Подсчёт уникальных значений в SQL запросах – задача, с которой сталкиваются разработчики и аналитики при работе с большими объёмами данных. В этой статье рассматриваются конкретные подходы для подсчёта уникальных id в различных ситуациях. Основное внимание уделяется использованию стандартных SQL функций, таких как COUNT(DISTINCT), а также оптимизации запросов для повышения производительности.
Когда требуется получить количество уникальных идентификаторов в базе данных, проще всего воспользоваться функцией COUNT(DISTINCT id). Она позволяет подсчитать количество разных значений в столбце. Однако важно понимать, что эта функция может работать медленно на больших объёмах данных, так как требует дополнительной обработки. Для повышения скорости выполнения запросов рекомендуется избегать использования COUNT(DISTINCT) в подзапросах, а вместо этого использовать агрегацию и группировку данных.
В случаях, когда нужно выполнить подсчёт уникальных значений с условиями или в сложных соединениях, может быть полезным использование GROUP BY с дополнительными фильтрами. Такой подход позволит оптимизировать запросы и уменьшить нагрузку на сервер базы данных. Использование индексов на столбцах, которые участвуют в фильтрации или группировке, также может существенно ускорить выполнение запросов.
При работе с большими таблицами, содержащими миллионы записей, стоит также обратить внимание на правильное индексирование. Неправильно настроенные индексы могут стать причиной значительного замедления запросов, включая подсчёт уникальных значений. Важно протестировать различные варианты индексации и выбрать наиболее эффективный для конкретной задачи.
Использование DISTINCT для подсчета уникальных id
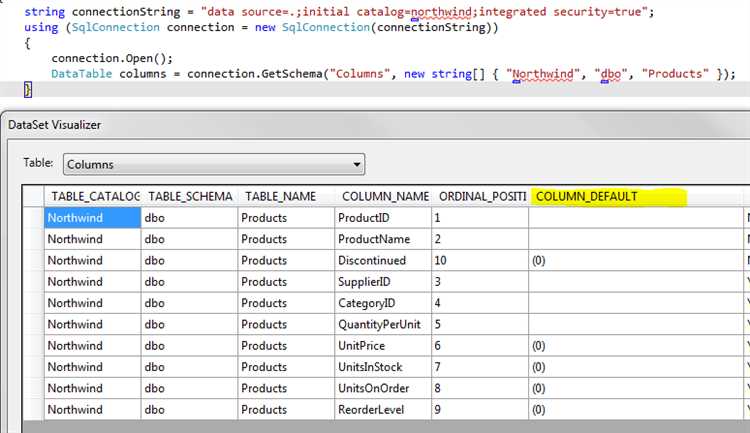
Оператор DISTINCT в SQL позволяет выбрать только уникальные значения из указанного столбца, что полезно при подсчете уникальных идентификаторов. Применение DISTINCT сокращает количество повторяющихся записей, предоставляя только уникальные значения.
Для подсчета уникальных id используется комбинация оператора DISTINCT и функции COUNT. Запрос будет выглядеть следующим образом:
SELECT COUNT(DISTINCT id) FROM таблица;
Этот запрос вернет количество уникальных значений в столбце id. Такой подход эффективен, когда необходимо точно определить количество уникальных идентификаторов, например, в списках пользователей или товаров.
Важно помнить, что использование DISTINCT может повлиять на производительность запросов при больших объемах данных. В таких случаях можно применить индексы на столбцы, которые участвуют в запросе, для ускорения выборки.
Если в запросе требуется подсчитать уникальные id с учетом дополнительных условий, можно добавить WHERE:
SELECT COUNT(DISTINCT id) FROM таблица WHERE условие;
Этот подход позволяет гибко фильтровать данные перед подсчетом уникальных значений, что часто встречается в отчетах или аналитических запросах.
Применение COUNT с DISTINCT для уникальных значений
Использование COUNT с DISTINCT позволяет подсчитывать количество уникальных значений в столбце, исключая дубли. Это особенно полезно в ситуациях, когда важно узнать, сколько различных значений присутствует в базе данных, не учитывая повторения.
Запрос с COUNT(DISTINCT …) выглядит следующим образом:
SELECT COUNT(DISTINCT column_name) FROM table_name;
Например, если в таблице пользователей содержится информация о городах, и нужно подсчитать, сколько уникальных городов указано, запрос будет следующим:
SELECT COUNT(DISTINCT city) FROM users;
Такой запрос вернет количество различных городов, без учета того, сколько раз каждый город встречается в таблице.
