В Python строка – это последовательность символов, а список – универсальная структура данных, способная хранить элементы различных типов. Преобразование между этими типами часто требуется при обработке текстовых данных, чтении файлов и работе с пользовательским вводом.
Для разделения строки по пробелам, запятым или другим разделителям используется метод split(). Он возвращает список строк, разбитых по указанному символу. Например, «яблоко,груша,слива».split(‘,’) создаёт список [‘яблоко’, ‘груша’, ‘слива’]. Если аргумент не передан, по умолчанию используется любое количество пробелов.
Когда нужно получить список отдельных символов строки, применяют list(). Вызов list(«Python») даст результат [‘P’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]. Этот подход полезен при необходимости анализа символов по отдельности, включая пробелы и знаки препинания.
Если строка содержит структуру данных в виде, например, списка, заключённого в кавычки, и нужно получить настоящий список, следует использовать функцию ast.literal_eval() из модуля ast. Это безопасная альтернатива eval() при преобразовании строк, содержащих литералы Python.
Ошибка типа AttributeError при попытке вызвать split() у объекта, который не является строкой, часто свидетельствует о необходимости предварительной проверки типа данных. Использование isinstance() позволяет избежать таких ситуаций при обработке входных данных из разных источников.
Как разделить строку по пробелам с помощью split()
Метод split() без аргументов разбивает строку по последовательностям пробелов, табов и других пробельных символов. Результат – список подстрок без пустых элементов.
текст = "python split пример"
результат = текст.split()
print(результат) # ['python', 'split', 'пример']- Несколько пробелов между словами игнорируются.
- Начальные и конечные пробелы не влияют на результат.
- Если строка пустая или содержит только пробелы, вернётся пустой список.
Для контроля над разделителем указывайте его явно. Пример:
строка = "раз два три"
рез = строка.split(" ")
print(рез) # ['раз', 'два', '', 'три']- Если задан пробел в качестве аргумента, пустые строки между несколькими пробелами сохраняются.
- В таком случае результат зависит от точного количества пробелов в исходной строке.
split()без аргументов – для очистки от лишних пробелов.split(" ")– для учёта всех пробелов, включая пустые элементы между ними.
Преобразование строки с запятыми в список чисел

Строка вида "1,2,3,4.5,6" может быть преобразована в список чисел через метод split() и генераторное выражение с приведением типов. В простейшем случае:
numbers = [int(x) for x in s.split(",")]
Если в строке могут быть десятичные значения, используется float():
numbers = [float(x) for x in s.split(",")]
При наличии пробелов после запятых применяют strip():
numbers = [float(x.strip()) for x in s.split(",")]
Чтобы избежать ошибки при некорректных данных, используют фильтрацию и обработку исключений. Пример с пропуском пустых элементов и нечисловых значений:
def parse_numbers(s):
result = []
for part in s.split(","):
part = part.strip()
if not part:
continue
try:
result.append(float(part))
except ValueError:
continue
return result
При необходимости округления или приведения к int используют int(float(...)). Например:
numbers = [int(float(x)) for x in s.split(",") if x.strip()]
Как разбить строку по символам, не теряя пробелы
Для побуквенного разбиения строки в Python, включая пробелы, применяется функция list(). Она создаёт список, где каждый элемент – отдельный символ исходной строки, включая пробелы, табуляции и другие управляющие символы.
Пример:
текст = "Пример строки"
результат = list(текст)
print(результат)
['П', 'р', 'и', 'м', 'е', 'р', ' ', 'с', 'т', 'р', 'о', 'к', 'и']В результате пробел между словами сохранён. Это поведение предсказуемо и не требует дополнительных параметров или регулярных выражений.
Если в строке присутствуют специальные символы, например, перенос строки \n или табуляция \t, они также будут включены в итоговый список как отдельные элементы:
текст = "Первая строка\nВторая"
результат = list(текст)
Для работы с Unicode-строками, включая символы за пределами базовой латиницы, list() корректно сохраняет всю последовательность без искажений:
текст = "😊 Привет"
результат = list(текст)Результат будет включать emoji и пробел как отдельные элементы. Если требуется исключить символы типа пробелов, применяется list(текст.replace(" ", "")), но для их сохранения этого делать не нужно.
Удаление лишних символов перед преобразованием строки
Перед разбиением строки на элементы необходимо исключить символы, не являющиеся частью полезных данных. Например, пробелы, символы новой строки, кавычки, запятые вне структуры, управляющие последовательности и лишние разделители.
Для удаления пробелов по краям строки применяется метод strip(). Если необходимо удалить конкретные символы, используйте strip(‘символы’). Например: s.strip(‘ [],»\n’).
Метод replace() подходит для удаления или замены нежелательных символов внутри строки. Пример: s.replace(‘\\n’, »).replace(‘»‘, »). Последовательное применение replace() позволяет очистить строку от символов, нарушающих корректное преобразование.
Регулярные выражения через модуль re эффективны для удаления шаблонных участков. Например, re.sub(r'[^\w\s,.-]’, », s) удалит все символы, кроме букв, цифр, пробелов, запятой, точки и дефиса. Такой подход особенно полезен при обработке данных из внешних источников.
Если строка представляет собой список в текстовом виде (например, «[‘a’, ‘b’, ‘c’]»), её можно предварительно очистить от скобок и кавычек: s.strip(‘[]’).replace(«‘», »).
При необходимости избавиться от повторяющихся разделителей, используйте split() и filter() для исключения пустых элементов: list(filter(None, s.split(‘,’))).
Точная последовательность очистки зависит от структуры исходной строки. Всегда анализируйте входной формат, чтобы исключить потерю значимых данных.
Преобразование многострочной строки в список строк

