Удаление строк из текстового файла – одна из наиболее часто выполняемых операций при работе с данными. В Python существует несколько способов решить эту задачу, и важно выбрать наиболее эффективный в зависимости от размера файла и требований к скорости обработки. В этой статье мы рассмотрим несколько подходов, которые позволяют удалить строку или строки из файла, не потеряв данные, которые нам нужны.
Основной принцип работы заключается в том, что для удаления строки необходимо прочитать файл, отфильтровать ненужные строки и затем записать обновленный файл. Простейший способ заключается в том, чтобы прочитать весь файл в память, что подходит для небольших файлов. Однако для работы с большими файлами следует использовать более продвинутые методы, такие как обработка файла построчно.
Одним из наиболее эффективных решений является использование стандартных функций Python, таких как open() и write(), в сочетании с фильтрацией строк. Также существуют сторонние библиотеки, например, pandas, которые могут быть полезны, если вы работаете с более сложными данными или требуются дополнительные манипуляции с содержимым файла.
Перед тем как приступить к удалению строки, важно помнить, что любая операция записи в файл может перезаписать данные, поэтому следует тщательно продумать логику фильтрации и записи в новый файл. Мы также рассмотрим варианты, как избежать потери данных при обработке файла.
Открытие файла для чтения и записи
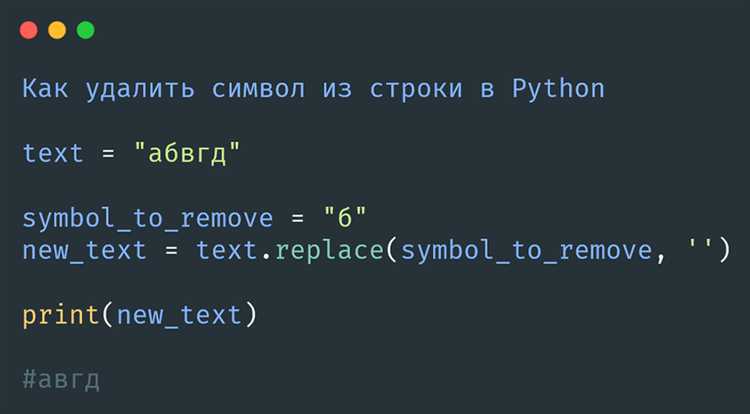
Для открытия файла с целью его чтения и записи в Python используется режим ‘r+’ в функции open(). Этот режим позволяет одновременно читать данные из файла и записывать новые данные, не удаляя содержимого. Важно отметить, что файл должен существовать, иначе будет вызвана ошибка.
Пример открытия файла для чтения и записи:
with open('example.txt', 'r+') as file:
content = file.read()
file.seek(0) # Возврат в начало файла
file.write('Новые данные') # Запись в файлРежим ‘r+’ открывает файл для чтения и записи, но не создаёт новый файл, если тот не существует. Для безопасной работы с файлами рекомендуется использовать конструкцию with open(), которая автоматически закрывает файл после завершения работы с ним.
Если необходимо создать новый файл, можно использовать режим ‘w+’ или ‘a+’. Режим ‘w+’ создаст новый файл, если он не существует, но обрежет его содержимое, а ‘a+’ добавляет данные в конец файла, не изменяя уже существующие строки.
При работе с файлами, где возможна одновременная запись и чтение, важно учитывать, что запись в файл может перезаписать данные, поэтому перед изменением данных лучше делать резервные копии или использовать другие методы работы с данными, такие как буферизация или временные файлы.
Чтение содержимого файла в память
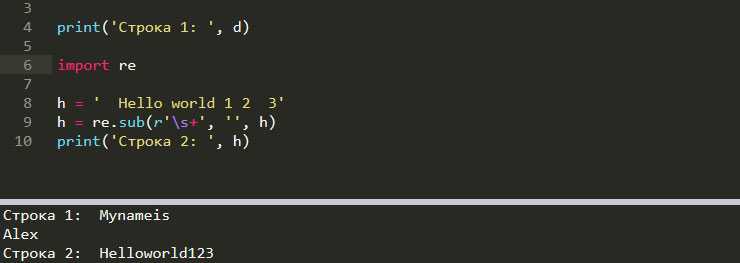
Чтение файла в Python – стандартная операция, доступная через встроенные функции. Для эффективного чтения необходимо учитывать размер файла и его формат. В Python существуют несколько методов для загрузки содержимого файла в память, и выбор метода зависит от задач.
Основные способы чтения содержимого файла:
- read() – читает весь файл целиком и возвращает его содержимое как строку.