Важно отметить, что использование COUNT(DISTINCT) может снизить производительность при обработке больших объемов данных, так как требует дополнительного вычисления уникальных значений. В таких случаях полезно оптимизировать запросы или использовать индексы.
Кроме того, можно комбинировать COUNT(DISTINCT) с другими условиями, например, с WHERE, чтобы подсчитать уникальные значения только для определенных записей:
SELECT COUNT(DISTINCT city) FROM users WHERE age > 30;
Этот запрос вернет количество уникальных городов среди пользователей старше 30 лет.
Оптимизация запросов при подсчете уникальных id в больших таблицах
Подсчет уникальных значений в больших таблицах может существенно замедлить работу системы, особенно при использовании баз данных с миллионами записей. Для эффективной оптимизации запросов нужно учитывать несколько ключевых аспектов.
1. Использование индексов. Индексы могут значительно ускорить запросы, включая те, которые подсчитывают уникальные значения. Создание индекса на колонке, по которой выполняется подсчет уникальных id, уменьшает количество операций, которые необходимо выполнить для получения результата. Это особенно актуально для колонок, часто используемых в условиях WHERE или GROUP BY.
2. Избежание DISTINCT при подсчете. Часто встречается использование оператора DISTINCT для получения уникальных значений, однако он может быть менее эффективен в крупных таблицах. Вместо этого можно использовать агрегации с COUNT и GROUP BY. В некоторых случаях использование хеширования или специальных механизмов может уменьшить необходимость в таких операциях.
3. Параллельная обработка. В некоторых базах данных есть поддержка параллельной обработки запросов. Это позволяет разделить нагрузку на несколько процессоров или серверов. Использование параллельных вычислений может ускорить процесс подсчета уникальных id, особенно при работе с большими объемами данных.
4. Разбиение таблиц (sharding). В случае работы с очень большими таблицами можно рассмотреть возможность разбиения данных на несколько физических или логических сегментов. Это поможет уменьшить объем данных, с которым работает запрос, и ускорит его выполнение. Подсчет уникальных id будет происходить быстрее, так как запросы будут выполняться только для части данных.
5. Использование аналитических функций. Некоторые СУБД предлагают аналитические функции, такие как ROW_NUMBER или RANK, которые могут быть использованы для подсчета уникальных значений без выполнения полной агрегации. Эти функции могут работать быстрее, чем обычные агрегации, так как не требуют полного сканирования всей таблицы.
6. Оптимизация структуры данных. Иногда необходимость в подсчете уникальных значений может быть следствием неэффективной структуры данных. Например, нормализация данных или правильное использование типов данных может уменьшить необходимость в сложных и ресурсозатратных запросах. Важно учитывать, что избыточные данные или неправильные типы данных могут увеличивать время обработки запросов.
7. Профилирование и анализ выполнения запросов. Чтобы эффективно оптимизировать запросы, важно регулярно проводить профилирование. Используйте инструменты для анализа выполнения SQL-запросов, такие как EXPLAIN, чтобы понять, какие операции занимают больше всего времени. Это поможет выявить узкие места в запросах и оптимизировать их.
Использование GROUP BY для группировки уникальных id
В SQL оператор GROUP BY используется для группировки строк с одинаковыми значениями в одном или нескольких столбцах. Это может быть полезно, если нужно сгруппировать данные по уникальным id и выполнить операции агрегации, такие как подсчет, сумма или среднее.
Для подсчета уникальных id с помощью GROUP BY используется комбинация этого оператора с функцией COUNT. Например, если в таблице есть столбец с идентификаторами пользователей, можно сгруппировать данные по этим id и подсчитать количество записей для каждого уникального id.
SELECT user_id, COUNT(*) FROM users GROUP BY user_id;– этот запрос возвращает количество записей для каждого уникального идентификатора пользователя.
Важно помнить, что GROUP BY всегда создает одну строку для каждого уникального значения в выбранном столбце или комбинации столбцов. Для подсчета уникальных id в группе, можно использовать выражение COUNT(DISTINCT id).
SELECT COUNT(DISTINCT user_id) FROM users;– данный запрос вернет количество уникальных id пользователей в таблице.
Использование GROUP BY помогает при работе с большими объемами данных, когда необходимо выделить уникальные значения и агрегировать их, например, для анализа частоты появления каждого id или создания отчетов по уникальным значениям.
