Работа с данными в Python часто предполагает необходимость удаления дублирующихся элементов из коллекций, особенно из списков. Это стандартная задача, которая встречается в повседневном программировании. В Python существует несколько эффективных способов, каждый из которых имеет свои особенности и применимость в разных ситуациях.
Самый простой и быстрый метод удаления дубликатов из списка – это использование встроенной структуры данных set. Множества в Python не допускают повторений, поэтому преобразование списка в множество и обратно в список автоматически исключает все дубли. Этот способ подходит, если порядок элементов не важен.
Если необходимо сохранить порядок элементов, то подход с преобразованием в множество не подойдет. Вместо этого можно использовать цикл, проверяя каждый элемент на наличие в новом списке. Такой метод требует немного больше кода, но позволяет контролировать порядок появления элементов в результате.
Для больших списков, где важна производительность, рекомендуется использовать dict.fromkeys(). Этот метод работает аналогично множествам, но сохраняет порядок элементов, начиная с Python 3.7. Важно помнить, что использование таких подходов экономит время при удалении дубликатов, но не всегда подходит, если необходимо учитывать более сложные условия для проверки уникальности.
В зависимости от контекста задачи, подходы к удалению дубликатов могут варьироваться, и важно выбрать тот, который оптимально решает задачу с учетом как производительности, так и требований к порядку элементов.
Использование множества для удаления дубликатов
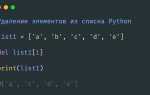
Пример использования множества для удаления дубликатов из списка:
my_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = list(set(my_list))
print(unique_list)В результате выполнения кода список будет содержать только уникальные элементы. Однако порядок элементов при этом может быть изменен, так как множества не сохраняют порядок элементов.
Если важно сохранить порядок, можно воспользоваться следующим подходом:
my_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = []
seen = set()
for item in my_list:
if item not in seen:
unique_list.append(item)
seen.add(item)
print(unique_list)Этот код сохраняет оригинальный порядок элементов, при этом избегая дублирования. Метод эффективен и полезен в тех случаях, когда важна как уникальность элементов, так и их последовательность.
Удаление дубликатов с сохранением порядка элементов
Для удаления дубликатов из списка в Python с сохранением исходного порядка элементов можно использовать несколько подходов. Один из них – использование структуры данных `set` для проверки уникальности и сохранения порядка.
Рассмотрим, как это сделать, используя Python и встроенные функции:
Основной задачей является обход всех элементов списка и добавление их в новый список, если они еще не встречались. Для этого подходит комбинация списка и множества:
def remove_duplicates(input_list): seen = set() result = [] for item in input_list: if item not in seen: result.append(item) seen.add(item) return result
В данном коде:
seen– множество, которое хранит уже встреченные элементы. Множество позволяет эффективно проверять наличие элемента.result– новый список, в который добавляются только уникальные элементы, встреченные в ходе обхода.
Этот способ гарантирует сохранение порядка элементов, так как элементы добавляются в новый список в том порядке, в котором они были встречены в исходном.
Также можно использовать функцию dict.fromkeys(), которая позволяет удалить дубликаты и сохранить порядок за счет того, что ключи словаря уникальны:
def remove_duplicates(input_list): return list(dict.fromkeys(input_list))
Этот метод работает за время O(n), так как словарь поддерживает уникальность ключей и сохраняет порядок добавления элементов в Python 3.7 и выше.
Оба подхода являются оптимальными с точки зрения производительности, так как обход списка и добавление элементов в множество или словарь выполняется за время O(1). Выбор между ними зависит от предпочтений, но использование dict.fromkeys() делает код короче и проще.
Применение list comprehension для фильтрации уникальных значений
Пример простого использования list comprehension для фильтрации уникальных значений:
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = [x for x in set(original_list)]
Однако, такой подход не сохраняет порядок элементов. Если порядок важен, то можно воспользоваться дополнительной логикой для получения уникальных элементов с сохранением порядка их появления:
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = []
[unique_list.append(x) for x in original_list if x not in unique_list]
В этом примере list comprehension выполняет фильтрацию, добавляя элемент в новый список только в случае, если его ещё нет в unique_list. Это сохраняет порядок, но может быть менее эффективным на больших данных из-за использования операции not in, которая имеет линейную сложность.
Для ускорения можно применить структуру данных set для отслеживания уже встреченных элементов, что улучшает производительность:
original_list = [1, 2, 2, 3, 4, 4, 5]
seen = set()
unique_list = [x for x in original_list if not (x in seen or seen.add(x))]
Здесь используется метод set.add(x), который добавляет элемент в множество и возвращает None. Это позволяет эффективно проверять наличие элемента и при этом избегать дополнительных операций поиска в списке.
