Удалить последнюю строку из текстового файла в Python можно несколькими способами, и выбор подхода зависит от размера файла и требований к производительности. Если файл небольшой, оптимально считать его в память целиком, удалить последнюю строку и перезаписать содержимое. При работе с крупными файлами подобный метод может привести к избыточному потреблению оперативной памяти.
Для эффективной обработки больших файлов используется подход с построчным чтением и временным файлом. Модуль tempfile позволяет создавать временные файлы, которые можно использовать для записи всех строк, кроме последней. После завершения записи временный файл заменяет исходный. Этот способ особенно полезен при работе с логами, экспортами данных и другими файлами большого объёма.
Важно учитывать кодировку файлов и обрабатывать возможные ошибки чтения и записи, особенно если строки содержат специальные символы или файл открыт в режиме, отличном от текстового. Также имеет смысл использовать context manager с конструкцией with для автоматического закрытия файлов и минимизации риска утечек ресурсов.
Как считать все строки файла в список
Метод 1: Использование функции readlines()
Метод readlines() позволяет считать весь файл построчно и вернуть список, где каждая строка – это отдельный элемент списка. Это один из самых простых и популярных способов:
with open('file.txt', 'r') as file:
lines = file.readlines()Этот способ полезен, если вам нужно работать с большими файлами, так как позволяет считать все строки сразу, но с возможностью обработки данных поэтапно, не загружая их в память одновременно.
Метод 2: Использование генератора с циклом for
Если вам необходимо более гибко работать с файлами или дополнительно обрабатывать строки, можно использовать цикл for:
with open('file.txt', 'r') as file:
lines = [line.strip() for line in file]Этот способ позволяет сразу же обрабатывать строки (например, удалять лишние пробелы с помощью strip()), перед тем как добавить их в список.
Метод 3: Чтение файла в память с использованием метода read()
Если размер файла не слишком велик, и вы хотите работать с его содержимым как с одной строкой, можно использовать метод read(), который считывает весь файл за один раз. Затем можно разделить текст на строки с помощью метода splitlines():
with open('file.txt', 'r') as file:
content = file.read()
lines = content.splitlines()Этот метод позволяет сохранить исходные разделители строк и идеально подходит для обработки файлов небольшого размера.
Рекомендации по выбору метода:
Если файл очень большой, стоит избегать использования read(), так как это может привести к излишней нагрузке на память. В таких случаях лучше использовать readlines() или цикл for, так как они не загружают весь файл в память одновременно.
Как определить количество строк в файле
Самый базовый способ – это открыть файл и пройти по нему построчно, считая количество строк. Этот метод универсален и подходит для файлов любого размера. Пример кода:
with open('file.txt', 'r') as f:
lines = f.readlines()
print(len(lines))Этот метод будет загружать весь файл в память, что может быть проблемой для очень больших файлов. В таких случаях эффективнее использовать вариант, не загружая весь файл в память. Например, можно обходить файл построчно, увеличивая счётчик строк:
count = 0
with open('file.txt', 'r') as f:
for line in f:
count += 1
print(count)Этот метод подходит для больших файлов, так как строки считываются по одной, и память используется эффективно. Однако этот способ не идеален, если нужно получить количество строк очень быстро, так как чтение файла происходит в реальном времени.
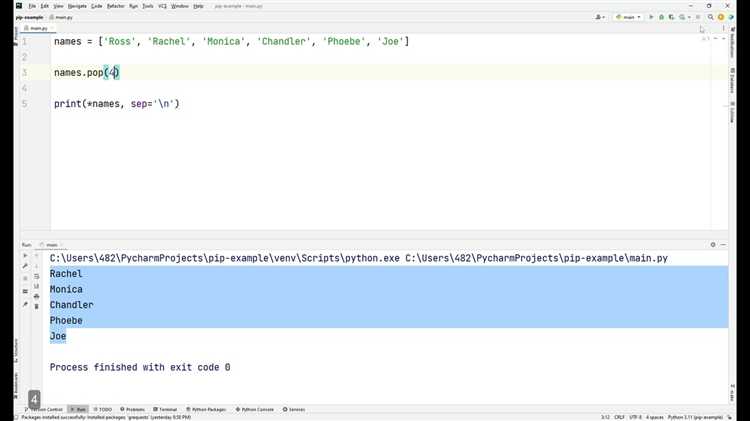
Как удалить последнюю строку из списка строк
Чтобы удалить последнюю строку из списка строк в Python, достаточно воспользоваться методом pop(). Этот метод удаляет элемент по указанному индексу и возвращает его. Если индекс не указан, pop() удаляет последний элемент списка, что идеально подходит для этой задачи.
Пример использования метода:
lines = ["первая строка", "вторая строка", "третья строка"]
lines.pop()
print(lines) # Результат: ['первая строка', 'вторая строка']
Метод pop() изменяет оригинальный список, удаляя последний элемент. Важно отметить, что он возвращает удалённый элемент, что может быть полезно, если нужно использовать его в дальнейшем.