- readlines() – читает файл построчно и возвращает список строк.
- with open() – используется для автоматического закрытия файла, что предотвращает утечку ресурсов.
Пример использования read() для чтения всего файла:
with open('file.txt', 'r') as file:
content = file.read()
Если файл слишком большой, и чтение его целиком может привести к переполнению памяти, следует использовать построчное чтение:
with open('file.txt', 'r') as file:
for line in file:
# обработка строки
В случае необходимости получить строки в виде списка, можно применить readlines():
with open('file.txt', 'r') as file:
lines = file.readlines()
Для работы с большими файлами рекомендуется читать данные небольшими частями. Для этого можно использовать аргумент size в методе read(size), который позволяет считывать файл порциями определенного размера.
Вместо чтения всего файла в память, также можно использовать метод seek() для перемещения указателя внутри файла, что позволяет эффективно работать с большими объемами данных, загружая их по частям.
Для правильной работы с файлом важно учитывать режим открытия файла. Для чтения текста используйте режим 'r', а для бинарных файлов – 'rb'.
Поиск строки по содержимому для удаления
Для удаления строки в файле по содержимому необходимо эффективно находить те строки, которые содержат нужный фрагмент текста. В Python это можно сделать несколькими способами в зависимости от сложности поиска.
Если задача заключается в удалении строк, содержащих конкретное слово или фразу, самым простым решением будет использование оператора `in`. Например, чтобы удалить все строки, содержащие слово «удалить», можно применить следующий код:
«`python
with open(‘file.txt’, ‘r’) as file:
lines = [line for line in file if ‘удалить’ not in line]
with open(‘file.txt’, ‘w’) as file:
file.writelines(lines)
Этот код проверяет каждую строку на наличие подстроки «удалить» и исключает такие строки из списка. После этого оставшиеся строки записываются обратно в файл.
Если файл слишком велик, чтобы загружать его целиком в память, можно обрабатывать его построчно, что будет более эффективно с точки зрения использования памяти. В этом случае код будет выглядеть так:
pythonCopyEditwith open(‘file.txt’, ‘r’) as file:
lines = []
for line in file:
if ‘удалить’ not in line:
lines.append(line)
with open(‘file.txt’, ‘w’) as file:
file.writelines(lines)
В данном примере строки читаются и проверяются по очереди. Если строка не содержит искомое слово, она добавляется в новый список. Затем результат записывается обратно в файл.
Если необходимо учесть более сложные условия поиска, например, искать строку с учётом регистра или использовать регулярные выражения, можно использовать модуль `re`. Это позволяет настроить поиск по шаблону, что полезно для работы с переменными текстами. Пример:
pythonCopyEditimport re
with open(‘file.txt’, ‘r’) as fi
Удаление строки из списка строк
Пример:
lines = ["Строка 1", "Строка 2", "Строка 3"]
lines.remove("Строка 2")
print(lines)
Если требуется удалить строку по индексу, можно воспользоваться операцией удаления по индексу с помощью команды del:
lines = ["Строка 1", "Строка 2", "Строка 3"] del lines[1] print(lines)
Если необходимо удалить строку и получить её значение, стоит использовать метод pop(). Этот метод удаляет элемент по индексу и возвращает его:
lines = ["Строка 1", "Строка 2", "Строка 3"] removed_line = lines.pop(1) print(removed_line) print(lines)
Когда нужно удалить все строки, содержащие определённое слово или фразу, можно использовать генератор списка. Этот способ подходит, если необходимо удалить несколько строк, удовлетворяющих определённому условию:
lines = ["Строка 1", "Удалённая строка", "Строка 2"] lines = [line for line in lines if "Удалённая" not in line] print(lines)
Для более сложных условий удаления можно использовать функцию filter() в сочетании с лямбда-функцией:
lines = ["Строка 1", "Удалённая строка", "Строка 2"] lines = list(filter(lambda line: "Удалённая" not in line, lines)) print(lines)
Таким образом, Python предоставляет различные инструменты для работы с удалением строк из списка. Выбор метода зависит от конкретной задачи и структуры данных.
Перезапись изменённого содержимого в файл
Основные этапы перезаписи содержимого файла:
- Открытие файла для записи: Файл нужно открыть в режиме записи. Если файл существует, его содержимое будет перезаписано. Если файл не существует, он будет создан.
- Запись данных: Все изменения, такие как удаление строки, должны быть записаны обратно в файл. Важно, чтобы процесс записи был корректно завершён для избежания потери данных.