При использовании list comprehension для удаления дублей важно учитывать следующие моменты:
- Использование
setдля удаления дубликатов эффективно, но не сохраняет порядок. - Для сохранения порядка элементов следует использовать вспомогательные структуры данных, такие как
set, в сочетании с проверкой в list comprehension. - Если порядок не важен, простой способ с применением
setбудет самым быстрым.
Использование библиотеки pandas для удаления дубликатов
Библиотека pandas предлагает простой и эффективный способ удаления дубликатов в данных с помощью метода drop_duplicates(). Этот метод позволяет работать с DataFrame и Series, удаляя строки с одинаковыми значениями в выбранных столбцах или во всей таблице.
Чтобы удалить дубли в DataFrame, достаточно вызвать метод drop_duplicates(). Например, для удаления дубликатов по всем столбцам можно использовать следующий код:
import pandas as pd
data = pd.DataFrame({
'A': [1, 2, 2, 3, 4],
'B': ['a', 'b', 'b', 'c', 'd']
})
data_cleaned = data.drop_duplicates()
print(data_cleaned)В этом примере метод удаляет строки с одинаковыми значениями в обеих колонках. Чтобы удалить дубликаты только по конкретному столбцу, передайте его имя в параметр subset:
data_cleaned = data.drop_duplicates(subset=['A'])
print(data_cleaned)Параметр keep позволяет настроить, какой из дубликатов сохранить: 'first' (по умолчанию) для сохранения первой строки, 'last' для сохранения последней строки или False для удаления всех дубликатов:
data_cleaned = data.drop_duplicates(keep='last')
print(data_cleaned)Кроме того, метод drop_duplicates() имеет параметр inplace, который позволяет изменить исходный объект, не создавая новый DataFrame. Если задать inplace=True, изменения будут применены непосредственно к исходным данным:
data.drop_duplicates(inplace=True)
print(data)Использование pandas для удаления дубликатов удобно и быстро, особенно когда работаешь с большими объемами данных, и позволяет гибко управлять обработкой избыточной информации.
Удаление дубликатов с учетом пользовательского ключа
Для удаления дубликатов из списка в Python с учетом пользовательского ключа можно использовать функцию sorted() в сочетании с key или воспользоваться стандартными средствами Python, такими как множества и генераторы списков. Главная цель – устранить элементы, которые при применении ключа дают одинаковый результат.
Пример: представим, что у нас есть список словарей, и нужно удалить дубликаты, основываясь на значении определенного поля. В таком случае можно применить следующий подход:
data = [
{'name': 'Alice', 'age': 30},
{'name': 'Bob', 'age': 25},
{'name': 'Alice', 'age': 30},
{'name': 'Charlie', 'age': 25}
]
unique_data = list({v['name']: v for v in data}.values())
Здесь мы используем словарь для того, чтобы автоматически удалять дубликаты по ключу 'name', так как словари не могут содержать одинаковые ключи. Этот подход сохраняет только последние уникальные значения, что важно учитывать при решении задачи.
Еще один вариант – использовать функцию filter() в сочетании с lambda для более гибкой фильтрации:
unique_data = list(filter(lambda x: x['name'] not in seen and not seen.add(x['name']), data))
В этом примере seen – это множество, которое хранит уже встреченные значения. Таким образом, фильтрация удаляет все дубликаты по ключу 'name', но оставляет только первое вхождение каждого уникального элемента.
Если ключ сложный, например, это может быть результат вычисления функции, то можно использовать более универсальный подход с передачей ключа в виде функции:
def key_func(item):
return item['age'] # Пример ключа по возрасту
unique_data = list({key_func(v): v for v in data}.values())
Этот метод позволяет адаптировать код под любые нужды, просто изменив логику функции key_func. Это полезно при более сложных структурах данных, например, когда ключем может быть комбинация нескольких полей.
Таким образом, удаление дубликатов с учетом пользовательского ключа в Python можно реализовать разными способами. Главное – понимать, что ключ определяет, как элементы будут сравниваться и какие из них будут считаться одинаковыми.
Преимущества и недостатки разных методов удаления дубликатов
В Python существует несколько способов удаления дубликатов из списка. Каждый метод имеет свои особенности, которые важно учитывать в зависимости от задач. Рассмотрим наиболее популярные способы.
Использование множества (set)
Простой способ удалить дубликаты – преобразовать список в множество, так как множества в Python не могут содержать повторяющиеся элементы.
- Преимущества: Это самый быстрый метод с точки зрения времени выполнения, так как операции с множествами имеют сложность O(1).
- Недостатки: Порядок элементов не сохраняется. Если важен порядок, этот метод не подойдет.
Использование цикла с проверкой в новом списке

Можно пройтись по каждому элементу исходного списка и добавить его в новый список, если он еще не встречался. Это достигается с помощью оператора not in.
