Сохранение HTML-страницы позволяет получить локальную копию содержимого сайта, включая текст, изображения и стили. Это может быть полезно для офлайн-доступа, анализа структуры кода или архивирования информации. Варианты сохранения различаются в зависимости от браузера и цели пользователя.
Вариант 1: в браузере Google Chrome кликните правой кнопкой мыши по странице и выберите “Сохранить как…”. В появившемся окне выберите формат “Веб-страница, полностью”, чтобы сохранить не только файл HTML, но и связанные ресурсы (изображения, стили, скрипты).
Вариант 2: для сохранения только HTML-кода без ресурсов выберите формат “Веб-страница, только HTML”. Этот способ сохраняет структуру страницы, но не позволит отобразить её в полном виде без подключения к интернету.
В Mozilla Firefox действия аналогичны. Используйте “Файл” → “Сохранить страницу как…” или нажмите Ctrl + S. Обратите внимание: при выборе полной страницы создаётся папка с файлами ресурсов и отдельный HTML-файл. При перемещении или переименовании важно сохранять структуру этих данных, иначе страница будет отображаться некорректно.
Для разработчиков и пользователей, которым важен чистый код, удобен просмотр кода страницы (Ctrl + U) и копирование HTML напрямую. Этот способ не сохраняет стили и медиафайлы, но позволяет анализировать структуру DOM без лишнего кода, добавляемого при рендеринге.
Также можно использовать расширения, например SingleFile для Chrome и Firefox. Оно сохраняет страницу в один .html-файл, встраивая все ресурсы внутрь. Это удобно для архивирования и упрощает перенос без потери содержимого.
Сохранение страницы через меню браузера
В Google Chrome нажмите на три точки в правом верхнем углу, выберите «Дополнительные инструменты» – «Сохранить страницу как». В открывшемся окне укажите папку и тип файла: «Веб-страница, полная» сохранит HTML-файл и папку с ресурсами.
В Mozilla Firefox нажмите на кнопку меню с тремя полосами, выберите «Сохранить как». По умолчанию используется формат «Веб-страница, полная». Все изображения, скрипты и стили сохраняются в отдельной папке.
В Microsoft Edge нажмите на кнопку с тремя точками, затем – «Сохранить как». Укажите место и формат. Если выбрать «Веб-страница, полная», браузер создаст HTML и подпапку с вложениями.
В Safari (на macOS) используйте пункт меню «Файл» – «Сохранить как». При выборе формата «Архив веб-страницы» сохраняется единый .webarchive-файл, подходящий для повторного открытия в Safari.
После сохранения не перемещайте HTML-файл отдельно от созданной папки, иначе часть содержимого (например, изображения) не отобразится при открытии.
Разница между форматами: «Веб-страница, полностью» и «HTML-файл»

При сохранении страницы через браузер доступно два формата: «Веб-страница, полностью» и «HTML-файл». Первый вариант создаёт основной HTML-документ и отдельную папку с вложениями – изображениями, стилями, скриптами. Все внешние ресурсы копируются локально, что позволяет открыть страницу в автономном режиме с сохранением внешнего вида.
Формат «HTML-файл» сохраняет только сам HTML-код без сопутствующих файлов. При открытии такого файла в браузере отсутствуют стили, изображения, интерактивные элементы. Это удобно для анализа исходного кода, но не подходит для просмотра страницы в привычном виде.
Для сохранения интерфейса, структуры и дизайна следует использовать «Веб-страница, полностью». Если задача – изучение разметки или минимальный архив, подойдёт «HTML-файл». В обоих случаях рекомендуется проверять наличие всех нужных данных, так как динамически загружаемые элементы (например, через JavaScript) могут не сохраниться корректно.
Скачивание HTML-кода страницы через инструменты разработчика
Откройте сайт в браузере Google Chrome, нажмите F12 или кликните правой кнопкой мыши по странице и выберите «Просмотреть код». В появившейся панели выберите вкладку Elements.
Правый клик по тегу <html> в верхней части дерева и выбор опции Copy → Copy outerHTML позволит скопировать полный HTML-документ, доступный на момент загрузки.
Вставьте скопированный код в текстовый редактор, например, Notepad++, и сохраните файл с расширением .html. При открытии файла локально отобразится сохранённая структура страницы.
Для получения только части HTML (например, блока с данными) найдите нужный элемент в дереве и выберите Copy → Copy element. Это удобно при копировании таблиц, списков или контейнеров с контентом.
Инструменты разработчика не отображают серверную часть и динамически подгружаемые данные через JavaScript. Для получения финального состояния используйте вкладку Network и перезагрузите страницу (F5), затем найдите запрос с документом типа document. Клик по нему – вкладка Response содержит исходный HTML-код, загруженный с сервера. Его можно скопировать и сохранить вручную.
Использование расширений браузера для сохранения страниц
В настройках SingleFile можно включить автоматическое сохранение, фильтрацию элементов по CSS-селекторам и удаление рекламы. Поддерживается сохранение с учетом вложенных iframe, задержек загрузки и скриптов, загружаемых асинхронно.
Для работы с архивами страниц подходит Save Page WE. Оно сохраняет сайт в формате .html или .maff (архив Mozilla). В отличие от стандартного «Сохранить как», сохраняются не только ресурсы первого уровня, но и вложенные зависимости. Это особенно полезно при сохранении документации или страниц с большим количеством медиа.
При использовании любого расширения важно проверять результат в офлайн-режиме: не все скрипты и стили могут быть корректно встроены. Некоторые расширения позволяют вручную выбирать элементы для исключения или сохранения, что повышает точность результата.
Как сохранить страницу с сохранением стилей и изображений
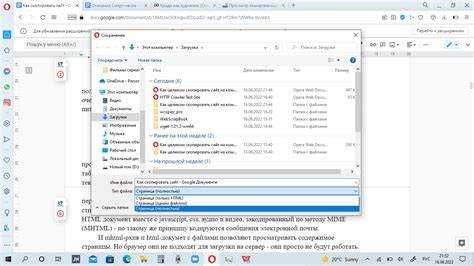
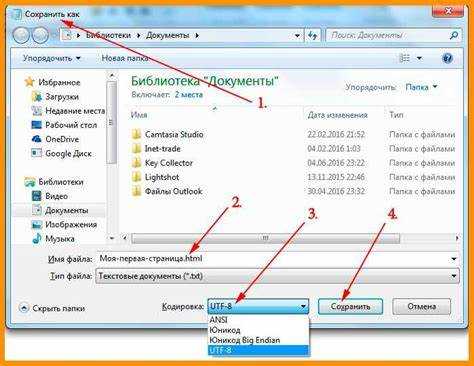
Чтобы сохранить веб-страницу со всеми стилями и изображениями, откройте её в браузере и нажмите Ctrl + S (на macOS – Cmd + S). В появившемся окне выберите тип сохранения «Веб-страница, полностью». Это создаст HTML-файл и папку с ресурсами.
В папке будут храниться файлы CSS, изображения, шрифты и скрипты, подключённые через относительные и абсолютные ссылки. Убедитесь, что страница загружена полностью перед сохранением – браузер не сохраняет ресурсы, которые ещё не подгрузились.
Если сайт использует динамическую подгрузку контента через JavaScript, встроенные средства браузера могут не сохранить всё корректно. В этом случае используйте расширение SingleFile для Chrome или Firefox. Оно объединяет HTML, стили и изображения в один файл. После установки нажмите иконку расширения и выберите «Сохранить текущую страницу».
Для более точного результата при работе с многоуровневыми сайтами или защищёнными ресурсами используйте программу HTTrack (Windows/Linux) или SiteSucker (macOS). Они скачивают сайт целиком, сохраняя структуру каталогов, изображения и стили.
После сохранения откройте HTML-файл локально, чтобы убедиться, что всё отобразилось корректно. Если изображения отсутствуют, проверьте путь к ним в исходном коде: браузер может не распознать ссылки, начинающиеся с // или data:.
Автоматическое сохранение страниц с помощью скриптов
Использование JavaScript для сохранения страницы
Основной принцип заключается в создании кода, который инициирует скачивание страницы в формате HTML. Простейший способ реализации включает создание функции, которая автоматически генерирует файл с текущим содержимым страницы.
- Скачивание HTML через Blob: Это метод, при котором создаётся объект Blob, содержащий HTML-код страницы. Затем создаётся ссылка для скачивания этого объекта.
«`javascript
const savePage = () => {
const htmlContent = document.documentElement.outerHTML;
const blob = new Blob([htmlContent], { type: ‘text/html’ });
const url = URL.createObjectURL(blob);
const a = document.createElement(‘a’);
a.href = url;
a.download = ‘page.html’;
a.click();
URL.revokeObjectURL(url);
};
Этот скрипт сохраняет HTML-код текущей страницы в файл page.html.
Использование Node.js для автоматизации сохранения
Node.js позволяет автоматизировать процесс сохранения страниц с помощью библиотек, таких как puppeteer или axios, для получения и записи HTML-кода страниц на диск.
- Пример с puppeteer: Puppeteer – это библиотека для управления браузером Chrome. Она позволяет программно захватывать содержимое страниц и сохранять их в локальные файлы.
javascriptCopyEditconst puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(‘https://example.com’);
const htmlContent = await page.content();
const fs = require(‘fs’);
fs.writeFileSync(‘page.html’, htmlContent);
await browser.close();
})();
Этот скрипт запускает браузер, открывает страницу и сохраняет её HTML-код в файл page.html.
Автоматизация сохранения с помощью планировщиков задач
Для регулярного сохранения страниц можно использовать планировщики задач. Например, cron на Linux или Task Scheduler на Windows могут запускать скрипты на определённое время или по расписанию.
- Пример для Linux: В настройках cron можно добавить команду для запуска скрипта на Node.js, который сохранит HTML страницу в нужный момент времени.
bashCopyEdit0 12 * * * /usr/bin/node /path/to/script.js
Этот cron-запуск будет сохранять страницу каждый день в 12:00.
Рекомендации по безопасности
- Проверьте источники скриптов, чтобы избежать загрузки вредоносных файлов.
- Используйте проверенные библиотеки для работы с веб-страницами.
- Обрабатывайте ошибки и исключения, чтобы избежать потери данных или неправильного сохранения контента.
Вопрос-ответ:
Как сохранить HTML страницу с сайта на компьютер?
Чтобы сохранить HTML страницу с сайта, откройте её в браузере и нажмите правую кнопку мыши. В меню выберите пункт «Сохранить как…» или используйте сочетание клавиш Ctrl+S. В открывшемся окне выберите место на компьютере для сохранения файла и укажите формат «Веб-страница, полная» или «Веб-страница, только HTML», в зависимости от того, хотите ли вы сохранить все элементы страницы (изображения, стили и скрипты) или только HTML код.
Почему некоторые страницы не сохраняются полностью?
Некоторые страницы не сохраняются полностью из-за особенностей веб-технологий, которые они используют. Например, страницы, использующие динамическую подгрузку контента (например, через JavaScript), могут не сохранить все данные, если сохранение происходит до полной загрузки страницы. Также могут возникнуть проблемы с элементами, которые хранятся на сторонних серверах (например, изображения или скрипты), и они не сохраняются вместе с HTML.
Можно ли сохранить HTML страницу с помощью какого-то расширения для браузера?
Да, существует множество расширений для браузеров, которые позволяют сохранять страницы в различных форматах. Например, расширения для Google Chrome, такие как «Save Page WE», позволяют сохранять веб-страницы с полным набором элементов, включая изображения, стили и скрипты. Такие расширения могут быть полезны, если стандартные методы сохранения не обеспечивают нужного результата.
Что делать, если страница не сохраняется с изображениями и другими элементами?
Если при сохранении страницы изображения и другие элементы не сохраняются, можно попробовать два способа. Во-первых, использовать опцию «Сохранить как…» и выбрать формат «Веб-страница, полная». Во-вторых, можно сохранить страницу с помощью специализированных расширений для браузера, которые поддерживают более точную сохранность всех элементов. Также важно убедиться, что страница полностью загрузилась перед сохранением.
Как сохранить только исходный HTML код страницы, без других элементов?
Если вам нужно сохранить только HTML код страницы, это можно сделать следующим образом. В браузере откройте страницу, затем нажмите правую кнопку мыши и выберите пункт «Посмотреть исходный код» или используйте клавишу Ctrl+U. После этого откроется новый таб с исходным кодом страницы, который можно скопировать и вставить в текстовый файл, либо сохранить сам файл с расширением .html.