Сохранение HTML кода – это важная задача для разработчиков, особенно когда нужно обработать или передать данные из веб-приложений. В большинстве случаев это можно сделать с помощью стандартных инструментов программирования, таких как библиотеки для работы с файлами или базы данных. Основной проблемой является правильное экранирование символов и сохранение структуры документа, чтобы избежать искажений при повторной загрузке.
Использование файловой системы является самым простым и часто используемым методом. Для этого достаточно записать строку HTML в текстовый файл с расширением .html. В большинстве языков программирования есть встроенные функции для работы с файлами. Например, в Python можно использовать метод open() с режимом записи, а в JavaScript – методы FileWriter или Blob. Однако важно учитывать кодировку файла. Рекомендуется использовать UTF-8, чтобы избежать проблем с отображением символов.
При более сложных требованиях можно воспользоваться базами данных. Это удобно, когда нужно хранить большое количество HTML-контента, например, в системах управления контентом. В таком случае, данные обычно записываются в строковые поля базы данных, что позволяет легко извлекать и изменять их. При этом важно следить за безопасностью, используя механизмы экранирования и предотвращения атак, таких как XSS (межсайтовые скриптовые атаки).
Наконец, при необходимости передачи HTML-кода по сети (например, в API) используется сериализация. Преимущественно для этого применяются форматы JSON или XML. Однако для корректной передачи необходимо позаботиться об экранировании символов, таких как <, >, " и другие, которые могут нарушить структуру данных при обработке на сервере или клиенте.
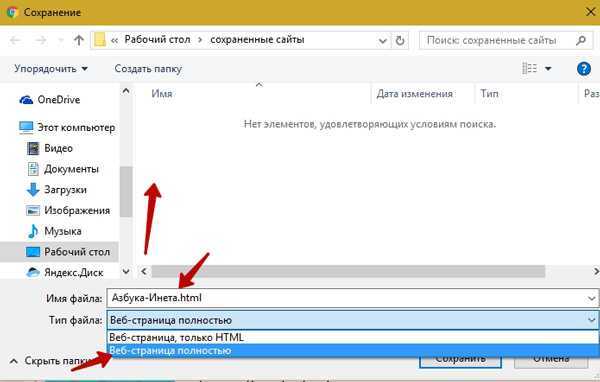
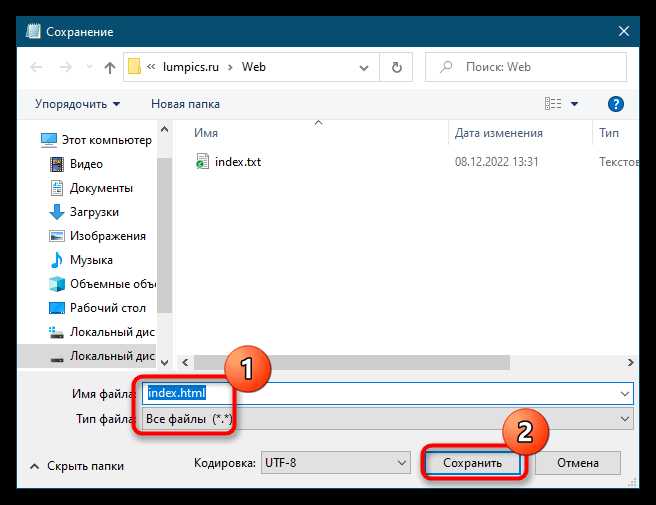
Использование файловых систем для сохранения HTML кода
Для сохранения HTML-кода на сервере или локальной машине часто используют файловые системы. Это один из самых простых и надежных методов, который позволяет эффективно работать с файлами, как на сервере, так и в приложениях с ограниченными ресурсами.
При сохранении HTML кода на файловой системе важным моментом является выбор формата и структуры директорий. Обычно HTML файлы сохраняются с расширением .html или .htm, что позволяет легко идентифицировать их как веб-страницы. Однако для более сложных проектов часто используется структура каталогов, где каждый HTML файл хранится в отдельной директории, что упрощает их организацию и доступ к ним.