- Закрытие файла: После завершения записи файл должен быть закрыт. Это гарантирует, что все изменения будут сохранены.
Пример кода для перезаписи файла после удаления строки:
with open('example.txt', 'w') as file:
file.writelines(modified_lines)
В этом примере используется метод writelines(), который записывает список строк в файл. Перед этим необходимо подготовить список modified_lines, который содержит изменённые данные.
Важно помнить, что при открытии файла в режиме 'w' старое содержимое будет перезаписано. Если требуется добавление данных в конец файла, следует использовать режим 'a' (append).
В случае с большими файлами, чтобы избежать проблем с памятью, полезно будет записывать данные порциями. Например:
with open('example.txt', 'w') as file:
for line in modified_lines:
file.write(line)
Этот подход позволяет более эффективно работать с большими объёмами данных, не загружая всё содержимое в память сразу.
Удаление строки с использованием регулярных выражений

Регулярные выражения (регекспы) в Python позволяют эффективно работать с текстовыми данными, в том числе для удаления строк из файла. Для этого часто используется модуль re, который предоставляет функционал для поиска и замены текста. Важно, что регулярные выражения дают возможность не только удалить точные совпадения, но и использовать сложные шаблоны для поиска нужных строк.
Основной метод для удаления строки с использованием регулярных выражений – это использование функции re.sub(), которая позволяет заменить найденные строки на пустую строку. Рассмотрим, как это работает:
import re
# Чтение файла
with open('example.txt', 'r') as file:
data = file.read()
# Удаление строк, которые соответствуют шаблону
pattern = r'^.*нужная строка.*$' # Шаблон для поиска строки
data = re.sub(pattern, '', data, flags=re.MULTILINE)
# Запись изменений в файл
with open('example.txt', 'w') as file:
file.write(data)
В данном примере:
- pattern – это регулярное выражение, которое ищет строки, содержащие фразу "нужная строка". Шаблон ^.*нужная строка.*$ означает: любая строка, начиная с начала строки и до конца.
- re.sub() заменяет все совпадения на пустую строку, effectively удаляя их.
- Флаг re.MULTILINE необходим для того, чтобы регулярные выражения работали по строкам, а не по всему содержимому файла как единому блоку.
Регулярные выражения позволяют гибко управлять тем, какие именно строки удалять. Например, можно удалить строки, начинающиеся с определённого слова, или те, которые содержат цифры. Пример более сложного шаблона для поиска строки, содержащей только цифры:
pattern = r'^\d+$' # Строки, содержащие только цифры
data = re.sub(pattern, '', data, flags=re.MULTILINE)
При использовании регулярных выражений важно избегать чрезмерно сложных и неоптимальных шаблонов, которые могут негативно повлиять на производительность при обработке больших файлов. Также следует учитывать, что регулярные выражения не всегда идеальны для удаления строк с очень специфической структурой – в таких случаях лучше использовать другие методы работы с текстом, такие как обработка строк по линиям с помощью простых условий.
Обработка ошибок при работе с файлами
Работа с файлами в Python требует внимательности к возможным ошибкам. Несоответствия между типами данных, отсутствие прав доступа или даже повреждение файла могут привести к исключениям. Чтобы избежать сбоев, важно обрабатывать ошибки в процессе работы с файлами с помощью конструкции try-except.
Основные ошибки при работе с файлами:
- FileNotFoundError – файл не найден по указанному пути. Это часто происходит, если путь к файлу указан неверно или файл был удалён.
- PermissionError – отсутствие прав на чтение или запись в файл. Может возникнуть, если файл защищён от изменений или у пользователя нет соответствующих прав.
Для корректной обработки ошибок рекомендуется использовать конструкцию try-except. Например, чтобы избежать ошибки при попытке открыть несуществующий файл, можно сделать так:
try:
with open('file.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print('Файл не найден.')
except PermissionError:
print('Нет прав для доступа к файлу.')
except Exception as e:
print(f'Произошла ошибка: {e}')
Кроме того, рекомендуется использовать конструкцию finally, чтобы закрыть файл, даже если произошла ошибка. Это особенно важно при работе с большими файлами, чтобы избежать утечек памяти или блокировок ресурсов:
try:
file = open('file.txt', 'r')
content = file.read()
except FileNotFoundError:
print('Файл не найден.')
except PermissionError:
print('Нет прав для доступа к файлу.')
finally:
file.close()
Использование этих подходов позволяет эффективно обрабатывать типичные ошибки и избежать неожиданного завершения программы.