Многострочную строку можно разбить на список строк с помощью метода splitlines(). Он учитывает символы перевода строки и возвращает элементы без них:
text = "первая строка\nвторая строка\nтретья строка"
строки = text.splitlines()
# ['первая строка', 'вторая строка', 'третья строка']
Метод splitlines() принимает необязательный аргумент keepends. Если передать True, символы перевода строки сохранятся:
строки = text.splitlines(True)
# ['первая строка\n', 'вторая строка\n', 'третья строка']
Альтернативный способ – использовать split(‘\n’). Он разделяет по символу новой строки, но не учитывает другие варианты, например \r\n на Windows:
строки = text.split('\n')
Для предобработки можно удалить пустые строки с помощью генератора списка:
строки = [строка for строка in text.splitlines() if строка.strip()]
Если строка получена из файла, метод read().splitlines() позволяет избежать лишних символов в конце:
with open('файл.txt', 'r', encoding='utf-8') as f:
строки = f.read().splitlines()
Как превратить строку JSON в список Python

Для преобразования строки в формате JSON в список Python используется модуль json. Строка JSON представляет собой текст, который можно интерпретировать как структуру данных, аналогичную спискам, словарям и другим типам данных Python. Чтобы преобразовать строку JSON в список, нужно использовать функцию json.loads().
Пример работы:
import json
json_string = '["яблоко", "банан", "вишня"]'
python_list = json.loads(json_string)
print(python_list)В этом примере строка JSON содержит массив, который при преобразовании в Python становится обычным списком. Функция json.loads() автоматически интерпретирует формат JSON и преобразует его в соответствующий тип данных Python, в данном случае в список.
Если в строке JSON содержатся ошибки, json.loads() вызовет исключение json.JSONDecodeError. Чтобы избежать ошибок при обработке данных, полезно использовать блок try-except для обработки возможных исключений:
try:
python_list = json.loads(json_string)
except json.JSONDecodeError:
print("Ошибка в формате JSON")Для работы с более сложными структурами JSON, которые могут содержать вложенные списки или словари, json.loads() также корректно интерпретирует эти структуры, создавая соответствующие объекты Python.
Важно помнить, что строка JSON должна быть корректно отформатирована, чтобы избежать ошибок. JSON использует двойные кавычки для строк, а не одинарные, как в Python.
Вопрос-ответ:
Как преобразовать строку в список символов в Python?
Для того чтобы преобразовать строку в список символов, можно просто использовать функцию `list()`. Например, если у вас есть строка `s = «hello»`, то вызов `list(s)` вернет список `[‘h’, ‘e’, ‘l’, ‘l’, ‘o’]`. Это достаточно простой способ разделить строку на отдельные символы.
Можно ли преобразовать строку в список подстрок в Python?
Да, для этого используется метод строки `split()`. Он разделяет строку на подстроки по заданному разделителю. Например, для строки `s = «apple,banana,cherry»`, вызов `s.split(‘,’)` вернет список подстрок `[‘apple’, ‘banana’, ‘cherry’]`. Если разделитель не указан, строка будет разделена по пробелам.
Как преобразовать строку в список чисел в Python?
Для этого можно использовать метод `split()`, чтобы разделить строку на части, а затем применить функцию `map()` или list comprehension для преобразования каждой части в число. Например, если у вас есть строка `s = «1 2 3 4″`, то можно сделать так: `list(map(int, s.split()))`, и результат будет `[1, 2, 3, 4]`.
Как преобразовать строку в список слов, разделенных по пробелам, в Python?
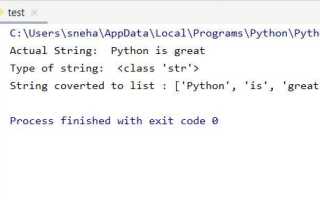
Для этого можно просто использовать метод `split()`, который по умолчанию разделяет строку по пробелам. Например, если у вас есть строка `s = «Python is awesome»`, то вызов `s.split()` вернет список `[‘Python’, ‘is’, ‘awesome’]`. Этот метод также удаляет лишние пробелы между словами.
Как превратить строку в список, где каждый элемент будет отдельным словом из строки, но с учетом нескольких пробелов?
Для того чтобы разделить строку на слова, игнорируя лишние пробелы, можно использовать метод `split()` без параметров. Например, строка `s = » Python is awesome «` после вызова `s.split()` вернет список `[‘Python’, ‘is’, ‘awesome’]`, игнорируя лишние пробелы в начале, в конце и между словами.