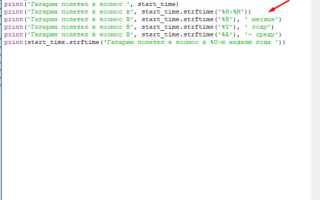
Создание датасета для анализа данных в Python – это важный шаг, который определяет дальнейшую успешность всего проекта. Важно понимать, что подготовка данных не ограничивается только их сбором, но и включает в себя этапы очистки, нормализации и конвертации в удобный формат для работы. На практике процесс создания датасета включает несколько основных этапов: извлечение, предобработка, проверка качества данных и сохранение в нужном формате.
Первым шагом будет извлечение данных. Это можно сделать с помощью библиотеки Pandas, которая поддерживает работу с различными форматами: CSV, Excel, JSON и даже SQL. Например, чтобы загрузить данные из CSV, достаточно воспользоваться функцией pandas.read_csv(), а для работы с базами данных – функцией pandas.read_sql(). Важно сразу определить типы данных, с которыми предстоит работать, чтобы избежать ошибок при их обработке.
После того как данные загружены, нужно провести их предобработку. Это включает в себя такие шаги, как удаление пропусков, обработка выбросов и приведение данных к единому формату. Для удаления пропусков удобно использовать функцию dropna(), а для замены пропусков на медиану или среднее – функцию fillna(). Также стоит учитывать, что данные могут быть представлены в разных единицах измерения, и их нужно нормализовать. Для этого можно использовать библиотеки, такие как sklearn.preprocessing, где доступны различные методы масштабирования и нормализации.
Качество данных играет решающую роль в результатах анализа. Даже небольшие ошибки могут значительно исказить результаты. Для проверки данных на консистентность можно использовать методы для поиска дублированных значений, такие как duplicated(), и проверку на аномалии. Преобразование категориальных данных в числовые с помощью one-hot encoding или label encoding также необходимы, если планируется использование машинного обучения.
Последний этап – сохранение очищенных данных в удобном формате. В Python наиболее распространены форматы CSV и Excel, но также часто используется формат Parquet для более эффективного хранения больших объемов данных. Для сохранения данных в CSV можно использовать метод to_csv(), а для Parquet – to_parquet(). Это позволяет легко делиться датасетами и использовать их в дальнейшем для анализа или обучения моделей.
Как собрать данные с помощью библиотеки Pandas
Библиотека Pandas предоставляет мощные инструменты для сбора данных из различных источников. Чтобы создать датасет, необходимо загрузить данные в объект DataFrame. Основные методы для сбора данных включают чтение файлов, запросы к базам данных и веб-скрейпинг.
Первый способ – загрузка данных из файлов. Pandas поддерживает форматы CSV, Excel, JSON и другие. Для чтения CSV файлов используется метод pd.read_csv(). Например, чтобы загрузить файл «data.csv», достаточно вызвать:
import pandas as pd
data = pd.read_csv('data.csv')Если данные находятся в формате Excel, можно воспользоваться pd.read_excel(), указав путь к файлу и имя листа, если их несколько:
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')Для работы с JSON-файлами используется метод pd.read_json(). Важно, что JSON должен быть в виде структурированных данных, чтобы Pandas корректно его интерпретировал.
Если нужно собрать данные из базы данных, Pandas предоставляет метод pd.read_sql(), который позволяет выполнить SQL-запрос и вернуть результат в DataFrame. Для этого потребуется подключение к базе данных через библиотеку, такую как sqlite3 или SQLAlchemy. Пример подключения к SQLite:
import sqlite3
connection = sqlite3.connect('database.db')
data = pd.read_sql('SELECT * FROM table_name', connection)Для получения данных с веб-страниц можно использовать библиотеку requests в связке с Pandas. После скачивания HTML-страницы с помощью requests.get(), можно использовать метод pd.read_html(), который извлекает таблицы из HTML-кода. Однако важно, чтобы таблицы были структурированы, иначе Pandas может не корректно интерпретировать данные.
Пример загрузки таблицы с веб-страницы:
import requests
url = 'https://example.com/data'
html = requests.get(url).text
data = pd.read_html(html)[0]Также можно собирать данные из API. Для этого используется библиотека requests, после чего полученные данные (например, в формате JSON) можно преобразовать в DataFrame с помощью pd.json_normalize(). Пример получения данных через API:
response = requests.get('https://api.example.com/data')
data_json = response.json()
data = pd.json_normalize(data_json)Таким образом, с помощью Pandas можно собирать данные из различных источников, что делает библиотеку универсальным инструментом для создания датасетов для анализа.