- Преимущества: Метод сохраняет порядок элементов, что может быть критически важным.
- Недостатки: Время работы этого метода – O(n^2), так как для каждого элемента списка нужно проверять, есть ли он в новом списке, что существенно замедляет выполнение для больших объемов данных.
Использование словаря (dict)

Если использовать словарь для удаления дубликатов, можно воспользоваться тем, что ключи в словарях уникальны. Преобразуем список в словарь, а затем вернем ключи в виде списка.
- Преимущества: Как и с множествами, этот метод быстро работает и удаляет дубликаты с малой затратой времени.
- Недостатки: Как и в случае с множествами, порядок элементов может быть нарушен, хотя начиная с Python 3.7, словари сохраняют порядок вставки элементов.
Использование библиотеки Pandas
Для больших наборов данных, когда требуется дополнительная функциональность, можно использовать библиотеку Pandas. Метод drop_duplicates() позволяет эффективно удалять дубликаты.
- Преимущества: Это решение идеально подходит для обработки больших объемов данных, например, в аналитике. Метод позволяет гибко управлять удалением дубликатов по определённым столбцам.
- Недостатки: Этот метод требует установки дополнительной библиотеки, что может быть излишним для небольших проектов. Также он несколько медленнее по сравнению с простыми встроенными решениями.
Использование библиотеки itertools
Для сохранения порядка можно использовать метод itertools.groupby(), который сгруппирует одинаковые элементы подряд и оставит только уникальные.
- Преимущества: Этот метод сохраняет порядок элементов и эффективен для отсортированных списков.
- Недостатки: Требует предварительной сортировки списка, что увеличивает сложность работы до O(n log n).
Использование списка и индексации
Ещё один метод заключается в создании нового списка, в который добавляются только уникальные элементы на основе их индексации. Это может быть полезно в специфических ситуациях.
- Преимущества: Этот метод позволяет гибко настроить проверку на уникальность и работает с любыми типами данных.
- Недостатки: Как и при использовании цикла с проверкой, сложность этого метода может быть высока, особенно при работе с большими списками.
При выборе метода стоит ориентироваться на размер данных и требования к сохранению порядка. Для небольших списков удобно использовать множество, для больших – стоит рассмотреть Pandas. Важно также учитывать, требуется ли сохранять порядок элементов.
Как обрабатывать дубликаты в списке с разными типами данных
В Python список может содержать элементы разных типов, что делает процесс удаления дубликатов более сложным. Основная проблема возникает из-за того, что элементы разных типов не всегда можно напрямую сравнить, как, например, строки и числа. Для эффективного удаления дубликатов важно учитывать, как именно сравниваются элементы различных типов.
Если в списке присутствуют числа и строки, их нельзя просто сравнить с помощью стандартных методов, так как Python не поддерживает прямое сравнение чисел с строками. Поэтому первым шагом будет необходимость стандартизировать типы данных или привести их к одному формату. Например, можно сначала привести все элементы списка к строкам, что упростит удаление дубликатов через преобразование списка в множество.
Для этого можно использовать следующий подход: преобразовать список в множество с помощью функции set(), а затем обратно вернуть в список. Это работает, если элементы списка могут быть приведены к одному типу. Если элементы смешанного типа, например, строки и числа, нужно будет привести их к строкам или использовать кастомные методы сравнения, которые учитывают типы данных. Например:
my_list = [1, "1", 2, 3, "2", 3.0, 4, "3"] my_list = list(set(str(i) for i in my_list))
Когда в списке имеются дубликаты, представленные объектами, которые невозможно привести к одному типу, можно воспользоваться специальными структурами данных, которые позволяют хранить уникальные элементы, как например dict.fromkeys(). Этот метод может быть полезен, если нужно сохранить исходный порядок элементов и гарантировать их уникальность, даже при наличии элементов разных типов:
my_list = [1, "1", 2, "1", 2.0, 3, "3"] my_list = list(dict.fromkeys(map(str, my_list)))
Также возможна ситуация, когда важно сохранять только уникальные элементы, не изменяя их порядок. Для этого можно использовать вспомогательную структуру данных, например, множество, чтобы отслеживать уже встреченные элементы, и проверять их перед добавлением в итоговый список. Это позволит избежать дубликатов, но при этом сохранить порядок появления элементов в списке.
Вот пример такого подхода:
my_list = [1, "1", 2, "1", 3.0, 2] unique_list = [] seen = set() for item in my_list: item_str = str(item) if item_str not in seen: unique_list.append(item) seen.add(item_str)
Таким образом, ключевым моментом в обработке дубликатов в списках с разными типами данных является использование методов приведения типов или кастомных методов сравнения, чтобы обеспечить корректное и эффективное удаление повторяющихся элементов.