Символ неразрывного пробела (Unicode: \u00A0) визуально идентичен обычному пробелу, но ведёт себя иначе. Его присутствие может вызывать неожиданные сбои при парсинге, сравнении строк и работе с регулярными выражениями. В текстах, скопированных с веб-страниц или PDF-файлов, этот символ часто появляется незаметно.
Стандартные методы, такие как str.strip() или str.replace(' ', ''), не удаляют неразрывные пробелы. Чтобы точно избавиться от них, необходимо явно указать ‘\u00A0’ в коде. Например: text.replace('\u00A0', ''). Альтернатива – использовать модуль re с шаблоном r'\u00A0' для замены или удаления вхождений через re.sub().
В случаях, когда требуется очистить строку от всех пробельных символов, включая неразрывные, символы табуляции и перевода строки, стоит применять конструкцию ''.join(text.split()) или регулярное выражение re.sub(r'\s+', '', text). Но при этом важно понимать, что \s охватывает \u00A0 только начиная с Python 3.7, при условии, что строка имеет тип str, а не bytes.
Если очистка текста – часть автоматизированной обработки, рекомендуется включить тесты, проверяющие наличие символов \u00A0, с помощью конструкции '\u00A0' in text. Это гарантирует, что данные не содержат невидимых артефактов, способных повлиять на последующую логику программы.
Как распознать символ неразрывного пробела в строке

Символ неразрывного пробела в Unicode представлен кодом \u00A0. Визуально он неотличим от обычного пробела, но имеет другое значение и поведение при обработке текста. В Python его можно явно обнаружить, сравнив каждый символ строки с соответствующим кодом Unicode.
Для точного распознавания используйте выражение if '\u00A0' in строка. Это вернёт True, если неразрывный пробел присутствует. Чтобы убедиться в наличии таких символов в разных частях строки, применяйте цикл: for i, c in enumerate(строка): if c == '\u00A0': print(f'Неразрывный пробел в позиции {i}').
Также можно применить регулярное выражение: re.search(r'\u00A0', строка). Этот способ полезен при анализе больших объёмов текста и извлечении всех случаев использования символа.
Чем отличается неразрывный пробел от обычного пробела в Python

Неразрывный пробел (non-breaking space, NBSP) – это символ Unicode U+00A0. Визуально он идентичен обычному пробелу, но не допускает переноса строки в текстовых редакторах и веб-браузерах. В Python он ведёт себя иначе в некоторых строковых операциях.
- Метод
str.split()не разделяет строку по неразрывному пробелу, если явно не указать его как разделитель. str.strip()не удаляет NBSP по умолчанию, так как он не входит в список пробельных символов, определяемых функциейisspace().- Функция
ord(' ')(где пробел – NBSP) возвращает160, в отличие от32для обычного пробела. - Проверка через
' ' == ' 'вернётFalse, поскольку это разные символы.
Рекомендуется при обработке текста:
- Использовать
replace('\u00A0', ' ')для нормализации пробелов. - Проверять наличие NBSP в строках через
inили регулярные выражения:re.sub('\u00A0', ' ', text). - Избегать слепого использования
split()иstrip()без предварительной очистки текста от специальных пробелов.
Использование метода replace для удаления неразрывного пробела
Символ неразрывного пробела в Unicode обозначается как \u00A0. В Python его можно удалить из строки с помощью метода replace(), заменив на обычный пробел или пустую строку. Важно использовать именно этот Unicode-символ, так как визуально он неотличим от обычного пробела и не удаляется стандартными методами обработки пробелов.
Пример удаления всех неразрывных пробелов:
text = "Пример\u00A0текста\u00A0с\u00A0неразрывными\u00A0пробелами"
cleaned_text = text.replace('\u00A0', '')
print(cleaned_text)
Если требуется заменить неразрывные пробелы на обычные, а не удалять их, аргумент replace() изменяется следующим образом:
text = "Строка\u00A0с\u00A0неразрывными\u00A0пробелами"
normalized_text = text.replace('\u00A0', ' ')
print(normalized_text)
Метод replace() работает последовательно по всей строке, не требуя регулярных выражений или дополнительных библиотек. Он также применим к строкам, содержащим смешанные типы пробелов. Чтобы убедиться в наличии неразрывных пробелов в исходной строке, рекомендуется использовать ord():
for char in text:
print(ord(char))
Удаление неразрывных пробелов с помощью регулярных выражений
Символ неразрывного пробела имеет код \u00A0 в Unicode. Для его удаления с помощью регулярных выражений используется шаблон r’\u00A0+’, позволяющий находить одну или несколько подряд идущих таких вставок.
