В Python список представляет собой коллекцию объектов, которые могут быть изменены. Одной из часто выполняемых операций является удаление элемента из списка по его значению. Эта задача может быть решена несколькими способами, в зависимости от требований к результату и особенностей работы с данным типом данных. Рассмотрим основные методы, которые позволяют эффективно удалять элементы по значению в списке.
Если необходимо удалить первое вхождение элемента, то одним из самых простых решений будет использование метода remove(). Этот метод ищет в списке указанное значение и удаляет его, при этом если элемент встречается несколько раз, будет удалено только первое его вхождение. В случае, если значение не найдено, возникнет исключение ValueError, что важно учитывать при разработке.
Для более гибкого контроля над удалением, например, когда нужно учесть, что элемент может встречаться несколько раз, можно применить цикл. В таких случаях можно пройти по списку и удалить все вхождения элемента, что обеспечит более точный результат. Такой подход также полезен, если важно, чтобы программа не выбрасывала исключение в случае отсутствия элемента.
Однако стоит помнить, что операции удаления могут быть затратными по времени, особенно при работе с большими списками. Важно учитывать это при выборе подхода и, если возможно, ограничивать количество операций удаления для повышения производительности программы.
Как удалить первый найденный элемент из списка по значению?
Чтобы удалить первый элемент из списка по значению, используется метод remove(). Этот метод ищет первый элемент, равный переданному значению, и удаляет его. Если элемент не найден, возникает исключение ValueError.
Пример использования метода remove():
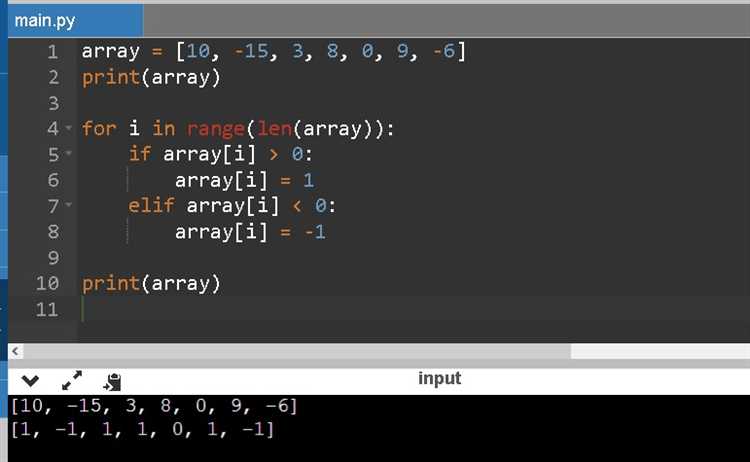
my_list = [1, 2, 3, 4, 2]
my_list.remove(2)
print(my_list)Результат:
[1, 3, 4, 2]Как видно, метод удаляет только первый встреченный элемент, который равен 2. Остальные такие же элементы остаются в списке.
Если элемент не найден в списке, код завершится с ошибкой. Чтобы избежать этого, можно использовать конструкцию try-except:
try:
my_list.remove(5)
except ValueError:
print("Элемент не найден")Этот способ позволит безопасно попытаться удалить элемент, не вызвав ошибки, если элемент отсутствует в списке.
Метод remove() и его особенности при удалении элементов
Метод remove() используется для удаления первого вхождения указанного элемента в список. Он изменяет сам список и не возвращает значения. Рассмотрим его основные особенности:
- Удаление первого совпадения: Метод удаляет только первое вхождение указанного значения. Если элемент встречается несколько раз, необходимо вызвать
remove()несколько раз или использовать другие методы. - Отсутствие элемента: Если элемент не найден в списке, метод вызовет исключение
ValueError. Это важно учитывать, особенно если вы не уверены, что элемент присутствует в списке. - Неизменяемость на месте: Метод изменяет оригинальный список, то есть он работает «по ссылке» и не создает новый список. Это может быть важным при работе с большими данными.
