Создание и наполнение таблиц в SQL – это не просто ввод данных, а процесс, требующий структурированного подхода. Прежде чем использовать INSERT INTO, необходимо точно определить типы данных для каждого столбца, соответствующие реальному содержимому. Например, для хранения даты регистрации следует применять тип DATE, а не VARCHAR, чтобы обеспечить корректную сортировку и фильтрацию.
При массовом добавлении записей эффективнее использовать множественную вставку: INSERT INTO table_name (col1, col2) VALUES (val1, val2), (val3, val4). Это снижает нагрузку на сервер по сравнению с последовательными одиночными запросами. Кроме того, необходимо контролировать уникальность данных – особенно в колонках с ограничением UNIQUE, чтобы избежать ошибок при вставке.
Если таблица содержит внешний ключ, важно соблюдать порядок заполнения: сначала добавляются записи в родительскую таблицу, затем – в дочернюю. В противном случае возникнет ошибка ограничения ссылочной целостности. Перед массовой загрузкой данных через скрипты или CSV стоит временно отключить индексы и триггеры, чтобы ускорить вставку, и восстановить их после завершения операции.
При работе с автогенерируемыми идентификаторами (AUTO_INCREMENT) избегайте явного указания значения первичного ключа, если это не требуется логикой приложения. Также важно обрабатывать возможные исключения при вставке, например, с помощью конструкции INSERT IGNORE или ON DUPLICATE KEY UPDATE – в зависимости от ситуации.
Как выбрать подходящие типы данных для столбцов
Неправильный выбор типа данных может привести к избыточному использованию памяти, снижению производительности и ошибкам при обработке данных. Чтобы этого избежать, соблюдайте следующие рекомендации.
- Числовые значения: Для счетчиков и идентификаторов используйте
INTилиBIGINT. Если значения не могут быть отрицательными, применяйтеUNSIGNEDварианты. Для денежных сумм избегайтеFLOATиDOUBLE; используйтеDECIMAL(precision, scale)для точности. - Строки: Если длина фиксирована (например, ИНН, код страны), выбирайте
CHAR(n). Для переменной длины текста –VARCHAR(n), но указывайте реальную максимальную длину. Избегайте чрезмерных значений вродеVARCHAR(1000)без обоснования. - Дата и время: Для хранения даты используйте
DATE, для времени –TIME, для комбинации –DATETIMEилиTIMESTAMP, учитывая, чтоTIMESTAMPавтоматически поддерживает зону времени и может использоваться для временных меток изменения записей. - Булевы значения: Для хранения да/нет логики используйте
BOOLEANилиTINYINT(1), в зависимости от СУБД. - Двоичные данные: Для хранения изображений, документов или зашифрованных данных используйте
BLOBилиVARBINARYсоответствующего размера.
Учитывайте специфические ограничения выбранной СУБД: например, в MySQL VARCHAR ограничен 65 535 байт на строку, включая накладные расходы. Анализируйте реальное использование данных – не выбирайте типы «с запасом». Это ухудшает производительность индексов и увеличивает время запросов.
Как задать значения по умолчанию при создании таблицы
Для задания значений по умолчанию используется ключевое слово DEFAULT в определении столбца. Оно позволяет автоматически подставлять заданное значение, если при вставке строки этот столбец не указан.
Пример: создание таблицы users с полем status, принимающим значение 'active' по умолчанию:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL,
status VARCHAR(20) DEFAULT 'active'
);Для числовых полей можно задать числовые значения. Например, поле attempts по умолчанию может начинаться с 0:
attempts INT DEFAULT 0Для даты и времени актуально использовать функции. Например, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP задаёт текущую дату и время при вставке.
Если поле с DEFAULT также указано как NOT NULL, то при отсутствии явного значения будет использоваться значение по умолчанию. Это помогает избежать ошибок при вставке.
Значение по умолчанию должно быть совместимо с типом данных столбца. Ошибки в типах вызывают сбой на этапе создания таблицы.
При изменении уже существующей таблицы для добавления значения по умолчанию используется оператор ALTER TABLE:
ALTER TABLE users ALTER COLUMN status SET DEFAULT 'active';Для удаления значения по умолчанию используется:
ALTER TABLE users ALTER COLUMN status DROP DEFAULT;Как вставить одну строку данных с помощью INSERT INTO
Для добавления одной строки в таблицу SQL используется команда INSERT INTO с явным перечислением столбцов и значений. Это исключает ошибки, связанные с порядком полей и позволяет контролировать, какие именно данные вносятся.