Если список пуст, попытка вызвать pop() без индекса приведёт к ошибке. Для безопасного удаления последней строки следует сначала проверить, что список не пуст:
if lines:
lines.pop()
else:
print("Список пуст.")
Для других вариантов удаления последней строки, например, если нужно просто обрезать список, можно использовать срезы:
lines = lines[:-1]
print(lines) # Результат: ['первая строка', 'вторая строка']
Метод среза не изменяет оригинальный список, а возвращает новый, обрезанный список. Это полезно, если нужно сохранить оригинальный список без изменений.
Как перезаписать файл без последней строки
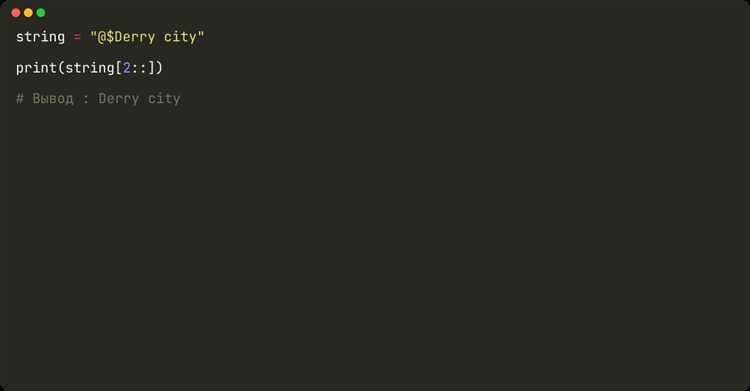
Для того чтобы перезаписать файл без последней строки, можно воспользоваться стандартными средствами Python. В первую очередь, важно понимать, что файл нужно открыть для чтения и записи, прочитать все строки, кроме последней, а затем снова записать их в файл. Рассмотрим этот процесс более подробно.
Первым шагом будет открытие файла и считывание его содержимого. С помощью метода readlines() можно получить все строки файла в виде списка. После этого можно удалить последнюю строку, используя срез списка.
Далее, необходимо перезаписать файл, открыв его в режиме записи. Для этого достаточно использовать метод writelines(), который позволяет записать все строки, кроме последней.
Пример реализации:
with open('file.txt', 'r') as file:
lines = file.readlines()
# Удаляем последнюю строку
lines = lines[:-1]
with open('file.txt', 'w') as file:
file.writelines(lines)Этот код открывает файл для чтения, считывает все строки в список, удаляет последнюю строку и записывает оставшиеся строки обратно в файл. Такой способ позволяет эффективно управлять содержимым файла, исключая ненужную строку.
Обратите внимание, что при таком подходе данные перезаписываются в тот же файл, что может быть неудобно, если нужно сохранить оригинальный файл. В этом случае можно записать изменённые данные в новый файл, указав другое имя при открытии файла для записи.
Также стоит учитывать, что если файл очень большой, то использование readlines() может потребовать значительных ресурсов памяти. В таких случаях можно обрабатывать файл построчно, сохраняя в памяти только те строки, которые необходимы.
Как работать с большими файлами без чтения в память
Основным инструментом для этого является использование встроенной функции `open()` в сочетании с итерацией по строкам файла. Это позволяет обрабатывать данные по частям, не загружая весь файл в память.
Пример простого чтения файла построчно:
with open('large_file.txt', 'r') as f:
for line in f:
process(line)В этом примере файл открывается в режиме чтения, и строки считываются по мере итерации, что исключает необходимость хранить весь файл в памяти. Однако этот метод не подходит, если требуется изменение структуры файла, например, удаление строк.
Для удаления последней строки из большого файла без загрузки всего содержимого можно использовать подход с временным файлом. Алгоритм заключается в следующем:
- Открываем исходный файл для чтения и новый файл для записи.
- Читаем файл построчно, записывая все строки в новый файл, кроме последней.
- Удаляем или заменяем старый файл, переименовывая новый файл.
Пример кода:
import os
def remove_last_line(file_path):
with open(file_path, 'r') as infile:
lines = infile.readlines()
with open(file_path, 'w') as outfile:
outfile.writelines(lines[:-1]) # записываем все строки, кроме последнейЭтот способ достаточно эффективен, если файл не слишком велик. Однако, если файл действительно большой, необходимо избежать загрузки всех строк в память одновременно. В таком случае можно использовать итерацию по файлу и исключить последнюю строку во время записи в новый файл:
def remove_last_line_large_file(file_path):
with open(file_path, 'r') as infile:
lines = []
for line in infile:
if len(lines) > 0:
lines.pop(0) # удаляем первую строку, если она есть
lines.append(line)
with open(file_path, 'w') as outfile:
outfile.writelines(lines[:-1]) # сохраняем все строки, кроме последнейЭтот метод позволяет избежать использования большого объема памяти, обрабатывая только ограниченное количество строк в памяти в любой момент времени. Для очень больших файлов важно сбалансировать количество строк, хранимых в памяти, чтобы минимизировать нагрузку на систему.
В случае необходимости многократного удаления строк, можно реализовать решение с двумя указателями или использовать подход с записью в новый файл по частям, что существенно снижает потребление памяти и позволяет работать с файлами гигантских размеров.
