Удаление пробелов в строках – частая задача при обработке текстовых данных. В Python для этого доступно несколько подходов, каждый из которых решает конкретную подзадачу: удаление пробелов в начале и в конце строки, между словами или всех пробелов сразу.
Функции strip(), lstrip() и rstrip() удаляют пробелы с соответствующих сторон строки. Например, ‘ пример ‘.strip() вернёт ‘пример’, устраняя пробелы только по краям.
Если требуется удалить все пробелы внутри строки, используют метод replace(): строка.replace(‘ ‘, ») уберёт каждый пробел. Для более гибкой фильтрации применяют re.sub() из модуля re, позволяющий удалять все виды пробельных символов, включая табуляции и переносы строк: re.sub(r’\s+’, », строка).
Важно понимать контекст задачи: не всегда уместно удалять все пробелы без исключения. Например, при нормализации текста для дальнейшего анализа часто требуется заменить множественные пробелы одним, а не удалять их полностью. В таких случаях используется re.sub(r’\s+’, ‘ ‘, строка).
Удаление всех пробелов внутри строки
Для удаления всех пробелов из строки используйте метод replace() с указанием пробела в качестве первого аргумента и пустой строки – второго: s.replace(‘ ‘, »). Это заменит все вхождения символа пробела, включая те, что между словами.
Если требуется удалить все виды пробельных символов, включая табуляции и неразрывные пробелы, примените регулярные выражения:
import re
s = re.sub(r'\s+', '', s)Выражение \s+ охватывает пробелы, табуляции, переводы строк и другие подобные символы. Такая замена особенно полезна при обработке данных из внешних источников, где могут встречаться нестандартные пробелы.
Если строка состоит только из текста и обычных пробелов, предпочтительнее использовать replace() – он работает быстрее и не требует подключения модуля re.
Удаление начальных и конечных пробелов
Для удаления пробелов с начала и конца строки используется метод strip(). Он возвращает новую строку без ведущих и замыкающих пробельных символов, включая пробелы, табуляции и переводы строк.
Пример:
текст = " пример строки "
результат = текст.strip()
print(результат) # 'пример строки'Если необходимо удалить только с начала – применяют lstrip():
текст = " начало"
результат = текст.lstrip()
print(результат) # 'начало'Для удаления только в конце – rstrip():
текст = "конец "
результат = текст.rstrip()
print(результат) # 'конец'Методы strip, lstrip и rstrip не изменяют исходную строку, так как строки в Python неизменяемы. Чтобы сохранить результат, требуется присвоение новой переменной или перезапись старой.
По умолчанию удаляются все символы из набора whitespace (' \t\n\r\x0b\x0c'). При необходимости можно указать конкретные символы:
текст = ">>>данные<<<"
результат = текст.strip("><")
print(результат) # 'данные'Удаление только начальных пробелов
Для удаления исключительно ведущих пробелов применяется метод lstrip(). Он возвращает копию строки без пробелов в начале, оставляя остальные символы нетронутыми. Пример:
строка = " пример"
результат = строка.lstrip()
print(результат) → "пример"
Метод lstrip() также принимает аргумент – строку символов, которые нужно убрать. Чтобы удалить только пробелы, можно явно указать их:
строка.lstrip(' ')
Если в начале строки встречаются табуляции или другие пробельные символы, а требуется удалить только пробелы, lstrip(' ') обеспечит избирательность. При необходимости избавиться от всех типов ведущих пробельных символов – используйте lstrip() без аргументов.
Для обработки нескольких строк, например в списке, используйте генератор списков:
очищенные = [s.lstrip() for s in список]
Этот метод не изменяет исходные строки – возвращается новая версия. Чтобы сохранить результат, присвойте его переменной или перезапишите исходную.
Удаление только конечных пробелов
Для удаления пробелов в конце строки используется метод rstrip(). Он не изменяет исходную строку, а возвращает новую с обрезанными правыми пробелами.
s.rstrip()– удаляет все пробельные символы справа, включая пробелы, табуляции и переводы строки.s.rstrip(' ')– удаляет только пробелы, игнорируя другие символы вроде\tили\n.
Примеры:
s = "данные "
результат = s.rstrip()
# 'данные'
s = "данные\t\n "
результат = s.rstrip(' ')
# 'данные\t\n'
Если требуется сохранить другие правые символы, передайте их явно как аргумент. Метод не влияет на пробелы в начале строки или внутри текста.
Замена последовательности пробелов одним пробелом
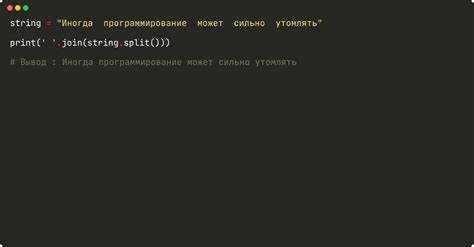
Для замены подряд идущих пробелов на один используется модуль re. Метод re.sub() позволяет сократить любые повторяющиеся пробелы до одного:
import re
s = 'Это пример строки с лишними пробелами'
s = re.sub(r'\s+', ' ', s)
print(s)
Регулярное выражение \s+ охватывает все виды пробельных символов: пробел, табуляцию, перевод строки. Подстановка ' ' оставляет только один обычный пробел вместо всей последовательности. Такой подход полезен для предварительной очистки текстов перед разбором или анализом.
Если необходимо также удалить пробелы в начале и конце строки, добавьте метод strip():
s = re.sub(r'\s+', ' ', s).strip()
При работе с большими объемами текста стоит избегать многократного вызова replace(), так как он неэффективен при последовательной замене множественных пробелов. Регулярные выражения работают быстрее и точнее.
