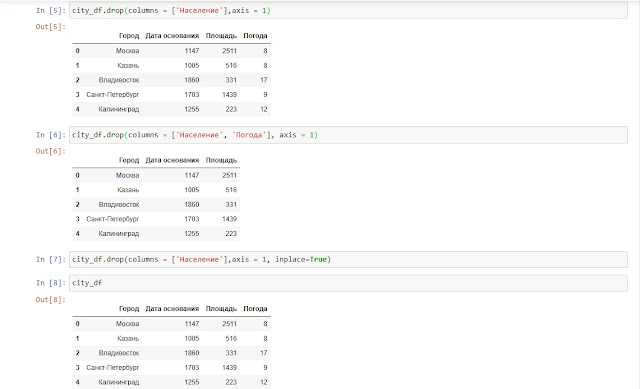
Удаление ненужных столбцов в Pandas DataFrame – ключевая операция при подготовке данных. Это позволяет сократить объем памяти, улучшить читаемость структуры и ускорить выполнение анализа. Метод drop() используется чаще всего, так как поддерживает удаление по названию, по оси и может применяться как с копированием, так и с изменением на месте.
Например, df.drop('column_name', axis=1) удалит столбец без изменения исходного DataFrame, а передача inplace=True изменит его напрямую. Для удаления нескольких столбцов можно использовать список названий: df.drop(['col1', 'col2'], axis=1).
Важно учитывать, что попытка удаления несуществующего столбца вызовет исключение. Чтобы этого избежать, укажите параметр errors=’ignore’. Это особенно полезно при работе с неустойчивыми источниками данных или динамически формируемыми схемами.
Также возможно удаление столбцов по позиции с помощью df.drop(df.columns[[индексы]], axis=1). Такой подход эффективен, когда названия столбцов неизвестны заранее, но порядок их следования фиксирован.
Удаление одного столбца с помощью метода drop()
Метод drop() в pandas позволяет эффективно удалить один столбец по его имени. Для удаления необходимо явно указать ось, по которой производится операция – axis=1, иначе произойдёт удаление строки.
- Чтобы удалить столбец
'Возраст'из DataFramedf, используйте:df.drop('Возраст', axis=1). - По умолчанию
drop()возвращает новый DataFrame. Чтобы изменить существующий, укажитеinplace=True. - Если столбец отсутствует, метод вызовет
KeyError. Для подавления ошибки используйтеerrors='ignore'.
Рекомендуется явно указывать параметры метода:
df.drop(labels='Возраст', axis=1, inplace=True, errors='ignore')labels– имя удаляемого столбцаaxis=1– указание, что удаляется столбец, а не строкаinplace=True– изменения происходят в исходном DataFrameerrors='ignore'– безопасное выполнение без исключений при отсутствии столбца
Для работы с несколькими DataFrame важно помнить, что drop() не изменяет объект по умолчанию. Изменения необходимо либо присвоить новой переменной, либо использовать inplace=True.
Удаление нескольких столбцов одновременно
Для удаления нескольких столбцов из DataFrame используйте метод drop() с передачей списка названий в параметр columns. Это позволяет избежать повторных вызовов функции и повышает читаемость кода:
df.drop(columns=['столбец1', 'столбец2'])
Если необходимо удалить столбцы по индексам, а не по именам, примените df.drop(df.columns[[индекс1, индекс2]], axis=1). Это особенно полезно при работе с анонимными наборами данных или после чтения файлов без заголовков.
Для модификации текущего DataFrame без создания копии добавьте параметр inplace=True. Это освобождает память при работе с большими объемами данных:
df.drop(columns=['A', 'B'], inplace=True)
Проверку наличия столбцов перед удалением рекомендуется выполнять с помощью set(df.columns) & set(список_для_удаления), чтобы избежать ошибок KeyError.
Удаление столбцов по условию, например всех, содержащих пропущенные значения, реализуется через фильтрацию списка имен:
df.drop(columns=df.columns[df.isnull().any()])
При работе с временными или дублирующимися столбцами используйте маски на основе регулярных выражений или методов str.contains() и duplicated() для генерации списка на удаление.
Удаление столбца по индексу, а не по имени
Для удаления столбца по его позиции в DataFrame используйте метод df.drop() с указанием индекса столбца через df.columns. Например, чтобы удалить первый столбец:
df.drop(df.columns[0], axis=1, inplace=True)
Индекс может быть вычислен динамически. Чтобы удалить последний столбец:
df.drop(df.columns[-1], axis=1, inplace=True)
Если требуется удалить несколько столбцов по индексам, используйте список:
df.drop(df.columns[[1, 3, 5]], axis=1, inplace=True)
При использовании inplace=True изменения применяются к исходному DataFrame. Если параметр опустить, метод вернёт копию с удалёнными столбцами.
Важно: прямой доступ через df.columns[индекс] безопасен только при стабильном порядке столбцов. При изменениях структуры используйте предварительную проверку длины df.columns, чтобы избежать ошибок IndexError.
Удаление столбца без создания копии DataFrame
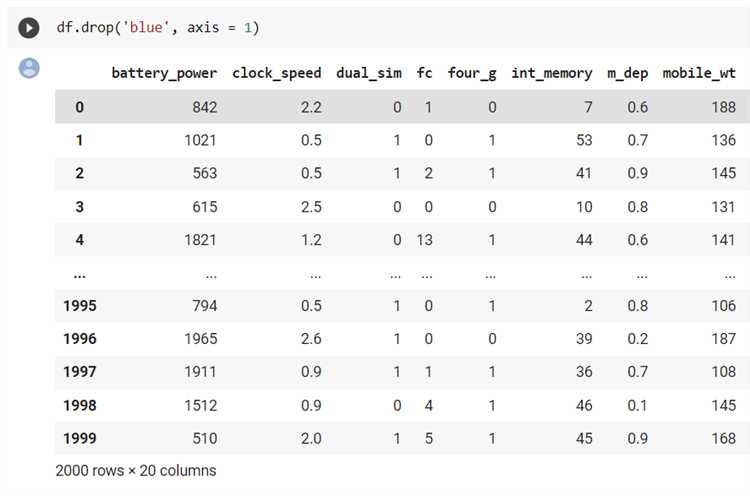
Чтобы удалить столбец из DataFrame без создания его копии, необходимо использовать параметр inplace=True в методе drop(). Это гарантирует, что операция будет выполнена над исходным объектом, а не над его копией.