Как использовать библиотеки для парсинга данных из веба
Перед началом работы нужно установить необходимые библиотеки. Для этого в командной строке выполняем:
pip install requests beautifulsoup4 lxml
1. Использование библиотеки requests
Библиотека requests позволяет легко отправлять HTTP-запросы и получать ответ от сервера. Она необходима для скачивания веб-страниц перед их дальнейшим парсингом.
import requests url = 'https://example.com' response = requests.get(url) html_content = response.text
2. Работа с BeautifulSoup
После получения HTML-кода страницы с помощью библиотеки BeautifulSoup можно анализировать и извлекать нужную информацию. Это один из самых удобных инструментов для обработки HTML-документов.
from bs4 import BeautifulSoup soup = BeautifulSoup(html_content, 'html.parser') title = soup.title.string # Извлекаем заголовок страницы
Примеры действий, которые можно выполнить с помощью BeautifulSoup:
- Извлечение текста из тегов:
soup.find('h1').text - Поиск элементов по классу или идентификатору:
soup.find_all('div', class_='example') - Извлечение атрибутов, например, ссылок:
soup.find('a')['href']
3. Преимущества использования lxml
lxml является более быстрым и мощным инструментом для парсинга больших объемов данных. Она поддерживает как HTML, так и XML документы, что делает её удобной для работы с различными структурами данных. Также lxml может работать в сочетании с XPath и XSLT для более сложных запросов.
from lxml import html
tree = html.fromstring(html_content)
links = tree.xpath('//a/@href') # Извлекаем все ссылки с страницы
4. Советы по оптимизации парсинга
- Используйте requests.Session для повторных запросов, чтобы избежать излишней загрузки ресурсов.
- Обрабатывайте ошибки, например, с помощью
try-except, чтобы избежать сбоев при запросах. - Рассмотрите возможность использования Proxy для обхода ограничений по частоте запросов, если парсите большие объемы данных с одного сайта.
- Если структура страницы сложная, комбинируйте использование BeautifulSoup и XPath для достижения наилучшего результата.
5. Примеры реальных задач
- Сбор новостных заголовков с нескольких сайтов с помощью циклов и регулярных выражений для фильтрации данных.
- Парсинг интернет-магазинов для сбора информации о товарах: цены, характеристики, ссылки на изображения.
- Извлечение данных из таблиц HTML для дальнейшего анализа или сохранения в CSV формат.
Как очистить данные: удаление пропусков и аномалий
При работе с данными важно выявить и устранить пропуски и аномалии, так как они могут негативно повлиять на точность анализа. Очистка данных – ключевой шаг в подготовке качественного датасета. Рассмотрим методы, которые помогут эффективно решить эту задачу в Python.
Для начала нужно определить, где в данных есть пропуски. В библиотеке pandas можно использовать функцию isnull(), которая возвращает булеву маску. Пример:
import pandas as pd
df = pd.read_csv('data.csv')
missing_data = df.isnull().sum()Этот код покажет количество пропущенных значений в каждом столбце. Важно помнить, что в некоторых случаях пропуски могут быть неявно представлены, например, строками типа «NaN» или пустыми строками. Для их замены используйте метод fillna():
df.fillna(df.mean(), inplace=True)Такой подход заменяет пропуски на среднее значение по каждому числовому столбцу. Если же нужно удалить строки с пропусками, используйте dropna():
df.dropna(inplace=True)Однако удаление данных может привести к потере информации, поэтому стоит заранее оценить, сколько строк или столбцов придется удалить.
Аномалии – это значения, которые значительно отклоняются от основной массы данных и могут искажать результаты анализа. Для их поиска часто используется метод z-score. Если значение превышает определенный порог (например, 3), оно считается аномальным. В Python это можно реализовать следующим образом:
from scipy import stats
z_scores = stats.zscore(df.select_dtypes(include=['float64', 'int64']))
df_clean = df[(z_scores < 3).all(axis=1)]Этот код удаляет строки, в которых есть аномальные значения по любому числовому столбцу. Важно настроить порог в зависимости от конкретной задачи. В случае, если вы хотите сохранить данные, но исключить слишком экстремальные значения, можно воспользоваться методом интерквартильного диапазона (IQR). Для этого нужно вычислить нижнюю и верхнюю границы данных:
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
df_clean = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]После этого строки, выходящие за пределы этих границ, будут удалены, что позволяет избежать влияния выбросов на модель.