Удаление пробелов между словами с сохранением первого символа каждого слова
Для получения строки, в которой сохраняются только первые буквы каждого слова, а все пробелы между словами удаляются, применяется комбинация методов split(), strip() и join().
Пример:
text = " Пример строки с лишними пробелами "
result = ''.join(word[0] for word in text.strip().split() if word)
strip() удаляет внешние пробелы, split() разбивает строку на слова, игнорируя лишние пробелы, join() объединяет первые символы в итоговую строку без пробелов.
Если важно сохранить регистр или провести дополнительную фильтрацию, можно использовать генератор с условием:
result = ''.join(word[0] for word in text.strip().split() if word and word[0].isalpha())
Такой подход исключает символы, не являющиеся буквами, и гарантирует, что обрабатываются только значимые элементы строки.
Удаление неразрывных пробелов и управляющих символов
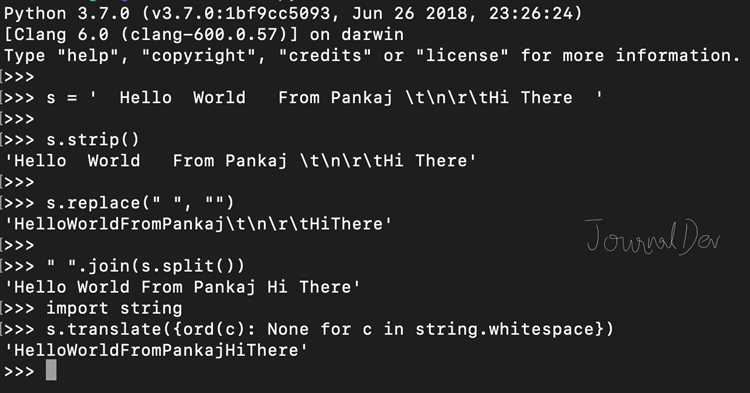
Неразрывные пробелы и управляющие символы (такие как символы новой строки, табуляции) могут встречаться в строках текста и мешать корректной обработке данных. В Python для их удаления существует несколько эффективных методов.
Неразрывные пробелы (UTF-8 код: U+00A0) часто встречаются при копировании текста с веб-страниц. Для их удаления можно использовать метод replace():
text = text.replace("\u00A0", " ")
Этот способ заменяет все неразрывные пробелы на обычные пробелы. Однако, для удаления неразрывных пробелов и всех других управляющих символов стоит использовать регулярные выражения.
Для удаления всех управляющих символов (табуляций, переносов строк и других невидимых символов) можно воспользоваться модулем re. В следующем примере показано, как удалить все пробелы, включая неразрывные и управляющие символы:
import re
text = re.sub(r'[\s\u00A0]+', '', text)
Здесь регулярное выражение [\s\u00A0]+ удаляет все пробельные символы, включая неразрывные пробелы, символы новой строки, табуляции и другие невидимые символы. Важно, что символы новой строки могут быть как типичными (например, \n), так и неразрывными, так что регулярное выражение охватывает оба типа.
Если необходимо удалить только неразрывные пробелы, не трогая другие символы, можно использовать следующее регулярное выражение:
text = re.sub(r'\u00A0', '', text)
Такой подход помогает гарантировать, что другие пробельные символы (например, обычные пробелы и табуляции) останутся без изменений.
Для более сложных сценариев, например, удаления нескольких видов управляющих символов одновременно, можно комбинировать различные регулярные выражения или использовать метод translate():
text = text.translate(str.maketrans('', '', '\u00A0\n\t'))
Этот метод позволяет точно указать, какие символы должны быть удалены, и применить изменения за один шаг.
Таким образом, удаление неразрывных пробелов и управляющих символов можно выполнять различными способами, каждый из которых имеет свои преимущества в зависимости от контекста задачи.
Удаление пробелов в списке строк
В Python для работы с пробелами в строках часто используют методы строк, такие как strip(), lstrip() и rstrip(). Но когда нужно удалить пробелы из всех элементов списка строк, подход немного меняется.
Для этого можно применить функцию map(), которая позволяет обработать каждую строку в списке, либо использовать генератор списков. Оба способа эффективны, но использование генератора часто выглядит более компактно.
Пример с использованием map():
strings = [" Пример 1 ", " Пример 2", "Пример 3 "]
cleaned_strings = list(map(lambda x: x.strip(), strings))
Здесь для каждого элемента списка вызывается метод strip(), который удаляет пробелы с обеих сторон строки. Если нужно удалить пробелы только с начала или конца строки, можно использовать lstrip() или rstrip() соответственно.
Пример с генератором списков:
strings = [" Пример 1 ", " Пример 2", "Пример 3 "]
cleaned_strings = [s.strip() for s in strings]
Генераторы списков обеспечивают более явную синтаксическую форму и лучше читаются, особенно когда необходимо выполнить дополнительные операции с элементами списка.
Если задача состоит в удалении пробелов только между словами внутри строк, можно использовать метод split() для разбиения строки и join() для её восстановления:
strings = [" Пример 1 текст ", " Пример 2 "]
cleaned_strings = [' '.join(s.split()) for s in strings]
Этот код удалит лишние пробелы между словами в каждой строке, оставив только один пробел между словами. Применение этого метода полезно, если в строках присутствуют множественные пробелы, которые нужно нормализовать.
Важно помнить, что методы удаления пробелов не изменяют оригинальные строки, а возвращают новые. Таким образом, при обработке больших списков строк следует учитывать возможные затраты на память, если не использовать генераторы.
Вопрос-ответ: