, чтобы извлечь текст из определённых блоков на странице. С помощью команды document.execCommand('copy') можно автоматически скопировать выделенный текст в буфер обмена.
Также стоит отметить, что многие сайты ограничивают возможность копирования контента, применяя различные механизмы защиты. Например, некоторые страницы могут блокировать контекстное меню или использовать JavaScript для блокировки стандартных функций копирования. В таких случаях важно уважать права владельцев контента и не нарушать правила использования.
Как извлечь текст из HTML с помощью инструментов разработчика

Для извлечения текста из HTML-кода с использованием инструментов разработчика можно использовать встроенные функции современных браузеров. Они позволяют быстро получить доступ к содержимому страницы и манипулировать элементами.
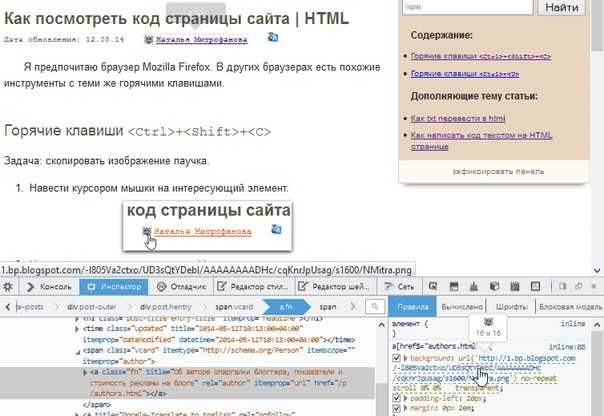
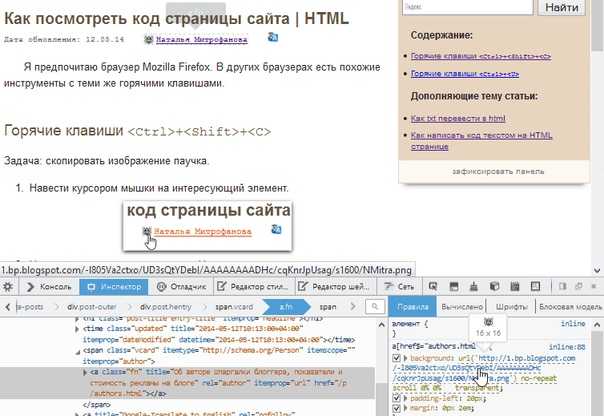
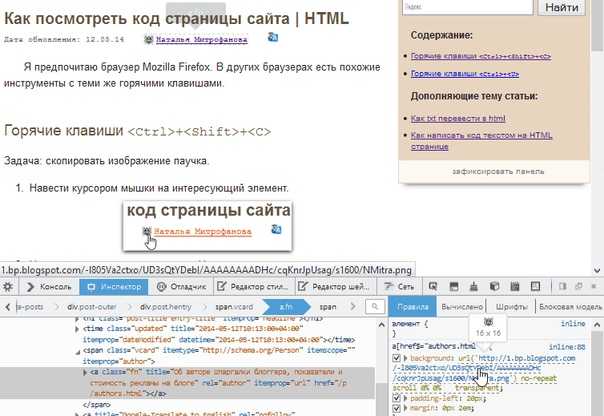
Шаг 1: Откройте веб-страницу в браузере и вызовите инструменты разработчика. Для этого используйте сочетания клавиш: F12 или Ctrl+Shift+I (в Chrome, Firefox, Edge). В открывшемся окне выберите вкладку Elements, где отображается структура HTML-кода.
Шаг 2: Найдите элемент, содержащий нужный текст. Для этого можно использовать инструмент Выбор элемента (иконка в виде стрелки в левом верхнем углу панели инструментов). Наведите курсор на нужную область страницы и кликните, чтобы увидеть соответствующий элемент в структуре HTML.