Синтаксис:
INSERT INTO имя_таблицы (столбец1, столбец2, ...) VALUES (значение1, значение2, ...);
Например, чтобы вставить нового пользователя в таблицу users, нужно:
INSERT INTO users (username, email, created_at) VALUES ('ivan_petrov', 'ivan@example.com', '2025-04-24');
Каждое значение должно соответствовать типу данных столбца: строки заключаются в одинарные кавычки, числовые значения указываются без кавычек, даты записываются в формате 'YYYY-MM-DD' или 'YYYY-MM-DD HH:MM:SS'.
Необязательные поля с заданными значениями по умолчанию можно опустить: СУБД подставит их автоматически. Но если поле не допускает NULL и не имеет значения по умолчанию, его обязательно указывать.
Перед вставкой убедитесь, что не нарушаются ограничения: уникальность, внешние ключи, длина текста, формат даты. Иначе операция завершится ошибкой.
Рекомендуется явно указывать названия всех столбцов, даже если вставляются данные во все поля – это делает запрос читаемым и устойчивым к изменениям структуры таблицы.
Как добавить несколько строк данных за один запрос
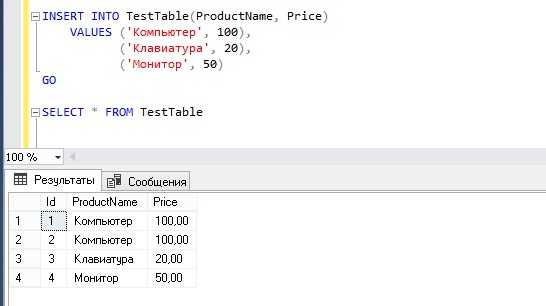
Для вставки нескольких строк в таблицу SQL используется конструкция INSERT INTO с перечислением значений через запятую. Это эффективнее, чем выполнять несколько одиночных запросов.
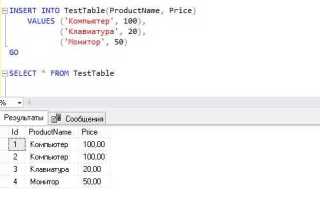
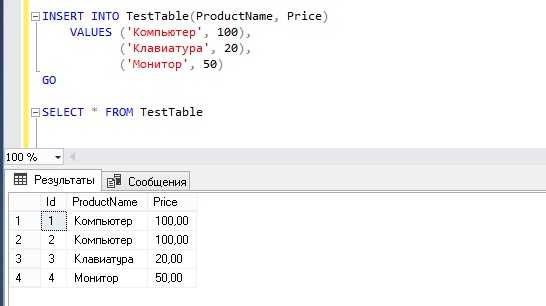
Пример вставки трёх строк в таблицу products:
INSERT INTO products (name, price, stock)
VALUES
('Клавиатура', 1490, 30),
('Мышь', 890, 50),
('Монитор', 12490, 10);
Важно соблюдать порядок и количество колонок, указанных в скобках после имени таблицы. Каждая строка в VALUES должна содержать значения в том же порядке.
Если в таблице есть автоинкрементируемый первичный ключ, его можно не указывать:
INSERT INTO products (name, price, stock)
VALUES
('Наушники', 2290, 15),
('Веб-камера', 3190, 8);
При массовой вставке лучше ограничивать число строк в одном запросе (например, до 1000), особенно при работе с крупными таблицами или в высоконагруженных системах – это снижает риск ошибок и повышает стабильность выполнения.
Для проверки успешной вставки можно использовать SELECT COUNT(*) до и после выполнения запроса или активировать логирование транзакций.
Как избежать ошибок при вставке NULL-значений
При вставке данных в таблицу SQL, ошибки с NULL-значениями часто возникают из-за несоответствия между структурой таблицы и передаваемыми значениями. Прежде всего, убедитесь, что столбцы, не допускающие NULL, явно получают значения. Используйте команду DESCRIBE имя_таблицы, чтобы проверить, какие столбцы имеют ограничение NOT NULL.
Если данные формируются динамически, применяйте условную проверку перед вставкой: исключайте столбцы с отсутствующими значениями из списка вставки или заменяйте NULL значением по умолчанию. Для этого удобно использовать функцию COALESCE(), например: INSERT INTO users (email) VALUES (COALESCE(:email, 'no-reply@example.com')).