Пример кода:
import re
text = "Это\u00A0пример\u00A0текста\u00A0с\u00A0неразрывными\u00A0пробелами"
clean_text = re.sub(r'\u00A0+', ' ', text)
print(clean_text)
Шаблон \u00A0+ эффективен при множественных подряд идущих неразрывных пробелах – все они заменяются на обычный пробел. Чтобы полностью удалить неразрывные пробелы, замените второй аргумент на пустую строку:
clean_text = re.sub(r'\u00A0+', '', text)
Если текст содержит смешанные пробелы, включая обычные и неразрывные, и требуется привести их к одному виду, используйте следующий шаблон:
clean_text = re.sub(r'[ \u00A0]+', ' ', text)
Это гарантирует, что между словами будет только один обычный пробел вне зависимости от исходного типа пробела.
Очистка текста от неразрывных пробелов при чтении из файла
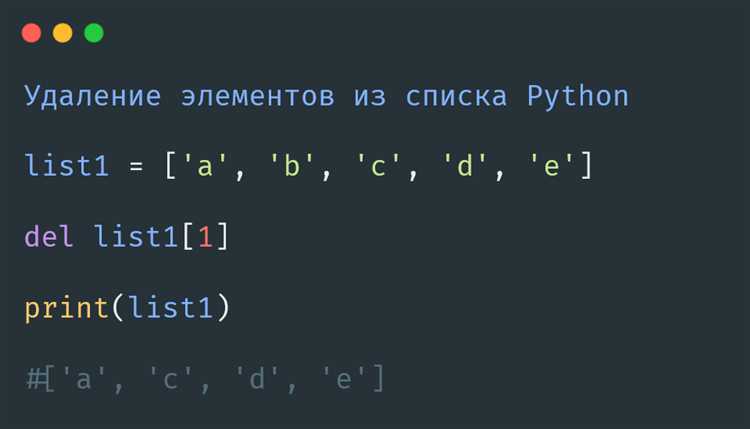
При чтении текстовых данных из файлов неразрывные пробелы (\u00A0) часто встречаются в данных, скопированных из HTML-страниц, PDF-документов или текстов, созданных в Word. Эти символы визуально идентичны обычным пробелам, но могут нарушать работу парсинга, сортировки или анализа.
Для удаления неразрывных пробелов сразу при чтении файла используйте параметр замены в момент обработки строк. Пример:
with open('input.txt', 'r', encoding='utf-8') as f:
lines = [line.replace('\u00A0', ' ') for line in f]
Если необходима полная очистка и объединение строк в один текст, используйте следующий подход:
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read().replace('\u00A0', ' ')
Если требуется удалить неразрывные пробелы полностью, а не заменять их обычными, замените второй аргумент метода replace на пустую строку:
text = text.replace('\u00A0', '')
Для дополнительной защиты от других нестандартных пробельных символов можно использовать регулярные выражения:
import re
with open('input.txt', 'r', encoding='utf-8') as f:
text = re.sub(r'\u00A0', '', f.read())
Оптимизируйте чтение, если обрабатываете большие файлы – замену можно выполнять построчно, избегая загрузки всего файла в память:
clean_lines = []
with open('input.txt', 'r', encoding='utf-8') as f:
for line in f:
clean_lines.append(line.replace('\u00A0', ''))
Результат можно сохранить обратно в файл:
with open('cleaned.txt', 'w', encoding='utf-8') as f:
f.writelines(clean_lines)
Как удалить неразрывные пробелы в списке строк
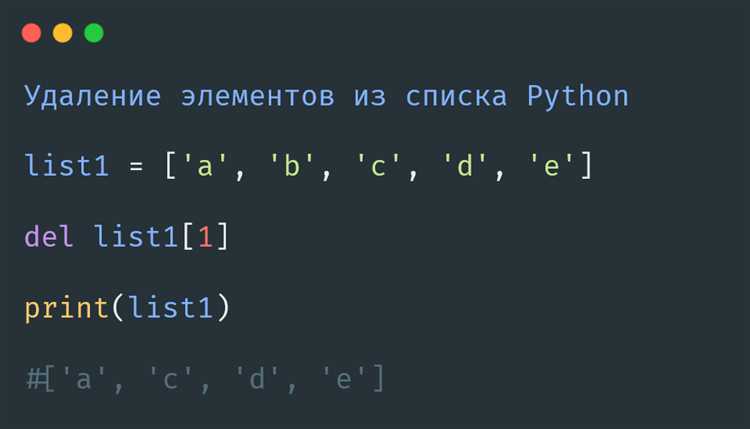
Неразрывной пробел (U+00A0) часто используется в тексте для предотвращения переноса слов. Однако в некоторых случаях его нужно удалить из строк, особенно при обработке данных или подготовке текста для дальнейшего анализа. Для этого в Python можно использовать несколько эффективных способов.
Предположим, у вас есть список строк, в которых встречаются неразрывные пробелы. Чтобы удалить их, воспользуйтесь методом replace(), который заменяет все вхождения символа в строках списка. Например:
strings = ["Текст с\u00A0неразрывным пробелом", "Другой\u00A0текст"]
result = [s.replace('\u00A0', ' ') for s in strings]
print(result)Этот код создаст новый список, в котором все неразрывные пробелы будут заменены на обычные пробелы. Важно заметить, что символ неразрывного пробела представлен как ‘\u00A0’ в Python.
Если требуется полностью удалить неразрывные пробелы, можно заменить их на пустую строку:
result = [s.replace('\u00A0', '') for s in strings]
print(result)Этот метод применим и для работы с большими текстами или данными, содержащими большое количество строк.
Для оптимизации можно также использовать регулярные выражения с модулем re, что позволит избавиться от всех неразрывных пробелов, не трогая другие пробелы. Пример:
import re
strings = ["Текст с\u00A0неразрывным пробелом", "Другой\u00A0текст"]
result = [re.sub(r'\u00A0', '', s) for s in strings]
print(result)Метод re.sub() позволяет более гибко управлять заменой символов, что удобно при сложных текстовых трансформациях.
Таким образом, для удаления неразрывных пробелов в списке строк, можно использовать как простой метод replace(), так и более мощные средства работы с регулярными выражениями, в зависимости от задачи.
Проверка наличия неразрывных пробелов в тексте и их подсчёт

Для поиска неразрывных пробелов в строке можно использовать метод str.count(), который позволяет быстро подсчитать количество вхождений символа в строку. Для этого достаточно передать нужный символ в качестве аргумента.
text = "Это пример с неразрывным пробелом: abc\xa0def"
count = text.count('\xa0')
print(count) # Выведет: 1В случае, если нужно проверить, присутствуют ли неразрывные пробелы в тексте, можно воспользоваться условием:
if '\xa0' in text:
print("Неразрывные пробелы найдены")
else:
print("Неразрывных пробелов нет")Другим полезным методом является использование регулярных выражений, который позволяет более гибко подходить к анализу текста. Например, с помощью модуля re можно найти все вхождения неразрывных пробелов:
import re
matches = re.findall(r'\xa0', text)
print(len(matches)) # Выведет количество неразрывных пробеловЕсли же необходимо найти и подсчитать не только неразрывные пробелы, но и другие скрытые символы, такие как табуляции или пробелы, регулярные выражения предоставляют удобный механизм для поиска любых белых символов:
whitespace_count = len(re.findall(r'\s', text))
print(whitespace_count)Рекомендации по проверке наличия неразрывных пробелов:
- Используйте метод
count()для быстрого подсчёта неразрывных пробелов в небольших строках. - Для более сложных случаев с анализом текста используйте регулярные выражения с модулем
re. - Регулярные выражения могут быть полезны для поиска сразу нескольких типов пробелов или других скрытых символов.
Таким образом, можно эффективно решать задачу поиска и подсчёта неразрывных пробелов в строках с использованием стандартных инструментов Python.
Вопрос-ответ:
Что такое символ неразрывного пробела и зачем его удалять в Python?
Символ неразрывного пробела (также называемый «неразрывным пробелом» или «неразрывным пробелом Unicode») представляет собой пробел, который не позволяет разрывать текст на этом месте при переносе строк. В Python такой пробел может использоваться, например, для форматирования текста, но иногда его нужно удалить, чтобы избежать нежелательных пробелов в данных, которые могут повлиять на обработку строк или их вывод.
Как можно удалить неразрывный пробел из строки в Python?
Для удаления символа неразрывного пробела из строки в Python можно использовать метод `replace()`. Например, чтобы удалить все неразрывные пробелы в строке, можно выполнить следующее: `text.replace(‘\u00A0’, »)`. В этом примере `’\u00A0’` — это Unicode-символ для неразрывного пробела, а метод `replace()` заменяет его на пустую строку, эффективно удаляя все такие символы.
Есть ли отличия между удалением обычного пробела и неразрывного пробела в Python?
Да, существует различие между обычным пробелом и неразрывным пробелом в Python. Обычный пробел имеет код Unicode `\u0020`, и его можно удалить с помощью метода `replace(‘ ‘, »)`. В отличие от этого, неразрывный пробел имеет код `\u00A0` и требует использования этого конкретного Unicode-символа в методе `replace()` для корректного удаления. То есть, если в строке присутствуют оба типа пробела, то для их удаления нужно отдельно обработать каждый.
Как узнать, если в строке есть неразрывный пробел в Python?
Для проверки наличия неразрывного пробела в строке можно использовать оператор `in`. Например, чтобы проверить, есть ли в строке неразрывный пробел, можно выполнить следующее: `’ ‘ in text`. Это вернет `True`, если неразрывный пробел присутствует в строке. Можно также использовать метод `find()`, который возвращает индекс первого вхождения символа, или `count()`, чтобы посчитать количество таких символов в строке.