Шаг 3: Когда элемент выбран, вы сможете увидеть его разметку в панели Elements. Выделите текст внутри тега, который вам нужен, и скопируйте его. Чтобы скопировать только текст, а не HTML-разметку, можно использовать контекстное меню и выбрать пункт «Copy Inner Text» (или аналогичный).
Шаг 4: Для извлечения текста с нескольких элементов одновременно, можно использовать консоль JavaScript. Откройте вкладку Console и используйте команду document.querySelectorAll для поиска всех нужных элементов. Пример:
document.querySelectorAll('p').forEach(function(element) {
console.log(element.innerText);
});Этот код выведет текст из всех параграфов на странице. Вы можете адаптировать его для поиска других элементов, заменив селектор ‘p’ на нужный.
Шаг 5: Важно помнить, что инструменты разработчика могут извлекать только видимый текст. Текст, скрытый с помощью CSS (например, с использованием display: none;), не будет доступен через эти методы.
Применение регулярных выражений для извлечения текста
Регулярные выражения – мощный инструмент для поиска и извлечения информации из HTML-кода. При необходимости перевести HTML в текстовый формат, регулярные выражения позволяют быстро удалить теги и извлечь только текстовые данные.
Для извлечения текста из HTML можно использовать следующий шаблон регулярного выражения: <[^>]*>. Этот шаблон находит все HTML-теги и заменяет их на пустую строку, оставляя только текст между ними. Пример на языке Python:
import re
html = "<div>Пример текста</div>"
text = re.sub(r"<[^>]*>", "", html)
print(text) # Выведет: Пример текста
Важно учитывать, что регулярные выражения не всегда могут учесть все особенности HTML-кода. Например, если HTML содержит сложные конструкции, такие как скрипты или стили, которые также нужно исключить, можно использовать более сложные шаблоны, например:
html = "<style>body {color: red;}</style><p>Текст</p>"
text = re.sub(r"<[^>]*(style|script)[^>]*>.*?</\1>", "", html)
text = re.sub(r"<[^>]*>", "", text)
print(text) # Выведет: Текст
Использование флагов, таких как re.DOTALL в Python, позволяет обрабатывать текст с многострочными тегами. Для извлечения специфических данных, таких как ссылки или изображения, можно использовать регулярные выражения с конкретными паттернами, например, для извлечения всех URL из атрибутов href:
html = "<a href='https://example.com'>Ссылка</a>"
urls = re.findall(r'href=[\'"](.*?)[\'"]', html)
print(urls) # Выведет: ['https://example.com']
Хотя регулярные выражения помогают извлечь текст, они не всегда идеальны для сложных структур HTML. В таких случаях рекомендуется использовать специализированные библиотеки для парсинга, такие как BeautifulSoup в Python, которые работают с HTML гораздо эффективнее и безопаснее, чем регулярные выражения.
Конвертация HTML в текст с помощью онлайн-сервисов
Для преобразования HTML-кода в текстовый формат существует несколько онлайн-сервисов, которые предлагают простой и быстрый способ извлечения чистого текста из исходного кода. Эти инструменты не требуют установки программного обеспечения и позволяют избежать лишних символов, таких как теги и атрибуты, сохраняя только текстовое содержимое страницы.
Один из популярных сервисов — HTML2Text. Он позволяет вставить HTML-код в специальное поле и получить чистый текст, который можно использовать в других приложениях или документах. Этот сервис поддерживает различные форматы HTML и сохраняет структуру текста, включая абзацы и списки.
Другим удобным инструментом является Browserling HTML to Text. С помощью этого сервиса можно быстро очистить HTML-код от лишних элементов и сохранить только текстовое содержимое. Он также позволяет конвертировать HTML-код, вставленный в текстовое поле, а результаты можно скачать или скопировать напрямую.
При использовании таких онлайн-сервисов важно помнить, что результаты могут зависеть от сложности исходного HTML-кода. Некоторые инструменты могут не поддерживать все особенности кодировки или специфические теги, такие как шрифты и стили. Поэтому перед использованием рекомендуется проверять полученные результаты, чтобы убедиться в их точности.
