Файлы формата CSV часто используются для обмена структурированными данными между системами. Их загрузка в Microsoft SQL Server может быть реализована несколькими способами, включая утилиты командной строки, встроенные средства SQL Server Management Studio (SSMS) и программные интерфейсы на базе T-SQL или .NET. Выбор метода зависит от объёма данных, частоты загрузки и требований к автоматизации.
Если объём данных невелик, целесообразно использовать мастер импорта в SSMS: он позволяет выбрать CSV-файл, указать схему назначения и провести загрузку с пошаговой настройкой. Для периодической загрузки больших объёмов предпочтительнее использовать BULK INSERT или bcp. Эти инструменты поддерживают управление кодировкой, разделителями и правилами обработки ошибок.
Команда BULK INSERT требует минимальной конфигурации: достаточно указать путь к файлу и формат данных. Однако необходимо заранее создать таблицу с соответствующей структурой. При использовании bcp возможна двусторонняя работа – экспорт и импорт, что удобно при интеграции нескольких источников.
Для более гибкой обработки – например, при необходимости валидации или преобразования данных – рекомендуется использовать SQL Server Integration Services (SSIS) или скрипты на C# с подключением через SqlBulkCopy. Эти подходы подходят для регулярной загрузки, в том числе в фоновом режиме или как часть ETL-процесса.
Подготовка CSV-файла для импорта в MS SQL
Перед загрузкой CSV-файла в MS SQL важно убедиться, что структура данных соответствует требованиям целевой таблицы. Файл должен содержать однозначные заголовки столбцов, без пробелов и специальных символов. Рекомендуется использовать только латиницу и символ подчеркивания.
Формат кодировки файла – UTF-8 без BOM. Это предотвратит появление некорректных символов при импорте. Разделителем значений должен быть запятая (,), точка с запятой (;) допустима, но требует соответствующей настройки при импорте.
Каждая строка в файле должна соответствовать одному набору данных, без пропусков. Если в ячейке отсутствует значение, оно должно быть оставлено пустым, без использования «NULL» или других текстовых обозначений.
Формат даты должен соответствовать ISO 8601: YYYY-MM-DD или YYYY-MM-DD hh:mm:ss. Это упрощает парсинг значений SQL Server. Использование других форматов потребует дополнительной обработки.
Числовые значения не должны содержать пробелов, символов валют и группировки. Разделителем дробной части должна быть точка. Пример: 1234.56.
Не допускаются кавычки внутри значений. Если они необходимы, используйте двойные кавычки по стандарту RFC 4180. Пример: «Фраза с «»кавычками»»».
Файл не должен содержать заголовков повторно в середине документа. Один набор заголовков – в первой строке.
Перед импортом проверьте файл в текстовом редакторе или редакторе CSV, исключив скрытые символы и обрезанные строки.
Создание таблицы в MS SQL с учетом структуры CSV
Перед созданием таблицы необходимо изучить структуру CSV-файла. Откройте файл в текстовом редакторе или Excel и определите заголовки, типы данных и возможные значения. Особое внимание следует уделить наличию пустых значений, формату дат, числовым разделителям и символам кавычек.
При создании таблицы используйте оператор CREATE TABLE. Имена столбцов должны совпадать с заголовками в CSV. Для текстовых значений применяйте NVARCHAR, желательно с ограничением длины (например, NVARCHAR(255)), чтобы избежать неоправданного расхода памяти. Для чисел – INT, BIGINT, FLOAT или DECIMAL в зависимости от диапазона и точности. Даты – DATE или DATETIME, исходя из наличия времени.
Если значения в CSV могут быть пустыми, явно указывайте NULL в определении столбца. Учитывайте возможные ограничения: уникальность (UNIQUE), первичный ключ (PRIMARY KEY), обязательность заполнения (NOT NULL), а также допустимость дубликатов. Не добавляйте ограничения без уверенности в корректности и полноте данных в CSV.
Пример создания таблицы:
CREATE TABLE SalesData (
SaleID INT PRIMARY KEY,
ProductName NVARCHAR(255) NOT NULL,
Quantity INT,
Price DECIMAL(10, 2),
SaleDate DATE,
Comment NVARCHAR(MAX) NULL
);После создания таблицы проверьте соответствие типов и структуры: убедитесь, что каждая строка CSV может быть сопоставлена с таблицей без необходимости преобразования данных вручную. Ошибки на этом этапе приведут к сбоям при импорте.
Использование SQL Server Management Studio для импорта CSV
Откройте SQL Server Management Studio и подключитесь к целевому серверу. В проводнике объектов щёлкните правой кнопкой мыши на базе данных, куда нужно загрузить данные, и выберите Tasks → Import Data.
В открывшемся мастере импорта в качестве источника данных выберите Flat File Source. Укажите путь к CSV-файлу. Проверьте параметры разделителя: по умолчанию используется запятая, при необходимости измените на точку с запятой или табуляцию.
На шаге с выбором назначения установите Microsoft OLE DB Provider for SQL Server и укажите параметры подключения. Выберите базу данных из выпадающего списка.
После загрузки структуры файла проверьте названия и типы столбцов. При необходимости отредактируйте сопоставление типов данных. Если в CSV отсутствуют заголовки, снимите соответствующую галочку.
На этапе назначения таблиц можно выбрать существующую таблицу или создать новую. Для создания задайте имя и убедитесь, что предлагаемые типы данных соответствуют содержимому. Поля типа nvarchar чаще подходят для текстовых значений, int – для чисел без десятичной части.
Перед запуском выберите режим выполнения: сразу или генерация SSIS-пакета. Нажмите Finish, чтобы начать импорт. По завершении проверьте журнал операций и откройте таблицу для визуального контроля загруженных данных.
Импорт CSV с помощью команды BULK INSERT

Для импорта CSV-файла в таблицу MS SQL Server применяется команда BULK INSERT. Она позволяет загрузить данные напрямую из текстового файла в таблицу без промежуточных скриптов.
Пример использования:
BULK INSERT dbo.ИмяТаблицы
FROM ‘C:\путь\к\файлу.csv’
WITH (
FIELDTERMINATOR = ‘,’,
ROWTERMINATOR = ‘\n’,
FIRSTROW = 2,
CODEPAGE = ‘65001’,
TABLOCK
);
FIELDTERMINATOR определяет символ-разделитель полей. Для CSV это обычно запятая.
ROWTERMINATOR указывает символ конца строки.
FIRSTROW задаёт номер строки, с которой начинается импорт, исключая заголовок.
CODEPAGE задаёт кодировку файла. UTF-8 соответствует значению 65001.
TABLOCK повышает производительность за счёт блокировки таблицы на время загрузки.
Перед выполнением убедитесь, что служба SQL Server имеет доступ к указанному пути. Если файл размещён на локальной машине, а сервер работает удалённо, путь должен быть сетевым.
Для доступа к локальному файлу используйте SQL Server Management Studio на том же сервере, где работает служба SQL Server, или копируйте файл на сервер вручную.
Если таблица уже содержит данные, проверьте, соответствуют ли столбцы формату CSV. Несоответствие по типам данных приведёт к ошибкам загрузки.
При необходимости обработки ошибок используйте опцию ERRORFILE для логирования строк, которые не удалось загрузить:
ERRORFILE = ‘C:\лог\ошибки.txt’
После загрузки проверьте количество строк, используя SELECT COUNT(*), и сопоставьте его с числом записей в исходном файле.
Импорт CSV через OPENROWSET с включением необходимых параметров
Для импорта CSV-файла с помощью OPENROWSET необходимо, чтобы в SQL Server был включён Ad Hoc Distributed Queries:
EXEC sp_configure 'show advanced options', 1; RECONFIGURE; EXEC sp_configure 'Ad Hoc Distributed Queries', 1; RECONFIGURE;
Файл CSV должен быть доступен серверу по полному пути в файловой системе. Пример запроса с указанием параметров:
SELECT *
FROM OPENROWSET('MSDASQL',
'Driver={Microsoft Text Driver (*.txt; *.csv)};DefaultDir=C:\Data\;',
'SELECT * FROM myfile.csv');
Если необходимо указать кодировку, используется предварительная настройка ODBC или чтение через BULK INSERT. Для OPENROWSET важно, чтобы структура файла соответствовала ожидаемому формату: разделитель – запятая, текст заключён в кавычки (при необходимости), первая строка содержит заголовки.
Альтернативный способ через PROVIDER=’BULK’:
SELECT * FROM OPENROWSET(BULK 'C:\Data\myfile.csv', FORMAT='CSV', PARSER_VERSION='2.0', FIRSTROW=2, FIELDTERMINATOR=',', ROWTERMINATOR='\n' ) AS DataFile;
Параметры:
- FIRSTROW – пропуск строки с заголовками.
- FIELDTERMINATOR – указание разделителя столбцов.
- ROWTERMINATOR – указание разделителя строк.
- PARSER_VERSION=’2.0′ – позволяет использовать формат CSV.
Для корректной работы требуется включить поддержку BULK:
EXEC sp_configure 'show advanced options', 1; RECONFIGURE; EXEC sp_configure 'Ad Hoc Distributed Queries', 1; RECONFIGURE;
Также необходимо убедиться, что учетная запись SQL Server имеет доступ к указанному пути. Относительные пути не поддерживаются.
Обработка ошибок при загрузке CSV в MS SQL
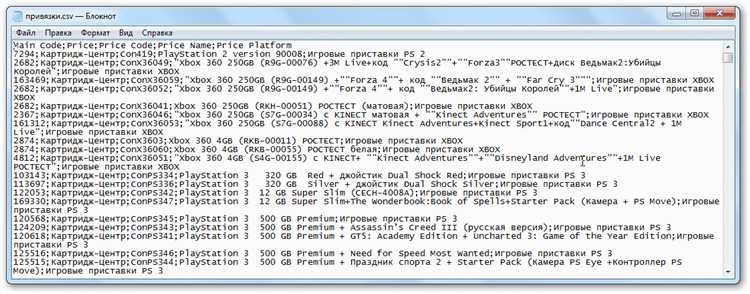
При загрузке данных из CSV в MS SQL могут возникать различные ошибки, связанные с несовпадением форматов, поврежденными файлами или ограничениями самой базы данных. Эффективная обработка этих ошибок помогает минимизировать потерю данных и улучшить стабильность процесса импорта.
Вот основные ошибки и способы их устранения:
- Некорректный формат данных. Одной из распространенных проблем является несоответствие типов данных в CSV и в базе данных. Например, если в CSV указана строка вместо числа или дата в неправильном формате. Чтобы избежать этого, рекомендуется:
- Перед импортом проверить формат каждого столбца CSV, сравнив его с типами данных в таблице MS SQL.
- Использовать предварительный парсинг данных с помощью SQL или внешних инструментов для корректировки форматов.
- Невозможность записи в базу данных. Ошибки могут возникать из-за ограничений на записи в таблицу, таких как первичные ключи, уникальные индексы или ограничения на количество записей. Чтобы минимизировать такие ошибки:
- Удалить дубликаты в CSV-файле перед загрузкой.
- Использовать временные таблицы для проверки данных перед вставкой в основную таблицу.
- Настроить подходящие индексы и ограничения на таблицу, чтобы избежать ошибок при вставке.
- Необходимость обработки пустых значений. CSV файлы часто содержат пустые значения, которые могут вызвать ошибки при попытке вставки. Для их обработки:
- Применить NULL для пустых значений в файле или заменить их значениями по умолчанию.
- Использовать процедуры или триггеры на уровне базы данных для замены или игнорирования пустых значений при вставке.
- Ошибка кодировки. Если CSV файл содержит символы, не поддерживаемые кодировкой базы данных, данные могут быть повреждены. Для предотвращения таких ошибок:
- Проверить кодировку CSV файла перед загрузкой и убедиться, что она совместима с MS SQL (например, UTF-8).
- Использовать инструменты преобразования кодировки для предварительной обработки файла.
- Проблемы с размерами файла. При загрузке больших CSV файлов возможны ошибки из-за ограничения на размер записи или размера файла в MS SQL. Чтобы избежать таких проблем:
- Разбить CSV файл на несколько меньших частей и загружать их поочередно.
- Использовать инструменты загрузки данных, такие как SQL Server Integration Services (SSIS), для обработки больших объемов данных.
- Логирование ошибок. Важно настроить правильное логирование ошибок, чтобы оперативно выявлять проблемы и устранять их. Для этого:
- Использовать встроенные возможности SQL Server для логирования ошибок (например, через TRY-CATCH).
- Настроить отчеты об ошибках, чтобы они включали точную информацию о месте сбоя (например, номер строки и описание ошибки).
Обработка ошибок при загрузке данных из CSV в MS SQL требует внимательности и тестирования на разных этапах. Важно не только правильно настроить процесс, но и предвидеть возможные проблемы, чтобы минимизировать время простоя и потери данных.
Сопоставление типов данных при импорте CSV
При импорте данных из CSV в базу данных MS SQL важно правильно сопоставить типы данных в CSV с типами данных в целевой таблице. Это гарантирует точность и эффективность обработки информации. Ошибки в сопоставлении могут привести к потере данных или нарушениям работы базы данных. Основные шаги для корректного сопоставления:
- Анализ данных CSV – перед импортом нужно внимательно проверить содержимое CSV. Особое внимание уделите числовым данным, датам и строкам. Убедитесь, что в каждой колонке только однотипные данные.
- Выбор типов данных в SQL – для каждого столбца CSV необходимо выбрать соответствующий тип данных в MS SQL. Например:
- Для строковых данных – типы
VARCHARилиTEXT. Выбор зависит от длины строк. - Для числовых данных –
INTилиDECIMAL, в зависимости от точности значений. - Для дат – используйте тип
DATETIMEилиDATE, в зависимости от формата данных в CSV.
- Для строковых данных – типы
- Преобразование данных – если в CSV встречаются данные, несовместимые с типом в MS SQL, их необходимо привести к нужному формату. Например, если в CSV используются даты в формате
DD/MM/YYYY, а в базе данных ожидаетсяYYYY-MM-DD, выполните преобразование перед импортом. - Использование BULK INSERT – для больших объемов данных используйте команду
BULK INSERT. Она позволяет настроить сопоставление типов через опции, такие какFIELDTERMINATORиROWTERMINATOR, которые помогают правильно интерпретировать данные в CSV. - Проверка целостности данных – перед загрузкой данных в таблицу MS SQL рекомендуется создать временную таблицу с наиболее подходящими типами данных, чтобы проверить корректность сопоставления типов. После этого можно скопировать данные в основную таблицу.
Следуя этим рекомендациям, можно избежать множества проблем при импорте данных и обеспечить корректную работу базы данных.
Автоматизация импорта CSV-файлов с помощью SQL Server Agent
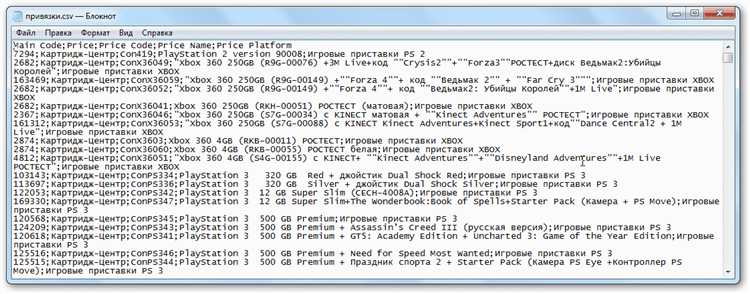
SQL Server Agent позволяет автоматизировать процесс импорта CSV-файлов в базу данных MS SQL, что значительно упрощает повторяющиеся задачи и повышает производительность. Для настройки автоматического импорта необходимо создать SQL Server Agent Job, который будет выполняться по расписанию или по определенному событию.