Пример: df.drop('column_name', axis=1, inplace=True). Здесь axis=1 указывает на удаление по столбцам, а inplace=True отключает возврат нового DataFrame.
Важно: после выполнения такой операции исходный DataFrame модифицируется. Это следует учитывать при работе с данными, которые могут использоваться в других частях кода. При необходимости предварительной проверки – используйте метод без inplace, а затем применяйте его при полной уверенности в корректности удаления.
Также следует избегать методов, таких как del df['column_name'] и df.pop('column_name'), если требуется сохранить DataFrame в памяти как единый объект, поскольку они могут быть менее предсказуемыми в комплексных сценариях и не всегда поддерживаются в цепочках операций.
Удаление столбца с обработкой ошибки, если он отсутствует
Для удаления столбца из DataFrame с предварительной проверкой его наличия используйте конструкцию с оператором if или метод pop() с обработкой исключения. Это исключает возникновение KeyError, если указанный столбец отсутствует.
Пример с использованием условия:
if 'название_столбца' in df.columns:
df.drop(columns='название_столбца', inplace=True)Такой подход безопасен и не вызывает исключений при отсутствии столбца.
Альтернативный способ – использовать конструкцию try-except с методом pop():
try:
df.pop('название_столбца')
except KeyError:
pass # или логирование ошибкиМетод pop() удаляет столбец и возвращает его содержимое, что удобно при необходимости дальнейшей обработки данных. Если столбец не найден, выбрасывается KeyError, поэтому блок try-except обязателен.
Не используйте errors='ignore' – такой аргумент отсутствует у метода drop() для удаления столбцов, он применим только к строкам (axis=0).
Удаление столбцов по условию (например, по типу данных)
В pandas можно эффективно удалять столбцы из DataFrame по различным условиям, включая тип данных столбца. Это полезно, когда необходимо очистить данные от ненужных типов или оставить только определенные столбцы для анализа.
Для того чтобы удалить столбцы по типу данных, можно использовать метод select_dtypes(), который позволяет фильтровать столбцы по типу. После этого можно вызвать метод drop() для удаления ненужных столбцов.
Пример удаления столбцов с числовыми типами:
import pandas as pd
# Пример DataFrame
df = pd.DataFrame({
'age': [25, 30, 35],
'name': ['Alice', 'Bob', 'Charlie'],
'salary': [50000, 60000, 70000]
})
# Удаление всех столбцов с типом данных 'int64' или 'float64'
df = df.drop(df.select_dtypes(include=['number']).columns, axis=1)
print(df)
В данном примере метод select_dtypes(include=['number']) выбирает все столбцы с числовыми типами данных, а затем метод drop() удаляет их из DataFrame.
Чтобы удалить столбцы с определенными типами данных, можно уточнить фильтрацию. Например, для удаления только столбцов типа int64:
df = df.drop(df.select_dtypes(include=['int64']).columns, axis=1)
print(df)
Для удаления столбцов с объектами (строки) используйте фильтрацию по типу object:
df = df.drop(df.select_dtypes(include=['object']).columns, axis=1)
print(df)
Также можно комбинировать несколько типов для фильтрации. Например, удаление как числовых, так и строковых столбцов:
df = df.drop(df.select_dtypes(include=['number', 'object']).columns, axis=1)
print(df)
Этот подход позволяет гибко управлять содержимым DataFrame, удаляя столбцы по любым условиям типа данных.
Удаление всех столбцов, кроме указанных

Для удаления всех столбцов, кроме определённых, в Pandas можно использовать метод DataFrame.loc или DataFrame.filter. Рассмотрим оба способа.
Предположим, что у вас есть DataFrame, и вам нужно оставить только несколько конкретных столбцов. Пример DataFrame:
import pandas as pd
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9], 'D': [10, 11, 12]}
df = pd.DataFrame(data)
Для удаления всех столбцов, кроме указанных, используйте loc с перечнем нужных столбцов:
df = df.loc[:, ['A', 'C']]
Этот код сохраняет только столбцы ‘A’ и ‘C’, удаляя остальные. Метод loc позволяет задать как строки, так и столбцы. Использование двоеточия (:) позволяет выбрать все строки, а в квадратных скобках указывается список нужных столбцов.
Второй способ — использование метода filter, который может быть полезен, если нужно оставить столбцы, соответствующие определённому шаблону или условиям. Например, чтобы оставить только те столбцы, название которых начинается с ‘A’ или ‘C’, можно использовать:
df = df.filter(items=['A', 'C'])
Метод filter даёт больше гибкости, особенно когда нужно отфильтровать столбцы по маске или регулярным выражениям. Этот метод также полезен для работы с большими DataFrame, когда вручную выбирать столбцы не всегда удобно.
Для более сложных фильтраций можно комбинировать методы filter и loc, что даёт широкие возможности для работы с данными, минимизируя количество кода.
При использовании любого из этих методов важно помнить, что они не изменяют исходный DataFrame, если не присвоить результат обратно в переменную. Например:
df = df.loc[:, ['A', 'C']] # Присваиваем результат обратно в df