Очистка данных – это не только удаление аномалий и пропусков, но и внимательная настройка методов в зависимости от конкретной ситуации. Важно учитывать контекст данных и цели анализа, чтобы выбрать оптимальный способ очистки.
Как преобразовать данные в нужный формат для анализа
Первый шаг – это загрузка данных в Python. Часто данные поступают в виде CSV или Excel файлов. Для работы с ними используется библиотека pandas. Например, чтобы загрузить данные из CSV, используйте функцию pandas.read_csv():
import pandas as pd
data = pd.read_csv('путь_к_файлу.csv')После загрузки данных необходимо проверить их структуру. С помощью метода data.info() можно узнать количество строк и столбцов, типы данных и наличие пропущенных значений.
Если данные загружены в неудобном формате, например, в виде строковых значений, которые должны быть числовыми, их нужно привести к нужному типу с помощью метода pandas.astype():
data['column_name'] = data['column_name'].astype(float)Важно также обработать пропущенные значения. Это можно сделать несколькими способами. Один из них – это использование метода fillna(), чтобы заменить пропуски на среднее значение:
data['column_name'] = data['column_name'].fillna(data['column_name'].mean())Для анализа временных рядов часто требуется преобразовать строковое представление даты в формат datetime. В pandas это можно сделать с помощью функции pd.to_datetime():
data['date_column'] = pd.to_datetime(data['date_column'], format='%Y-%m-%d')Если данные содержат текстовую информацию, которую нужно представить в числовом формате, например, категориальные переменные, стоит использовать метод pandas.get_dummies(), который преобразует такие переменные в набор бинарных признаков:
data = pd.get_dummies(data, columns=['category_column'])После обработки и преобразования данных важно проверить их на наличие дубликатов. Это можно сделать с помощью метода drop_duplicates():
data = data.drop_duplicates()Для работы с большими объемами данных часто требуется их нормализация или стандартизация. Для этого можно воспользоваться библиотеками sklearn. Пример нормализации данных с помощью MinMaxScaler:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['column_name']] = scaler.fit_transform(data[['column_name']])После всех преобразований данные готовы к анализу и моделированию. Важно помнить, что каждый этап должен быть ориентирован на требования конкретной задачи, и иногда может потребоваться дополнительная очистка данных, например, удаление выбросов или преобразование категориальных переменных в более подходящие формы.
Как объединить несколько источников данных в один датасет
Объединение нескольких источников данных в один датасет – ключевая задача при подготовке данных для анализа. В Python существует несколько способов выполнения этой задачи, включая использование библиотек pandas и numpy. Рассмотрим основные методы с примерами.
Для объединения данных можно использовать два подхода: объединение по индексам или по значениям в столбцах. В зависимости от типа данных и их структуры, выбирается соответствующий метод.
1. Объединение по индексам
Метод concat из библиотеки pandas позволяет объединить несколько датафреймов по индексам. Этот способ полезен, если источники данных имеют одинаковую структуру и нужно объединить их по строкам или столбцам.
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
result = pd.concat([df1, df2], ignore_index=True)
print(result)
При этом можно указать параметр ignore_index=True, чтобы перегенерировать индексы для итогового датафрейма.
2. Объединение по столбцам
Если данные из разных источников должны быть объединены по столбцам, например, чтобы добавить новые признаки или данные о тех же объектах, можно использовать метод merge. Он позволяет объединить два датафрейма по одному или нескольким столбцам.
df1 = pd.DataFrame({'id': [1, 2], 'A': [1, 2]})
df2 = pd.DataFrame({'id': [1, 2], 'B': [3, 4]})
result = pd.merge(df1, df2, on='id')
print(result)
Здесь on='id' указывает, что объединение происходит по столбцу id. Также можно использовать другие параметры, такие как how для указания типа объединения (например, внутреннее inner, внешнее outer и т.д.).
3. Объединение с разными столбцами
В случае, когда датафреймы содержат различные столбцы, можно использовать метод join. Этот метод позволяет объединять данные по индексам с возможностью выбора дополнительных столбцов.
df1 = pd.DataFrame({'A': [1, 2]}, index=[1, 2])
df2 = pd.DataFrame({'B': [3, 4]}, index=[2, 3])
result = df1.join(df2, how='outer')
print(result)
Метод join также предоставляет гибкие настройки для выбора типа объединения: left, right, outer и inner.
4. Слияние по нескольким ключам
Если для объединения данных необходимо использовать несколько столбцов, в методах merge и join можно указать список столбцов. Это полезно, когда требуется комбинировать данные по нескольким признакам.
df1 = pd.DataFrame({'id': [1, 2], 'date': ['2021-01-01', '2021-01-02'], 'A': [1, 2]})
df2 = pd.DataFrame({'id': [1, 2], 'date': ['2021-01-01', '2021-01-02'], 'B': [3, 4]})
result = pd.merge(df1, df2, on=['id', 'date'])
print(result)
В данном примере данные объединяются по двум столбцам: id и date.
5. Устранение дубликатов
При объединении источников данных часто возникают дублирующиеся строки или столбцы. Для очистки данных от дубликатов можно использовать метод drop_duplicates.
result = result.drop_duplicates()
print(result)
Метод drop_duplicates удаляет все повторяющиеся строки, оставляя только уникальные данные.
6. Обработка отсутствующих значений
При объединении данных могут возникнуть пропуски в некоторых столбцах. Метод fillna позволяет заполнить их определёнными значениями. Это важно для обеспечения целостности данных перед их анализом.
result = result.fillna(0)
print(result)
Вместо 0 можно подставить любое значение в зависимости от требований к данным.
Заключение
Объединение нескольких источников данных в один датасет требует внимательности и понимания структуры данных. Выбор метода зависит от типа данных и необходимого результата. Используя concat, merge, join, а также инструменты для очистки и обработки пропусков, можно эффективно работать с различными источниками данных и получать готовые к анализу датасеты.
Как работать с большими данными в Python

Работа с большими данными в Python требует эффективных инструментов для хранения, обработки и анализа данных. Существует несколько подходов и библиотек, которые могут существенно ускорить работу с массивами данных, превышающими память устройства.
Для начала, важно правильно управлять памятью. Использование библиотек, таких как Dask, позволяет распределить вычисления на несколько ядер или даже серверов. Это даёт возможность работать с данными, которые не помещаются в память одного компьютера. Dask поддерживает знакомые библиотеки, например, pandas и numpy, и позволяет проводить аналогичные операции с большими объемами данных.
Если данные размещены в файлах (например, CSV или Parquet), можно использовать библиотеки, оптимизированные для работы с большими файлами. Например, библиотека Vaex позволяет эффективно работать с миллиардами строк данных, выполняя операции без загрузки всего набора в память. Vaex использует виртуальную память, позволяя производить вычисления на диск, что существенно экономит ресурсы.
При обработке данных на большом объеме важную роль играет эффективная агрегация и фильтрация. Библиотека PySpark, основанная на распределенных вычислениях, позволяет работать с данными, хранящимися в Hadoop или Spark. PySpark эффективно масштабируется, обрабатывая данные с распределенных вычислительных кластеров. Для выполнения агрегаций, фильтраций и других операций на данных в режиме реального времени эта библиотека идеально подходит.
Важно также правильно выбирать типы данных. Например, вместо использования стандартных типов данных в pandas, можно применять более компактные форматы хранения, такие как категориальные данные. Это позволяет сократить объем памяти при обработке данных, что особенно полезно при анализе больших наборов текстовых данных, например, при работе с уникальными идентификаторами или строковыми значениями.
Для хранения больших объемов данных полезно использовать форматы, которые поддерживают сжатие. Формат Parquet, например, является одним из наиболее эффективных форматов для хранения структурированных данных. Он поддерживает колонковое хранение данных, что позволяет быстрее загружать и обрабатывать только нужные столбцы, не затрагивая все данные целиком.
Наконец, использование базы данных или распределенных хранилищ, таких как Apache HBase или Amazon Redshift, позволяет эффективно работать с данными, находящимися в облаке или на удаленных серверах. Это решает проблему с производительностью и масштабируемостью при анализе данных, превышающих память локального устройства.