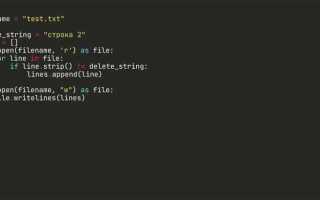
Работа с текстовыми данными в Python часто требует удаления лишних символов, включая пробелы. Это может быть критически важно при сравнении строк, очистке пользовательского ввода или подготовке данных к сериализации. Простое удаление всех пробелов из строки позволяет значительно упростить последующую обработку данных.
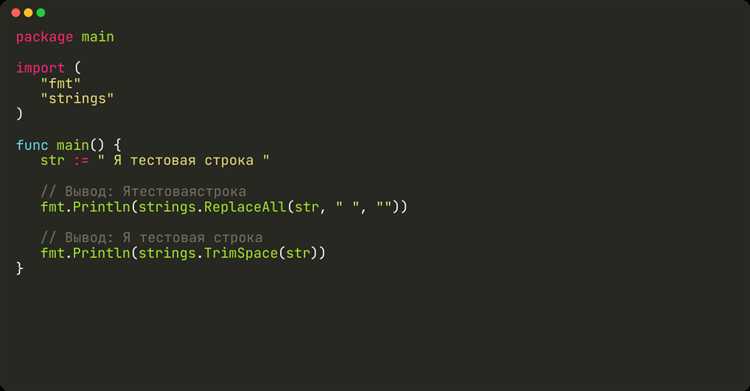
В Python задача решается несколькими способами. Метод replace() позволяет удалить пробелы, заменяя их на пустую строку: s.replace(» «, «»). Однако он обрабатывает только обычные пробелы, игнорируя другие виды пробельных символов, такие как табуляция (\t) и перевод строки (\n).
Для полного удаления всех типов пробельных символов рекомендуется использовать модуль re и регулярное выражение: re.sub(r»\s+», «», s). Это решение охватывает все варианты пробелов, включая неразрывные и управляющие символы. Такой подход особенно эффективен при обработке данных из внешних источников, где тип пробела заранее неизвестен.
Важно учитывать, что методы удаления пробелов изменяют строку, возвращая её копию. Строки в Python неизменяемы, поэтому операция s = s.replace(» «, «») обязательна для сохранения результата. Пренебрежение этим может привести к незаметным ошибкам в логике программы.
Как удалить все пробелы с помощью метода replace()

Метод replace() позволяет заменить все вхождения заданной подстроки в строке. Чтобы удалить пробелы, нужно заменить их на пустую строку:
пример:
text = "Пример строки с пробелами"
text_no_spaces = text.replace(" ", "")
print(text_no_spaces) # Результат: "Примерстрокиспробелами"Метод работает с любым количеством пробелов в любом месте строки. Он чувствителен к точному символу, поэтому не удалит табуляции (\t) и неразрывные пробелы (\xa0). Чтобы обработать такие случаи, используйте цепочку replace():
text = text.replace(" ", "").replace("\t", "").replace("\xa0", "")Этот способ эффективен при обработке заранее известного набора символов. Он не требует регулярных выражений и работает быстрее, если объём текста невелик и структура данных предсказуема.
Удаление пробелов с использованием генераторов списков
Генераторы списков позволяют удалить пробелы из строки без использования встроенных методов замены. Это особенно полезно, когда требуется контролировать фильтрацию символов или сохранить только определённые типы символов.
Пример базового использования:
строка = "П р и м е р с т р о к и"
результат = ''.join([символ for символ in строка if символ != ' '])
Варианты применения:
- Удаление только одиночных пробелов:
if символ != ' ' - Фильтрация всех пробельных символов (включая табуляции, переводы строк):
if not символ.isspace()
Использование if not символ.isspace() рекомендуется при очистке текста, полученного из внешних источников, где возможны нестандартные пробелы.
Преимущества подхода:
- Гибкость фильтрации
- Высокая читаемость
- Поддержка любых условий удаления
Генератор списков можно дополнить логикой, например:
''.join([с for с in строка if с.isalnum()]) # Удаляет всё, кроме букв и цифрЭто даёт возможность не только убирать пробелы, но и адаптировать фильтрацию под нужды конкретной задачи.
Применение регулярных выражений для удаления пробелов
Модуль re в Python позволяет удалить все пробелы из строки с максимальной гибкостью. Для этого используется шаблон \s+, который охватывает не только обычные пробелы, но и табуляции, переводы строк и другие пробельные символы Unicode.
Пример удаления всех пробелов:
import re
s = "Текст с пробелами и табуляцией\tа также\nпереносами"
результат = re.sub(r"\s+", "", s)
print(результат)
Функция re.sub() заменяет все последовательности пробельных символов на пустую строку. Регулярное выражение \s+ гарантирует удаление любого количества пробелов подряд, включая нестандартные символы-разделители.
Если требуется удалить только обычные пробелы, но оставить табуляции и переводы строк, используйте » « вместо \s:
результат = re.sub(" ", "", s)
Для повышения производительности при множественной обработке строк рекомендуется заранее компилировать шаблон:
pattern = re.compile(r"\s+")
результат = pattern.sub("", s)
Регулярные выражения особенно эффективны при работе с большими объемами текста или при необходимости точного контроля над типами удаляемых символов.