Первым шагом является подготовка задания для импорта данных. В SQL Server Management Studio (SSMS) создается новый Job, в котором прописывается шаг с использованием процедуры BULK INSERT или других инструментов импорта данных, таких как bcp или Integration Services (SSIS).
Пример использования BULK INSERT:
BULK INSERT Таблица FROM 'C:\Путь\к\файлу.csv' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2 );
Этот запрос загружает данные из CSV-файла в таблицу. Опции FIELDTERMINATOR и ROWTERMINATOR задают разделители полей и строк соответственно. FIRSTROW позволяет пропустить заголовок в файле, если это необходимо.
После создания шага импорта, необходимо настроить расписание для задания. Это можно сделать через вкладку «Schedules» в настройках SQL Server Agent. Установив расписание, можно задать частоту выполнения задания, например, ежедневно или еженедельно, что позволяет автоматизировать процесс импорта данных без вмешательства пользователя.
Кроме того, можно настроить уведомления о статусе выполнения задания. Для этого в SQL Server Agent предусмотрены опции уведомлений по электронной почте или через SQL Server Management Studio, что позволяет быстро реагировать на возможные ошибки во время импорта.
Для более сложных сценариев, таких как обработка нескольких файлов или трансформация данных перед загрузкой, можно использовать SQL Server Integration Services (SSIS). SSIS предоставляет мощные инструменты для работы с данными, включая создание пакетов для обработки и загрузки данных из CSV-файлов в базу данных SQL Server.
Использование SQL Server Agent для автоматизации импорта CSV-файлов позволяет существенно сократить время на выполнение рутинных задач и повысить точность обработки данных.
Вопрос-ответ:
Что делать, если данные в CSV-файле не соответствуют типам данных в таблице SQL?
Если типы данных в CSV-файле не совпадают с типами данных в таблице базы данных, может возникнуть ошибка при загрузке данных. В этом случае рекомендуется предварительно очистить или преобразовать данные. Например, можно использовать инструменты для преобразования типов данных в CSV-файле, такие как Excel или PowerShell. Также возможно использовать промежуточную таблицу с типами данных, совместимыми с CSV-файлом, а затем провести преобразование данных с помощью SQL-запросов, таких как CAST или CONVERT.
Как обработать большие CSV-файлы при их загрузке в базу данных MS SQL?
Для работы с большими CSV-файлами можно использовать несколько методов оптимизации. Во-первых, необходимо убедиться, что файл разделен на более мелкие части, если его размер слишком велик для одного импорта. Использование BULK INSERT с параметрами, такими как MAXERRORS, может помочь избежать ошибок в процессе импорта. Также полезно импортировать данные в несколько этапов с использованием различных промежуточных таблиц, чтобы снизить нагрузку на сервер и ускорить процесс. В случае с большими файлами может быть полезно использовать параллельные потоки для ускорения загрузки данных.
Как можно автоматически загружать CSV-файлы в MS SQL через регулярные интервалы?
Для автоматической загрузки CSV-файлов в базу данных MS SQL можно настроить SQL Server Integration Services (SSIS) или использовать SQL Server Agent для выполнения задания по расписанию. В SSIS создается пакет, который будет выполнять процесс импорта данных из CSV в базу данных. Пакет можно настроить на запуск через определенные интервалы времени. Также возможно использовать T-SQL и планировщик задач Windows для автоматического выполнения команд BULK INSERT или других команд импорта данных на регулярной основе.
Какие могут возникнуть ошибки при загрузке CSV-файлов в MS SQL и как их исправить?
При загрузке CSV-файлов в MS SQL могут возникать различные ошибки, такие как несоответствие форматов данных, ошибки разделителей или проблемы с кодировкой. Для исправления этих ошибок нужно проверить несколько вещей: убедитесь, что разделители в CSV совпадают с теми, которые указаны в команде BULK INSERT, а также что кодировка файла CSV соответствует ожидаемой. Если данные не соответствуют типам данных в таблице, можно использовать команду CONVERT для преобразования типов или изменить структуру таблицы. Если файл содержит строки с ошибками, добавьте параметр MAXERRORS в BULK INSERT, чтобы пропустить их и продолжить загрузку.