Методы работы с HTML кодом в текстовых редакторах
Для работы с HTML кодом в текстовых редакторах важно учитывать несколько основных методов, которые помогают эффективно редактировать и преобразовывать код в удобный для чтения формат.
- Прямой редактирование HTML: Это стандартный способ, при котором весь HTML код открывается в текстовом редакторе. Это удобно для небольших проектов, где не требуется визуальный интерфейс, и вы можете работать исключительно с кодом.
- Использование подсветки синтаксиса: Важный инструмент для работы с HTML кодом. Подсветка синтаксиса помогает выделить теги, атрибуты и значения, что значительно упрощает восприятие структуры кода и поиск ошибок. Популярные редакторы, такие как Visual Studio Code или Sublime Text, поддерживают эту функцию по умолчанию.
- Автозавершение кода: Большинство современных редакторов поддерживают автозавершение HTML тегов и атрибутов. Это ускоряет процесс написания и снижает вероятность ошибок. Например, в редакторах типа Atom или Brackets автозавершение включается автоматически, улучшая скорость работы.
- Использование фрагментов кода: Это метод, при котором заранее подготовленные шаблоны HTML кода вставляются в редактор с помощью комбинаций клавиш. Такой подход экономит время при написании повторяющихся блоков, например, для создания форм или таблиц.
- Работа с отступами и форматированием: Регулярное использование отступов и форматирования делает код более читаемым. В текстовых редакторах можно настроить автоматическое добавление отступов при создании новых тегов, что помогает поддерживать структуру документа. Это особенно важно при работе с большими проектами.
Сочетание этих методов позволяет эффективно работать с HTML кодом, улучшая его читаемость и сокращая время на написание и исправление ошибок.
Использование Python для парсинга HTML и извлечения текста

Для парсинга HTML и извлечения текста в Python часто используется библиотека BeautifulSoup. Этот инструмент позволяет легко работать с HTML-документами, извлекая нужную информацию, удаляя лишние теги и получая чистый текст.
Первый шаг – установить необходимые библиотеки. Это можно сделать через pip:
pip install beautifulsoup4 requests
После установки можно начать работу. Для парсинга HTML-кода нужно загрузить документ с помощью библиотеки requests. Например, если HTML-код загружается с веб-страницы:
import requests from bs4 import BeautifulSoup url = "https://example.com" response = requests.get(url) html_content = response.text soup = BeautifulSoup(html_content, "html.parser")
В данном примере мы загружаем HTML-код страницы и передаем его в BeautifulSoup. С помощью объекта soup можно выполнять различные операции по извлечению данных.
Для получения текста из HTML-документа, нужно извлечь содержимое элементов, игнорируя теги. Например, чтобы извлечь текст из всех абзацев:
paragraphs = soup.find_all('p')
for p in paragraphs:
print(p.get_text())
Метод `get_text()` извлекает текстовое содержимое элемента, игнорируя все теги. Это полезно для извлечения чистого текста без лишних элементов.
Если необходимо извлечь текст из определённых частей страницы, например, из заголовков или ссылок, можно использовать методы поиска по тегам и аттрибутам. Для получения текста из заголовков h1:
headers = soup.find_all('h1')
for header in headers:
print(header.get_text())
Кроме того, можно использовать CSS-селекторы для более точного извлечения данных. Метод `select()` позволяет искать элементы по классам, id и другим аттрибутам:
items = soup.select('.item-class')
for item in items:
print(item.get_text())
Этот подход упрощает выбор нужных данных, особенно если структура HTML-страницы сложная.
Если HTML-код содержит ненужные элементы, такие как скрипты или стили, их можно легко удалить с помощью метода `decompose()`:
for script in soup.find_all('script'):
script.decompose()
for style in soup.find_all('style'):
style.decompose()
Этот код удаляет все теги