При работе с внешними источниками данных применяйте предварительную валидацию. Например, в Python проверьте наличие обязательных полей: if data.get("name") is None: raise ValueError("Name is required").
Используйте ограничение DEFAULT при создании таблиц, чтобы автоматически подставлять значения вместо NULL. Пример: age INT NOT NULL DEFAULT 0.
Если используется ORM, убедитесь, что модели корректно отображают ограничения: в SQLAlchemy указывайте nullable=False и default, чтобы избежать генерации некорректных запросов.
Для отладки используйте директиву SET sql_mode = 'STRICT_ALL_TABLES' в MySQL – она предотвращает вставку NULL в NOT NULL столбцы без значений по умолчанию.
Регулярно проверяйте данные после вставки с помощью запросов SELECT * FROM table WHERE column IS NULL, чтобы выявить ошибки, если они всё же произошли.
Как использовать подзапрос в операторе INSERT
Подзапрос в операторе INSERT позволяет вставить данные в таблицу, полученные из другой таблицы или нескольких таблиц, используя результаты SELECT-запроса. Это особенно полезно, когда нужно выполнить вставку данных, основываясь на вычислениях или фильтрации из других таблиц, без необходимости заранее извлекать их в отдельную переменную.
Синтаксис подзапроса в INSERT выглядит следующим образом:
INSERT INTO таблица (столбец1, столбец2, ...) SELECT значение1, значение2, ... FROM другая_таблица WHERE условие;
Подзапрос можно использовать в случае, если необходимо вставить несколько строк сразу. Например, если нужно скопировать данные из одной таблицы в другую, можно выполнить следующее:
INSERT INTO новая_таблица (id, имя, возраст) SELECT id, имя, возраст FROM старая_таблица WHERE возраст > 18;
Этот запрос скопирует все строки из таблицы «старая_таблица», где возраст больше 18 лет, в таблицу «новая_таблица». Подзапрос позволяет избежать дополнительных шагов с извлечением данных вручную.
При использовании подзапросов важно учитывать несколько моментов. Во-первых, подзапрос должен возвращать те же столбцы, которые ожидаются в целевой таблице. Во-вторых, если подзапрос возвращает более одной строки, то вставка данных будет выполнена для каждой строки, соответствующей результатам подзапроса.
В случае необходимости вставки одного значения, например, агрегированного значения (среднего, суммы и т.д.), можно использовать подзапрос с агрегатной функцией. Например:
INSERT INTO отчет (сумма) SELECT SUM(сумма_продаж) FROM продажи WHERE дата BETWEEN '2025-01-01' AND '2025-12-31';
Здесь данные о сумме продаж за год вставляются в таблицу отчетов. Это удобный способ автоматизировать процесс получения данных из различных источников и вставки их в целевые таблицы без лишних операций с временными переменными.
Таким образом, использование подзапросов в операторе INSERT позволяет эффективно манипулировать данными между таблицами, упрощая их обработку и улучшая производительность запросов.
Как контролировать уникальность данных при вставке
1. Использование ограничения UNIQUE
Для гарантии уникальности значений в одном или нескольких столбцах таблицы используется ограничение UNIQUE. Оно препятствует вставке повторяющихся данных в указанные поля. Например, если в таблице сотрудников email должен быть уникальным, можно определить следующее ограничение:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE
);Этот подход предотвращает вставку нескольких сотрудников с одинаковыми адресами электронной почты.
2. Индексы для проверки уникальности
Вместо явного использования ограничения UNIQUE, можно создать уникальный индекс на столбец или набор столбцов. Это подход эффективно ускоряет поиск и вставку данных, одновременно обеспечивая уникальность. Пример создания уникального индекса:
CREATE UNIQUE INDEX idx_email ON employees(email);При этом индексация будет автоматически проверять наличие повторяющихся значений перед вставкой новых данных.
3. Конструкция INSERT с проверкой наличия записи
Для вставки данных только в случае их отсутствия в таблице используется конструкция INSERT ... ON DUPLICATE KEY UPDATE или аналогичная в других СУБД. В MySQL, например, это будет выглядеть так:
INSERT INTO employees (id, name, email)
VALUES (1, 'John Doe', 'john.doe@example.com')
ON DUPLICATE KEY UPDATE name = VALUES(name);Это позволяет избежать ошибок при попытке вставить дублирующую запись, обновляя другие данные, если запись с таким уникальным ключом уже существует.