Как использовать временный файл для изменения содержимого
В Python для работы с временными файлами можно использовать модуль tempfile, который позволяет создать временный файл с автоматически выбранным уникальным именем. Этот файл удаляется при закрытии программы или при завершении работы с ним. Это идеальный способ для временных изменений в процессе работы с большими файлами.
Пример использования временного файла для удаления последней строки из файла:
- Открываем исходный файл для чтения.
- Создаем временный файл для записи.
- Переносим все строки из исходного файла в временный файл, за исключением последней.
- Удаляем или переименовываем исходный файл.
- Переименовываем временный файл в имя исходного файла.
Пример кода:
import tempfile import shutil def remove_last_line(file_path): with open(file_path, 'r') as file: lines = file.readlines() # Создаем временный файл with tempfile.NamedTemporaryFile(delete=False) as temp_file: # Записываем все строки, кроме последней temp_file.writelines(lines[:-1]) # Заменяем оригинальный файл временным shutil.move(temp_file.name, file_path)
Этот метод позволяет избежать ненужного переписывания всех данных сразу в оригинальный файл, минимизируя риски повреждения содержимого при ошибке. Важно помнить, что если файл слишком велик, этот метод может потребовать значительных затрат времени и памяти.
Для обеспечения более надежной работы можно использовать дополнительные механизмы для создания резервных копий перед изменениями, чтобы в случае ошибки всегда можно было восстановить исходное состояние.
Как избежать ошибок при работе с путями и кодировками
Ошибки при работе с путями и кодировками могут серьезно затруднить выполнение программ на Python. Важно следить за несколькими ключевыми моментами, чтобы избежать распространенных проблем.
1. Правильная обработка путей
Когда работаешь с путями в операционных системах, следует учитывать особенности каждой системы. В Windows используется обратный слэш (\), а в Unix-подобных системах (Linux, macOS) – прямой слэш (/). Использование неподходящего символа приведет к ошибке.
- Используйте модуль
os.pathилиpathlib, которые абстрагируют различия между системами. - Для создания универсальных путей используйте
pathlib.PurePathилиos.path.join(). - В строках путей для Windows используйте двойной обратный слэш (например,
"C:\\Users\\file.txt") или сырой строковый литерал (например,r"C:\Users\file.txt").
2. Работа с кодировками
Ошибка в кодировке может привести к неправильному отображению или сохранению текста. Важно всегда явно указывать кодировку при открытии файла.
- Для файлов с текстом используйте кодировку UTF-8, так как она универсальна для большинства языков и платформ.
- При открытии файлов в Python всегда указывайте параметр
encoding="utf-8"в функцииopen(). - Для обработки несовместимых кодировок используйте параметр
errors="ignore"илиerrors="replace", чтобы избежать ошибок при чтении файлов с поврежденной кодировкой.
3. Проверка существования файла
Перед попыткой открыть файл, убедитесь, что он существует, чтобы избежать ошибок FileNotFoundError.
- Для проверки существования файла используйте
os.path.exists(path)илиpathlib.Path(path).exists(). - Если файл должен быть создан, используйте параметр
mode="w"для открытия файла на запись, что автоматически создаст файл, если его нет.
4. Обработка ошибок и исключений
При работе с путями и кодировками важно предусматривать возможные исключения и корректно их обрабатывать.
- Используйте конструкцию
try-exceptдля обработки исключений, таких какFileNotFoundErrorилиUnicodeDecodeError. - Логирование ошибок с помощью модуля
loggingпоможет выявить источник проблем и избежать потери данных.
5. Обработка файлов с разными кодировками
Если вы работаете с файлами, имеющими разные кодировки, лучше использовать библиотеку chardet для определения кодировки файла.
- Библиотека
chardet.detect()может помочь автоматически определить кодировку, если вы не уверены, какая кодировка используется в файле.
Как обрабатывать случай пустого файла

Шаг 1. Проверка на пустоту
Первый шаг – это проверка размера файла. Можно использовать функцию os.stat(), чтобы получить информацию о файле и проверить его размер. Если размер равен 0, файл пуст, и можно обработать эту ситуацию специальным образом.
Шаг 3. Логирование пустых файлов
Чтобы не пропустить ситуацию с пустыми файлами, полезно вести логирование. В случае пустого файла можно записать в лог соответствующую информацию, чтобы позднее иметь возможность проанализировать это поведение.
Шаг 4. Использование контекстных менеджеров
Для корректного закрытия файла после выполнения операций рекомендуется использовать контекстный менеджер with. Это гарантирует, что файл будет закрыт даже в случае ошибки, что особенно важно при работе с пустыми файлами, так как они могут вести себя непредсказуемо при неправильном управлении ресурсами.
Вот пример кода для проверки пустого файла и корректного его закрытия:
import os
filename = "file.txt"
try:
if os.stat(filename).st_size == 0:
print("Файл пуст.")
else:
with open(filename, 'r') as file:
lines = file.readlines()
# Логика обработки файла
except FileNotFoundError:
print("Файл не найден.")
except Exception as e:
print(f"Произошла ошибка: {e}")