Пример использования:
my_list = [1, 2, 3, 4, 3, 5]
my_list.remove(3)
Метод удаляет только первое вхождение значения 3, а не все элементы с таким значением.
- Использование метода в цикле: Если нужно удалить все вхождения элемента, можно использовать цикл:
my_list = [1, 2, 3, 3, 4, 3, 5]
while 3 in my_list:
my_list.remove(3)
Этот подход позволяет избавиться от всех вхождений элемента, но стоит помнить, что каждый вызов remove() проходит по всему списку, что может замедлить работу при больших объемах данных.
Важные моменты:
- Метод
remove()не подходит для удаления элементов по индексу. Для этой цели используется методpop(). - Если важно избежать ошибки при отсутствии элемента, можно предварительно проверить наличие элемента с помощью оператора
in.
Пример проверки:
if 3 in my_list:
my_list.remove(3)
else:
print("Элемент не найден.")
Таким образом, метод remove() удобен для удаления первого вхождения элемента из списка, но требует внимательности при обработке исключений и использовании в цикле.
Удаление всех элементов с одинаковым значением из списка

Пример с использованием цикла:
my_list = [1, 2, 3, 4, 2, 5, 2]
value_to_remove = 2
while value_to_remove in my_list:
my_list.remove(value_to_remove)
print(my_list) # [1, 3, 4, 5]
Этот способ подходит для небольших списков, но он не самый эффективный, так как каждый вызов remove() проходит по списку в поисках элемента. В случае больших списков эффективность может заметно снизиться.
Более оптимальным решением будет использование спискового включения, которое позволяет пройти по списку и создать новый, исключив все элементы с заданным значением:
my_list = [1, 2, 3, 4, 2, 5, 2]
value_to_remove = 2
my_list = [x for x in my_list if x != value_to_remove]
print(my_list) # [1, 3, 4, 5]
Этот метод эффективнее, так как не изменяет исходный список в процессе его обхода, а создает новый, исключая все элементы с заданным значением. Для очень больших списков этот способ будет работать быстрее, так как он минимизирует количество операций по изменению списка.
В случае, если необходимо удалить все элементы, равные значению, а затем сохранить измененный список, можно использовать вариант с фильтрацией с помощью filter(). Однако такой метод требует преобразования результата в список, так как filter() возвращает итератор.
my_list = [1, 2, 3, 4, 2, 5, 2]
value_to_remove = 2
my_list = list(filter(lambda x: x != value_to_remove, my_list))
print(my_list) # [1, 3, 4, 5]
В случае, если необходимо удалить все вхождения элементов, встречающихся несколько раз, стоит также рассмотреть использование коллекций, таких как Counter, для подсчета вхождений элементов и фильтрации по их количеству. Это может быть полезно в специфичных случаях, где нужно удалить элементы, которые появляются больше одного раза.
Все эти способы могут быть адаптированы в зависимости от особенностей задачи, но важно помнить, что производительность и читаемость кода играют ключевую роль в выборе метода.
Как обработать ошибку, если элемент не найден в списке?
Когда вы пытаетесь удалить элемент из списка в Python по его значению, может возникнуть ситуация, когда элемент не присутствует в списке. Это приведет к ошибке типа ValueError при использовании метода remove(). Чтобы избежать этой ошибки, можно использовать несколько подходов для проверки наличия элемента перед его удалением.
- Использование условной проверки: Перед удалением элемента, можно проверить, существует ли он в списке, с помощью оператора
in.
Пример:
my_list = [1, 2, 3, 4, 5]
if 3 in my_list:
my_list.remove(3)
else:
print("Элемент не найден в списке.")
Этот подход предотвращает возникновение ошибки, так как элемент удаляется только в случае его наличия в списке.
- Обработка исключений: Вместо явной проверки наличия элемента можно использовать обработку исключений с помощью блока
try-except.
Пример:
try:
my_list.remove(3)
except ValueError:
print("Элемент не найден в списке.")