Для увеличения производительности запросов, особенно на больших объемах данных, рекомендуется индексировать столбцы, по которым происходит группировка, чтобы ускорить выполнение операции GROUP BY.
Если требуется дополнительно фильтровать результаты, можно использовать оператор HAVING, который применяется после группировки.
SELECT user_id, COUNT(*) FROM users GROUP BY user_id HAVING COUNT(*) > 1;– запрос, который возвращает только те id, которые встречаются более одного раза.
Как посчитать уникальные id с условиями фильтрации (WHERE)
Для подсчета уникальных идентификаторов в SQL с применением условий фильтрации используется конструкция COUNT(DISTINCT) в сочетании с оператором WHERE. Это позволяет сузить выборку до тех данных, которые соответствуют заданным условиям.
Пример запроса, который считает количество уникальных id из таблицы users, где возраст больше 30 лет:
SELECT COUNT(DISTINCT id)
FROM users
WHERE age > 30;Такой запрос гарантирует, что учитываются только уникальные значения id, соответствующие условию age > 30.
Если необходимо учитывать несколько условий фильтрации, можно комбинировать их с помощью логических операторов AND или OR. Например, чтобы посчитать уникальные id пользователей, которые старше 30 лет и находятся в определенном городе, запрос будет выглядеть так:
SELECT COUNT(DISTINCT id)
FROM users
WHERE age > 30 AND city = 'Moscow';В случае, если вам нужно исключить записи, где возраст меньше 18 лет или город не указан, можно воспользоваться логическим оператором NOT:
SELECT COUNT(DISTINCT id)
FROM users
WHERE age > 30 AND NOT city IS NULL;В данном примере будет подсчитано количество уникальных id, где возраст больше 30 лет, а город не пустой.
Особенность использования COUNT(DISTINCT) с фильтрацией в том, что сначала происходит фильтрация данных по условиям WHERE, а затем считается количество уникальных значений. Это важно, так как на производительность запроса может влиять как сложность условий фильтрации, так и количество обрабатываемых данных.
Когда необходимо учитывать фильтрацию по диапазону значений, например, по дате, используется конструкция BETWEEN. Пример подсчета уникальных id пользователей, зарегистрировавшихся в определенном промежутке времени:
SELECT COUNT(DISTINCT id)
FROM users
WHERE registration_date BETWEEN '2023-01-01' AND '2023-12-31';Такой запрос поможет подсчитать количество уникальных пользователей, зарегистрировавшихся в течение 2023 года.
Как учитывать NULL значения при подсчете уникальных id
При подсчете уникальных значений в SQL запросах NULL значения часто требуют особого внимания. В SQL NULL не считается значением и отличается от любого другого типа данных. Это важно учитывать, так как поведение запросов с функцией COUNT и различными операторами может давать неожиданные результаты, если не обработать NULL значения должным образом.
Когда используется функция COUNT, она игнорирует NULL значения. Например, запрос SELECT COUNT(DISTINCT id) FROM table; вернет количество уникальных значений в столбце id, исключая строки с NULL. Это может привести к недооценке общего числа уникальных id, если NULL значения не были обработаны отдельно.
Чтобы учесть NULL значения при подсчете уникальных id, можно использовать условие CASE или дополнительные функции. Например, если необходимо включить NULL как отдельное уникальное значение, можно выполнить следующий запрос:
SELECT COUNT(DISTINCT CASE WHEN id IS NULL THEN 'NULL' ELSE id END) FROM table;Этот запрос превращает NULL в строку ‘NULL’, что позволяет SQL трактовать его как уникальное значение, включая его в общий подсчет. Важно помнить, что строка ‘NULL’ будет восприниматься как строка, а не как истинное NULL значение, что может влиять на результаты, если типы данных в столбце id отличаются.
Если же необходимо исключить NULL значения из подсчета уникальных id, но сохранить их присутствие в результате выборки, можно использовать фильтрацию через WHERE id IS NOT NULL:
SELECT COUNT(DISTINCT id) FROM table WHERE id IS NOT NULL;Этот подход гарантирует, что NULL значения не будут учитывать при подсчете уникальных id, но они останутся в данных, если понадобится их анализировать отдельно.
Еще один способ учета NULL значений – это использование агрегатных функций с дополнительной логикой. Например, при подсчете уникальных id с учетом их группы можно использовать GROUP BY вместе с условием обработки NULL. Для анализа по группам также можно применять оконные функции, если это необходимо для более сложных аналитических запросов.