Удаление пробелов во всех строках списка
Если список содержит строки с пробелами, для их удаления применяют генераторы списков с методами строк. Важно использовать str.replace() или str.translate() для точечного контроля над результатом.
Пример с replace:
data = [' текст ', 'е ще один ', 'стр ока']
cleaned = [s.replace(' ', '') for s in data]Метод replace(‘ ‘, ») удаляет только обычные пробелы. Если необходимо избавиться от всех видов пробельных символов, включая табуляцию и неразрывные пробелы, лучше использовать re.sub():
import re
data = [' текст\t', 'е\u00a0ще\u2003один ', 'стр ока']
cleaned = [re.sub(r'\s+', '', s) for s in data]Функция re.sub(r’\s+’, », s) удаляет все пробельные символы, включая Unicode-пробелы. Это особенно важно при обработке данных, полученных из внешних источников, где часто встречаются нестандартные пробелы.
Если список может содержать не только строки, добавьте фильтрацию:
cleaned = [re.sub(r'\s+', '', s) if isinstance(s, str) else s for s in data]Это предотвращает ошибки при наличии чисел, None или других типов данных в списке.
Обработка строк с табуляцией и неразрывными пробелами
При удалении всех пробелов из строки важно учитывать не только обычные пробелы (' '), но и скрытые символы, такие как табуляция ('\t') и неразрывный пробел ('\xa0'). Эти символы не удаляются методом str.replace(' ', ''), так как имеют иное представление в памяти.
Для корректной очистки строки от всех видов пробелов используйте модуль re, позволяющий задать диапазон символов пробельной категории:
import re
s = '\tЭто\xa0тестовая строка\n'
result = re.sub(r'\s+', '', s)
\s+ охватывает табуляции, переводы строк, обычные и неразрывные пробелы. Если требуется удалить только пробельные символы, не затрагивая другие управляющие, используйте составной класс символов:
result = re.sub(r'[ \t\xa0]+', '', s)
Такой подход исключает удаление переносов строк и других управляющих символов, сохраняя структуру текста. Для обнаружения специфических символов удобно использовать ord() и repr():
for c in s:
print(f'{repr(c)} -> {ord(c)}')
Неразрывный пробел идентифицируется как '\xa0' с кодом 160. Учитывайте это при парсинге данных из HTML или текстов, скопированных из документов, где такие символы часто используются автоматически.
Удаление пробелов в строках, полученных из пользовательского ввода
В Python для обработки строк, полученных от пользователя, нередко возникает необходимость удаления пробелов. Особенно это важно для нормализации ввода, где лишние пробелы могут повлиять на дальнейшую обработку данных. Основные методы удаления пробелов включают функции strip(), lstrip(), rstrip() и replace().
Метод strip() удаляет пробелы с обеих сторон строки. Это наиболее часто используемый способ, когда нужно избавиться от пробелов в начале и в конце строки:
input_string = input("Введите строку: ")
cleaned_string = input_string.strip()
Если необходимо удалить пробелы только с левой или правой стороны строки, используйте методы lstrip() или rstrip() соответственно:
left_cleaned = input_string.lstrip() right_cleaned = input_string.rstrip()
Если в строках могут встречаться лишние пробелы внутри текста, то для их удаления лучше использовать метод replace(). Он заменяет все пробелы на пустые строки:
input_string = input("Введите строку с пробелами: ")
no_spaces = input_string.replace(" ", "")
Для обработки строк, полученных из ввода, важно учитывать возможное наличие невидимых символов, таких как табуляции или переводы строк. В таких случаях можно комбинировать методы с регулярными выражениями, используя модуль re. Например, для удаления всех пробелов и управляющих символов:
import re cleaned_string = re.sub(r'\s+', '', input_string)
Каждый из этих методов позволяет эффективно и гибко очищать строку от пробелов в зависимости от конкретных требований. Важно выбрать подходящий метод в зависимости от контекста задачи: удаление пробелов только по краям или очистка всей строки от лишних пробелов.
Сравнение строк до и после удаления пробелов
Удаление пробелов из строки может существенно изменить её содержимое, что важно учитывать при сравнении строк. Пробелы в строках часто используются для разделения слов, чисел или других значений, но иногда они могут быть лишними, особенно в случаях, когда точность данных имеет ключевое значение.
Когда необходимо сравнить строки с пробелами и без, важно учитывать, что пробелы влияют на длину строки и её хеширование. Например, две строки, которые визуально похожи, но содержат пробелы в разных местах, будут рассматриваться как разные при сравнении:
«`python
str1 = «Hello world»
str2 = «Helloworld»
Здесь строки различаются по длине и содержанию, несмотря на схожесть текста. После удаления пробела, например, с помощью метода replace(), строки станут одинаковыми:
«`python
str1 = str1.replace(» «, «»)
str2 = str2.replace(» «, «»)
Теперь обе строки будут идентичны, и при сравнении с использованием оператора == результат будет True.
Однако стоит учитывать, что в некоторых случаях пробелы могут быть важными для контекста. Например, в строках с разделёнными словами или фразами удаление пробелов приведёт к их объединению, что изменит значение строки.
Сравнение строк до и после удаления пробелов может быть полезным для очистки данных, нормализации входных значений или при поиске и удалении лишних пробелов. Однако важно учитывать контекст задачи и, если пробелы несут смысловую нагрузку, не забывать о необходимости их сохранения.