Один из ключевых аспектов – правильная работа с правами доступа к файлам. Особенно если HTML код генерируется динамически, например, через серверный язык программирования. В таком случае важно установить необходимые права для записи, чтения и выполнения файлов. В противном случае, попытки сохранять или изменять HTML код могут привести к ошибкам или утрате данных.
Для сохранения HTML файлов в разных средах, например, на сервере с использованием языков программирования (Python, PHP, Node.js и др.), необходимо использовать системные библиотеки для работы с файлами. В Python, например, для записи в файл можно использовать встроенный модуль open(), а в Node.js – стандартный модуль fs для работы с файловой системой.
Важным фактором при использовании файловой системы является обеспечение производительности при работе с большим количеством файлов. Для этого следует избегать записи HTML кода в один файл, если проект масштабируемый. Вместо этого рекомендуется использовать отдельные файлы для разных частей контента, что позволяет ускорить обработку запросов и улучшить масштабируемость проекта.
Когда HTML код генерируется на сервере, важно правильно настроить кэширование файлов. Это снизит нагрузку на файловую систему и ускорит время отклика веб-сайта. Один из методов – использование временных файлов, которые записываются в кэш на сервере и удаляются по прошествии определенного времени или при изменении контента.
Автоматизация сохранения HTML через скрипты на Python
Основной задачей является получение HTML-кода с веб-страницы и сохранение его в файл. Обычно это достигается через следующие этапы:
- Загрузка HTML-кода
- Парсинг HTML (если необходимо)
- Сохранение в файл
Для начала рассмотрим пример кода, который загружает страницу и сохраняет её содержимое в файл:
import requests
url = "https://example.com"
response = requests.get(url)
if response.status_code == 200:
with open("page.html", "w", encoding="utf-8") as file:
file.write(response.text)
else:
print(f"Ошибка загрузки страницы: {response.status_code}")В данном примере мы используем requests.get() для получения HTML-кода страницы, а затем записываем его в файл с помощью стандартного метода open().
Если вам нужно не просто сохранить код страницы, а также обработать или изменить его, то стоит использовать библиотеку BeautifulSoup, которая облегчает извлечение данных из HTML.
Пример кода с использованием BeautifulSoup:
from bs4 import BeautifulSoup
import requests
url = "https://example.com"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Пример: извлекаем все ссылки
links = [a['href'] for a in soup.find_all('a', href=True)]
with open("links.txt", "w", encoding="utf-8") as file:
for link in links:
file.write(link + "\n")
else:
print(f"Ошибка загрузки страницы: {response.status_code}")Этот скрипт загружает страницу, парсит её с помощью BeautifulSoup и сохраняет все найденные ссылки в текстовый файл. Таким образом, можно автоматизировать не только сохранение страниц, но и извлечение конкретных данных.
В случае необходимости обработки больших объёмов данных или работы с несколькими страницами одновременно, можно использовать асинхронный подход с библиотекой aiohttp и asyncio. Это позволит ускорить процесс за счёт параллельных запросов к серверу.
Пример с aiohttp:
import aiohttp
import asyncio
async def fetch_and_save(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
html = await response.text()
with open("page.html", "w", encoding="utf-8") as file:
file.write(html)
async def main():
url = "https://example.com"
await fetch_and_save(url)
asyncio.run(main())Этот код позволяет асинхронно загружать HTML-страницу и сохранять её в файл. Использование aiohttp особенно полезно при необходимости обрабатывать большое количество URL одновременно.
Для эффективной автоматизации рекомендуется использовать обработку ошибок, например, при недоступности страницы, и логирование для отслеживания процесса работы скрипта.
Сохранение HTML кода с помощью JavaScript на клиенте
Для сохранения HTML кода с помощью JavaScript на клиенте, можно воспользоваться встроенной возможностью создания файлов на основе данных с использованием объекта Blob и функции URL.createObjectURL(). Это позволяет пользователю скачать файл, содержащий HTML-код, прямо из браузера, без необходимости взаимодействия с сервером.
Пример использования:
function saveHTML(htmlContent) {
const blob = new Blob([htmlContent], { type: 'text/html' });
const url = URL.createObjectURL(blob);
const link = document.createElement('a');
link.href = url;
link.download = 'page.html';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
URL.revokeObjectURL(url);
}
В этом примере функция saveHTML принимает HTML-код в виде строки, создает Blob-объект с типом данных ‘text/html’ и генерирует ссылку для скачивания файла. Важно, чтобы имя файла, передаваемое в атрибут download, отражало нужное расширение, например .html.
Основные шаги процесса:
- Создание Blob-объекта, который содержит HTML-код.
- Создание временной ссылки для скачивания файла.
- Программный клик по ссылке для начала загрузки.
- Удаление временной ссылки и очистка URL-объекта для освобождения памяти.
Такой подход гарантирует, что файл будет скачан без необходимости обращения к серверу, что ускоряет процесс и упрощает взаимодействие с пользователем.
Кроме того, с использованием JavaScript можно добавить обработку различных ошибок, таких как отказ от сохранения файла, чтобы улучшить пользовательский опыт. Важно помнить, что данный метод поддерживается в современных браузерах, но может не работать в некоторых старых версиях.
Как использовать локальные базы данных для хранения HTML
SQLite – это реляционная база данных, которая идеально подходит для хранения HTML-кода, особенно если нужно сохранить сложные структуры или метаинформацию. HTML-код можно сохранять как текст в одном из полей таблицы. Запросы к базе выполняются с использованием SQL, что делает работу с данными гибкой и удобной. Важно обратить внимание на оптимизацию запросов и использование индексов для быстрого поиска.
IndexedDB – это объектно-ориентированная база данных, доступная в браузерах. Она предоставляет более высокую производительность и гибкость, чем локальное хранилище. IndexedDB позволяет работать с большими объемами данных и поддерживает асинхронный доступ. HTML-код можно хранить в виде объектов, что позволяет добавлять дополнительные метаданные, такие как теги, время создания или уникальные идентификаторы для быстрого поиска и фильтрации.
WebSQL, несмотря на ограниченную поддержку, также может быть использован для хранения HTML. Это реляционная база данных, которая позволяет выполнять SQL-запросы и хранить данные в таблицах. Однако WebSQL устарел и рекомендуется избегать его использования в новых проектах, поскольку он не поддерживается во всех браузерах.
Для эффективной работы с локальными базами данных при хранении HTML важно учитывать безопасность и производительность. Например, при хранении больших объемов данных в IndexedDB стоит учитывать ограничения по объему хранилища в разных браузерах. Для обеспечения целостности данных можно использовать транзакции, которые гарантируют, что данные будут сохранены или откатятся в случае ошибки.
Также следует позаботиться о защите данных. Хранение HTML-кода в базах данных может быть связано с рисками безопасности, особенно если данные содержат пользовательский ввод. В таких случаях необходимо использовать механизмы экранирования и валидирования данных для предотвращения атак типа XSS (межсайтового скриптинга).
Использование API для сохранения HTML на сервере
Для сохранения HTML-кода на сервере можно использовать API, которое обеспечивает безопасный и эффективный способ передачи данных. Важно правильно настроить серверную часть, чтобы обеспечить корректную обработку и сохранение данных.
Основной принцип работы API для сохранения HTML – это отправка POST-запроса с содержимым HTML через HTTP-протокол. Сервер обрабатывает этот запрос, сохраняет данные и, при необходимости, возвращает информацию о статусе операции.
Для реализации такого API часто используется RESTful подход, где запросы к серверу оформляются в виде URL с параметрами. Примерный алгоритм взаимодействия выглядит так:
- Пользователь создает или редактирует HTML-код на клиентской стороне.
- Код отправляется на сервер через POST-запрос с помощью JavaScript (например, через fetch или XMLHttpRequest).
- На сервере HTML-код сохраняется в базе данных или файловой системе.
- Сервер возвращает ответ о статусе операции (успешно или с ошибкой).
Пример API запроса:
POST /save-html
Content-Type: application/json
{
"html_content": "<div>Пример HTML-кода</div>"
}
На сервере запрос обрабатывается следующим образом:
app.post('/save-html', (req, res) => {
const htmlContent = req.body.html_content;
// Сохранение в файл или базу данных
saveHtmlContent(htmlContent)
.then(() => res.status(200).send('HTML успешно сохранён'))
.catch(err => res.status(500).send('Ошибка при сохранении HTML'));
});
Важно обрабатывать ошибки при сохранении HTML. Сервер должен проверять корректность полученных данных (например, отсутствие вредоносных скриптов) и подтверждать успешное выполнение операции с помощью соответствующего HTTP-кода ответа (например, 200 – успешное выполнение, 500 – внутренняя ошибка сервера).
Для повышения безопасности рекомендуется использовать механизмы защиты, такие как валидация данных, защита от XSS-атак и фильтрация входных данных.
Сохранение HTML в формате файлов с динамическим контентом
Для сохранения HTML с динамическим контентом необходимы инструменты, которые позволяют учесть изменения, происходящие на странице в процессе её работы. Простое сохранение HTML-кода не всегда достаточно, так как он может содержать скрипты, которые генерируют или изменяют данные на странице. Чтобы сохранить такие страницы корректно, требуется подход с учётом работы динамических элементов.
Часто для этого используется подход с «рендерингом» страницы на сервере или в браузере перед её сохранением. Рассмотрим несколько методов:
- Использование JavaScript-рендеринга: Браузеры поддерживают выполнение JavaScript, и для таких страниц часто требуется сохранить HTML, который уже прошёл обработку скриптами. Это можно сделать с помощью инструментов, таких как Puppeteer или Playwright, которые позволяют «захватить» HTML после выполнения всех динамических изменений.
- Серверное рендеринг: Если контент генерируется на сервере (например, с помощью шаблонов или фреймворков), можно сохранить окончательный HTML, который возвращается пользователю. Этот подход удобен, если контент не сильно зависит от клиентской логики или если сервер выполняет обработку данных до отправки в браузер.
- Использование Web Scraping: Для сохранения динамических страниц без вмешательства в их код можно использовать скрипты, выполняющие парсинг. В этом случае необходимо учитывать, что для полноценного парсинга потребуется запускать JavaScript или использовать специализированные библиотеки, такие как Selenium, которые могут имитировать действия пользователя и извлекать данные после выполнения скриптов.
- Использование API для получения данных: В некоторых случаях динамический контент получается через API-запросы, которые возвращают данные в формате JSON или XML. Получив эти данные, можно легко генерировать HTML-код и сохранить его, что значительно ускоряет процесс сохранения данных с динамических страниц.
Для сохранения файлов, содержащих динамическое содержимое, важно учитывать несколько факторов:
- Должен быть учтён правильный порядок выполнения скриптов, чтобы динамически загружаемые данные успели обработаться.
- Необходимо обеспечить корректную работу со всеми зависимыми файлами, такими как CSS и JavaScript, чтобы сохранённая страница могла полноценно работать в будущем.
- Рекомендуется использовать технику «снятия скриншотов» или создание полностью статичной копии, если динамическое содержание не влияет на функциональность страницы.
Методы, упомянутые выше, позволяют эффективно сохранять HTML-код с динамическим контентом, обеспечивая его дальнейшее использование в различных условиях.
Методы предотвращения потери данных при сохранении HTML
Для обеспечения сохранности данных при сохранении HTML-кода необходимо учитывать несколько факторов, включая корректное кодирование символов, использование валидных структур данных и адекватное управление ошибками. Важно не только правильно сохранить HTML-код, но и гарантировать его правильное восстановление и отображение при необходимости.
1. Кодировка символов – ключевой аспект для предотвращения потери данных, особенно если документ содержит символы, которые выходят за пределы стандартного ASCII. Использование UTF-8 обеспечивает поддержку всех символов, включая редкие и специализированные. Рекомендуется всегда указывать кодировку в мета-тегах документа: <meta charset="UTF-8">. Это гарантирует, что все символы будут правильно интерпретированы при открытии документа в разных системах и браузерах.
2. Сохранение и восстановление структуры документа также критично. Для предотвращения потерь необходимо обеспечить, чтобы все теги были корректно закрыты, а структура документа оставалась валидной. Это достигается использованием валидаторов HTML, таких как W3C HTML Validator, которые проверяют код на соответствие стандартам. Открытые или неправильно вложенные теги могут привести к неверному отображению данных или их потере.
3. Использование методов сериализации для динамического контента является важным шагом при сохранении HTML, содержащего динамически генерируемые данные. Для таких данных часто используется JavaScript, который может динамически изменять содержимое страницы. Чтобы избежать потерь, необходимо сериализовать данные перед их сохранением. Применение JSON или других стандартных форматов для хранения данных в формате, пригодном для последующей загрузки, гарантирует, что данные не будут потеряны при перезагрузке страницы.