4. Использование конструкции WHERE NOT EXISTS
В SQL Server, PostgreSQL и других СУБД можно использовать проверку наличия записи с помощью подзапроса. Этот метод полезен, если необходимо условно вставить данные:
INSERT INTO employees (id, name, email)
SELECT 1, 'John Doe', 'john.doe@example.com'
WHERE NOT EXISTS (SELECT 1 FROM employees WHERE email = 'john.doe@example.com');Этот подход позволяет вставить новые данные только в случае, если в таблице отсутствует запись с таким же значением уникального поля.
5. Использование транзакций
Для обеспечения целостности данных можно обернуть вставку данных в транзакцию. Это особенно полезно при сложных операциях с несколькими таблицами. Например:
BEGIN TRANSACTION;
INSERT INTO employees (id, name, email)
SELECT 1, 'John Doe', 'john.doe@example.com'
WHERE NOT EXISTS (SELECT 1 FROM employees WHERE email = 'john.doe@example.com');
COMMIT;Транзакция гарантирует, что операция будет выполнена атомарно, и в случае ошибок все изменения будут отменены.
6. Использование триггеров
Для реализации более сложной логики проверки уникальности можно использовать триггеры. Например, триггер может проверять, что перед вставкой данных в таблицу выполняются дополнительные проверки на уникальность:
CREATE TRIGGER check_unique_email
BEFORE INSERT ON employees
FOR EACH ROW
BEGIN
IF EXISTS (SELECT 1 FROM employees WHERE email = NEW.email) THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Email already exists';
END IF;
END;Этот метод дает полную гибкость в проверках перед вставкой, но требует дополнительных ресурсов для обработки триггеров.
Контроль уникальности данных – это не просто техническая задача, но и важная часть проектирования базы данных, которая помогает избежать ошибок и улучшить производительность при работе с большими объемами информации.
Как заполнять таблицу данными из CSV-файла
Заполнение таблицы в SQL из CSV-файла можно выполнить несколькими способами в зависимости от используемой СУБД и инструментов. Рассмотрим основные шаги для наиболее популярных методов.
Перед началом важно подготовить CSV-файл. Он должен быть структурирован таким образом, чтобы соответствовать столбцам вашей таблицы. Каждое значение в строках CSV должно совпадать с типом данных в соответствующем столбце базы данных.
1. Использование команды LOAD DATA (MySQL)
В MySQL для импорта данных из CSV-файла в таблицу используется команда LOAD DATA INFILE.
- Убедитесь, что файл CSV доступен серверу MySQL и имеет правильный формат (например, разделён запятыми).
- Используйте следующую команду для импорта:
LOAD DATA INFILE '/путь/к/файлу.csv'
INTO TABLE имя_таблицы
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;Здесь:
FIELDS TERMINATED BYуказывает разделитель полей (например, запятая).ENCLOSED BYуказывает символ, который окружает значения (например, кавычки).IGNORE 1 ROWSпропускает первую строку, если она содержит заголовки.
2. Использование COPY (PostgreSQL)
Для PostgreSQL существует команда COPY, которая позволяет быстро загрузить данные из CSV-файла в таблицу.
- CSV-файл должен быть доступен серверу PostgreSQL.
- Используйте команду в SQL-редакторе или в psql:
COPY имя_таблицы FROM '/путь/к/файлу.csv'
WITH (FORMAT csv, HEADER true, DELIMITER ',');Параметры:
FORMAT csvуказывает формат файла.HEADER trueпропускает заголовки в первой строке.DELIMITERопределяет символ-разделитель.
3. Использование BULK INSERT (SQL Server)
Для SQL Server можно воспользоваться командой BULK INSERT.
- Для работы команды убедитесь, что файл CSV доступен для SQL Server.
- Пример команды для загрузки данных:
BULK INSERT имя_таблицы
FROM 'путь\к\файлу.csv'
WITH (FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2);Параметры:
FIELDTERMINATORуказывает символ, разделяющий поля.ROWTERMINATORуказывает символ, разделяющий строки.FIRSTROWпозволяет пропустить первую строку (если это заголовки).
4. Использование Python и библиотеки pandas
 (пока оценок нет)
(пока оценок нет)