Этот метод полезен, если вы хотите обработать несколько операций удаления элементов из списка и не хотите предварительно проверять их наличие. Если элемент не найден, будет выведено сообщение об ошибке.
- Использование метода
discard()в set: Если работа с множествами подходит для вашей задачи, можно использовать методdiscard(), который не вызывает ошибку, если элемента нет в множестве.
Пример:
my_set = {1, 2, 3, 4, 5}
my_set.discard(3) # Элемент будет удален, если он существует, ошибки не будет.
Метод discard() является безопасным, так как он не вызывает исключений, если элемент отсутствует в множестве.
Каждый из этих подходов имеет свои особенности. Использование in идеально подходит для явной проверки, в то время как блок try-except позволяет гибко обрабатывать исключения и продолжать выполнение программы без остановки. Важно выбирать метод в зависимости от ситуации и требований к обработке ошибок в вашем коде.
Разница между методами remove() и pop() при удалении по значению
Методы remove() и pop() используются для удаления элементов из списка в Python, но каждый из них имеет свои особенности в контексте удаления по значению.
Метод remove() удаляет первый встреченный элемент с указанным значением. Если элемент не найден, выбрасывается исключение ValueError. Например:
my_list = [1, 2, 3, 4, 5]
my_list.remove(3)
# Результат: [1, 2, 4, 5]В отличие от этого, метод pop() удаляет элемент по индексу и возвращает его. При передаче индекса, метод удаляет элемент по этому индексу. Если индекс не указан, метод удаляет последний элемент списка. Однако, pop() не позволяет удалять элемент по значению напрямую. Например:
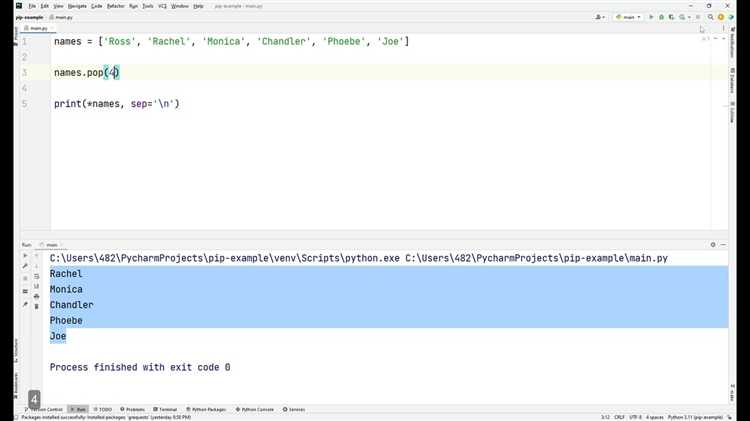
my_list = [1, 2, 3, 4, 5]
my_list.pop(2)
# Результат: 3
# Список после удаления: [1, 2, 4, 5]Основные различия между методами:
- remove() удаляет элемент по значению, а pop() – по индексу.
- Метод remove() вызывает ошибку, если элемент не найден, в то время как pop() вызывает ошибку, если индекс вне диапазона.
- pop() возвращает удалённый элемент, а remove() – нет.
Для удаления по значению используйте remove(). Если вам нужно работать с индексацией, а также получить удалённый элемент, используйте pop().
Удаление элемента по значению в списке с учетом индекса
В Python для удаления элемента из списка по значению можно воспользоваться методом remove(). Однако в случае, если элемент встречается несколько раз, remove() удаляет только первое вхождение. Если необходимо удалить все вхождения элемента, нужно использовать цикл или подход с фильтрацией списка. Но важно помнить, что метод remove() не возвращает индекс удаленного элемента, и его использование не учитывает, если индекс этого элемента критичен.
Для того чтобы удалить элемент с учетом его индекса, можно сначала найти индекс элемента с помощью метода index(), а затем удалить его с помощью pop(). Этот подход полезен, если элемент встречается только один раз, и важно знать точное место его расположения.