4. Работа с большими объемами данных требует применения техник для их эффективного сохранения. Например, использование хранения данных в виде фрагментов HTML и их постепенная загрузка с помощью AJAX помогает избежать потерь при работе с большими файлами. Разделение документа на отдельные компоненты и сохранение их в независимые файлы также помогает минимизировать риски потерь при повреждении одного из частей.
5. Резервное копирование данных перед их изменением или сохранением является обязательной практикой. Использование систем контроля версий (например, Git) позволяет отслеживать изменения и быстро восстанавливать предыдущие версии кода в случае ошибок. Это особенно важно для крупных проектов, где потеря даже небольшой части данных может привести к значительным последствиям.
6. Обработка ошибок при сохранении критична для обеспечения целостности данных. Важно использовать обработчики ошибок на уровне программных средств, которые выполняют операции сохранения. Это позволит избежать потери данных при возникновении проблем с доступом к файлам, сбоями в сетевых соединениях или другими непредвиденными обстоятельствами. Регулярная проверка корректности записи данных в файл и уведомление пользователя о неудачных попытках сохранения помогут избежать нежелательных последствий.
Вопрос-ответ:
Какие способы существуют для сохранения HTML кода программными средствами?
Существует несколько методов сохранения HTML кода с помощью программирования. Один из самых простых — это использование стандартных функций работы с файлами в языке программирования. Например, в Python можно открыть файл для записи и сохранить туда строку с HTML кодом. Для этого подойдет встроенная библиотека `open()`. Другой метод — использование фреймворков, таких как Django или Flask, которые позволяют генерировать и сохранять HTML страницы динамически через серверные запросы. Также можно сохранить HTML в базе данных, если необходимо хранить страницы для дальнейшего использования или обновлений.
Какие библиотеки могут помочь в обработке и сохранении HTML кода?
Для работы с HTML в Python можно использовать несколько полезных библиотек. Например, `BeautifulSoup` помогает парсить и изменять HTML код, а также сохранять его в нужном формате. Библиотека `lxml` — это еще один инструмент для работы с XML и HTML, который обеспечивает высокую скорость обработки. Если необходимо просто записать HTML в файл, можно использовать стандартные средства работы с файлами, такие как `open()` и `write()` в Python.
Какие проблемы могут возникнуть при сохранении HTML кода программными средствами?
Основные проблемы при сохранении HTML кода могут быть связаны с некорректной кодировкой. Важно убедиться, что файл сохраняется в правильной кодировке, чтобы избежать ошибок отображения текста. Также следует учитывать форматирование HTML кода: если код генерируется динамически, то важно правильно экранировать специальные символы, чтобы избежать ошибок в структуре документа. Кроме того, при сохранении HTML в базе данных важно следить за размером данных, так как большие объемы могут вызвать проблемы с производительностью или переполнением полей.
Какие способы существуют для сохранения HTML кода программными средствами?
Существует несколько способов сохранить HTML код с помощью программных средств. Один из самых простых — это использовать стандартные библиотеки для работы с файлами в различных языках программирования. Например, в Python можно использовать функцию `open()` для записи HTML кода в файл. В других языках, таких как JavaScript, для записи можно использовать API для работы с файловой системой, а в более сложных приложениях могут быть использованы базы данных для хранения HTML данных. Важно, чтобы код был корректно сохранён и имел правильное расширение, например, `.html`.
Как можно сохранить HTML код из веб-страницы программным способом?
Для сохранения HTML кода веб-страницы можно воспользоваться несколькими методами. Один из самых популярных способов — это использование инструментов для автоматизации браузера, таких как Selenium, который позволяет программно получить доступ к содержимому страницы и сохранить его в файл. Также можно использовать простые запросы HTTP, например, с помощью библиотеки `requests` в Python для получения исходного HTML-кода страницы. В случае работы с веб-приложениями, можно использовать JavaScript и его возможности для загрузки и сохранения данных, например, через методы `XMLHttpRequest` или `fetch` для получения и сохранения HTML на сервере или локально.