Пример:
lst = [10, 20, 30, 40, 20] index = lst.index(20) # находим индекс первого вхождения lst.pop(index) # удаляем элемент по найденному индексу print(lst) # результат: [10, 30, 40, 20]
Если элемент встречается несколько раз и необходимо удалить его по индексу, лучше воспользоваться циклом или функцией enumerate() для обхода списка и учета всех индексов, где встречается нужное значение.
Пример удаления всех вхождений элемента с учетом их индексов:
lst = [10, 20, 30, 40, 20] indexes_to_remove = [i for i, value in enumerate(lst) if value == 20] for index in reversed(indexes_to_remove): lst.pop(index) print(lst) # результат: [10, 30, 40]
Этот метод помогает безопасно и эффективно удалить все вхождения элемента, не нарушив порядок оставшихся элементов. Сортировка индексов в обратном порядке необходима, чтобы избежать смещения индексов после удаления элементов.
Использование list comprehension для удаления элементов по значению
List comprehension позволяет создать новый список, исключив из него элементы, соответствующие определенному значению. Это решение часто используется для удаления элементов по значению, поскольку оно компактно и эффективно.
Пример кода, который удаляет все вхождения определённого значения из списка:
my_list = [1, 2, 3, 4, 2, 5, 2]
value_to_remove = 2
my_list = [x for x in my_list if x != value_to_remove]
В этом примере создается новый список, в который включаются только те элементы исходного списка, которые не равны значению 2.
Стоит помнить, что этот метод не изменяет оригинальный список, а создает новый. Если нужно удалить элементы на месте, можно использовать конструкцию с del, но в случае с list comprehension вы получаете новый список без лишних изменений в исходных данных.
Для удаления нескольких значений, можно использовать оператор in:
values_to_remove = {2, 3}
my_list = [x for x in my_list if x not in values_to_remove]
Этот подход более гибкий, поскольку позволяет удалять сразу несколько значений за одну операцию.
Если производительность критична, стоит отметить, что использование list comprehension может быть менее эффективным по сравнению с методами, изменяющими список на месте, поскольку каждый раз создается новый объект списка. Однако для небольших списков и одноразовых операций это не является проблемой.
Удаление элементов по значению в списке с дублирующимися значениями

Когда необходимо удалить элемент из списка с дублирующимися значениями, важно понимать, как Python обрабатывает такие случаи. Метод remove() удаляет только первый найденный элемент, который соответствует указанному значению. Для списков с несколькими одинаковыми значениями это может быть неэффективно, если требуется удалить все такие элементы.
Если нужно удалить все вхождения элемента, можно использовать цикл. Например, можно применить конструкцию while для повторного вызова remove(), пока элемент присутствует в списке:
my_list = [1, 2, 3, 2, 4, 2]
while 2 in my_list:
my_list.remove(2)
Этот метод удаляет все элементы со значением 2 из списка. Однако стоит отметить, что в процессе удаления изменяется длина списка, что делает такой подход эффективным только для небольших коллекций данных.
Если важно не изменять оригинальный список, можно использовать генератор списков для создания нового, исключающего все элементы с заданным значением:
my_list = [1, 2, 3, 2, 4, 2]
new_list = [x for x in my_list if x != 2]
Этот способ позволяет сохранить исходный список и получить новый, в котором отсутствуют все вхождения удаляемого элемента.
Для более сложных случаев, когда необходимо удалять элементы по значению, но с условием (например, если элемент встречается не более определенного числа раз), можно комбинировать методы count() и remove(). Пример:
my_list = [1, 2, 3, 2, 4, 2]
count = my_list.count(2)
for _ in range(count):
my_list.remove(2)
Этот подход дает точный контроль над количеством удалений. Однако важно помнить, что удаление элементов из списка может быть дорогой операцией, особенно для больших списков. Поэтому, если удаление элементов по значению происходит часто, стоит рассмотреть использование других структур данных, например, множества или словаря.
Вопрос-ответ: