

При выборе базы данных для проектов на Python ключевыми факторами являются требования к производительности, тип данных и масштабируемость. Важно не только выбрать подходящую СУБД, но и учитывать особенности взаимодействия с ней через Python-библиотеки.
Реляционные базы данных (например, PostgreSQL, MySQL) идеально подходят для проектов, требующих сложных запросов и строгой структуры данных. PostgreSQL, например, известна своей поддержкой сложных типов данных и расширений, что делает её отличным выбором для аналитики и многозадачных приложений. MySQL подходит для более простых решений, но с ограниченными возможностями для расширений.
Если ваш проект связан с обработкой больших объемов неструктурированных данных, то NoSQL базы данных (например, MongoDB, Cassandra) могут быть лучшим выбором. MongoDB подходит для приложений, где требуется высокая скорость записи и горизонтальное масштабирование. Cassandra хорошо справляется с задачами, где важна высокая доступность и скорость записи на больших объемах данных, но с возможными компромиссами в консистентности.
Для проектов, где требуется поддержка транзакций и строгих бизнес-логик, а также высокая целостность данных, лучше обратить внимание на гибридные решения как SQLite для локальных приложений или CockroachDB для облачных сервисов. Они обеспечивают баланс между реляционными и распределёнными моделями данных.
Как определить тип базы данных для вашего проекта на Python

Выбор типа базы данных зависит от нескольких ключевых факторов, включая структуру данных, требования к производительности и масштабируемости, а также особенности вашего проекта. Рассмотрим основные критерии, которые помогут сделать правильный выбор.
1. Тип данных и структура: если ваши данные строго структурированы, хорошо подходят реляционные базы данных (например, PostgreSQL или MySQL). Они обеспечивают нормализацию и высокую целостность данных. Для проектов, где данные менее структурированы или варьируются по типу (например, JSON, XML), лучше выбрать NoSQL решения (MongoDB, CouchDB). Эти базы данных предлагают гибкость в работе с данными и позволяют легко изменять их схему.
2. Требования к производительности: если проект требует высокой скорости записи и чтения, стоит обратить внимание на базы данных, оптимизированные для таких операций. NoSQL базы данных (например, Redis или Cassandra) могут справляться с большими объемами данных и высокой нагрузкой, предоставляя минимальные задержки. В случае, если критична сложная логика запросов и транзакции, лучше выбрать реляционные базы данных с поддержкой индексов и транзакций.
3. Масштабируемость: если вы планируете масштабировать проект в будущем, важно учитывать, насколько база данных может быть расширена. Реляционные базы данных могут столкнуться с проблемами при горизонтальном масштабировании. Для таких целей подходят NoSQL базы, которые хорошо работают с кластеризацией и распределенными системами. Однако реляционные СУБД, такие как PostgreSQL, поддерживают вертикальное масштабирование и могут решать задачи с помощью шардирования.
4. Ожидаемая нагрузка: для систем с высокой нагрузкой, например, в реальном времени, рекомендуется использовать in-memory базы данных, такие как Redis или Memcached, которые обеспечивают мгновенный доступ к данным. Это особенно важно, если данные используются для кеширования, сессий или других задач, требующих минимальной задержки.
5. Поддержка транзакций: если в вашем проекте требуется обработка сложных транзакций с высокой целостностью данных, выбирайте реляционные базы данных, такие как PostgreSQL или MySQL, которые поддерживают ACID (атомарность, согласованность, изоляция и долговечность). Для приложений, где важна высокая доступность и скорость, можно рассмотреть базы данных с eventual consistency, например, MongoDB.
6. Сложность разработки и экосистема: важно учитывать не только функциональные возможности базы данных, но и доступность библиотек и фреймворков для Python. Базы данных с хорошей поддержкой и документацией, такие как PostgreSQL, MySQL или MongoDB, будут более удобны для быстрого начала разработки. Важно учитывать совместимость выбранной базы данных с ORM-библиотеками, такими как SQLAlchemy или Django ORM.
7. Стоимость: при выборе базы данных также стоит оценить стоимость эксплуатации, включая лицензирование, поддержание и оптимизацию. Бесплатные решения, такие как PostgreSQL или MySQL, могут подойти для большинства проектов, в то время как коммерческие решения, например, Oracle, могут потребовать дополнительных затрат, если проект вырастет в масштабе.
Как оценить производительность базы данных в зависимости от объема данных

Производительность базы данных напрямую зависит от объема данных, и понимание этого фактора критично для правильного выбора решения. Оценка производительности начинается с тестирования запросов на реальных или приближенных к реальным объемах данных. Важно учитывать, как база данных справляется с увеличением нагрузки при росте данных и каких изменений ожидать в скорости обработки запросов.
Для начала стоит провести тесты на загрузку базы данных с различными объемами данных – например, от 10 тыс. до 10 млн записей. Это поможет понять, как изменяется время отклика на запросы. На ранних этапах тестирования можно использовать индексы, чтобы определить, как их наличие влияет на время выполнения запросов с увеличением объема данных. Важно понимать, что в некоторых случаях использование индексов может замедлить операции записи, поэтому необходимо найти баланс.
Также стоит учитывать тип базы данных. Реляционные СУБД (например, PostgreSQL, MySQL) обычно эффективно работают с данными среднего объема, но могут начать страдать от падения производительности при запросах к гигантским таблицам, особенно без должной оптимизации индексов. В случае NoSQL баз данных (например, MongoDB, Cassandra) производительность при росте объема данных может оставаться стабильной, но их настройка и управление могут потребовать дополнительных усилий, особенно в плане репликации и распределения данных.
Для оценки производительности важно провести стресс-тестирование с конкретными операциями – вставка данных, обновление, удаление, выборки. Также стоит учесть тип запросов: сложные запросы с множеством соединений и фильтров на больших объемах данных могут значительно замедлить выполнение. В таких случаях стоит оценить использование механизма кэширования и кэширования на уровне приложения, чтобы уменьшить нагрузку на базу данных.
Не менее важным является мониторинг потребления ресурсов, таких как CPU, RAM и дисковое пространство при обработке данных. Базы данных, которые активно используют кеширование или сжимаются данные, могут быть более эффективными с точки зрения потребления памяти, но они также могут требовать дополнительных вычислительных ресурсов. Сравнив результаты тестов на разных СУБД, можно выбрать оптимальную по производительности и экономичности в зависимости от характера данных и их объема.
Для реальной оценки стоит также учитывать прогнозируемый рост данных. Например, если данные будут расти в несколько раз в год, важно заранее учитывать, как выбранная база данных будет справляться с таким ростом в долгосрочной перспективе. Хорошим вариантом будет использование кластеризации или шардирования данных для распределения нагрузки.
Какие базы данных лучше подходят для работы с реляционными данными в Python

Для работы с реляционными данными в Python лучше всего подходят базы данных, поддерживающие стандарт SQL и эффективно взаимодействующие с Python-библиотеками. Выбор зависит от требуемой масштабируемости, производительности и особенностей приложения.
- PostgreSQL – одна из самых популярных реляционных СУБД, известна своей гибкостью и расширяемостью. Поддерживает сложные запросы, индексы и транзакции. В Python для работы с PostgreSQL используется библиотека
psycopg2, которая оптимизирована для высокоскоростной работы с данными. - MySQL – стабильная и производительная СУБД, широко применяемая в веб-разработке. Библиотека
mysql-connector-pythonпредоставляет простой интерфейс для взаимодействия с базой данных. MySQL чаще выбирают для проектов, где важна производительность при больших объемах данных. - SQLite – легковесная реляционная база данных, идеально подходящая для разработки небольших приложений или для использования в тестах. Она встроена в стандартную библиотеку Python, что делает её удобной для начальных этапов разработки или встраивания в локальные приложения. Библиотека
sqlite3предоставляет все необходимые функции для работы с SQLite. - MariaDB – форк MySQL, совместим с большинством его функций, но обладает улучшенной производительностью и дополнительными возможностями, такими как шифрование и расширенная поддержка индексов. Подключение к MariaDB выполняется через ту же библиотеку
mysql-connector-python. - Microsoft SQL Server – мощная СУБД, широко используемая в корпоративных приложениях. Для взаимодействия с SQL Server в Python используется библиотека
pyodbc, обеспечивающая стабильное соединение и возможность работы с большими объемами данных.
В зависимости от задачи стоит выбирать СУБД, учитывая её особенности. PostgreSQL и MySQL идеально подходят для более сложных, масштабируемых проектов, в то время как SQLite подходит для легковесных приложений с ограниченными ресурсами. Важно помнить, что для большинства современных Python-приложений PostgreSQL является предпочтительным выбором из-за своей гибкости и производительности.
Как выбрать базу данных для масштабируемых приложений на Python
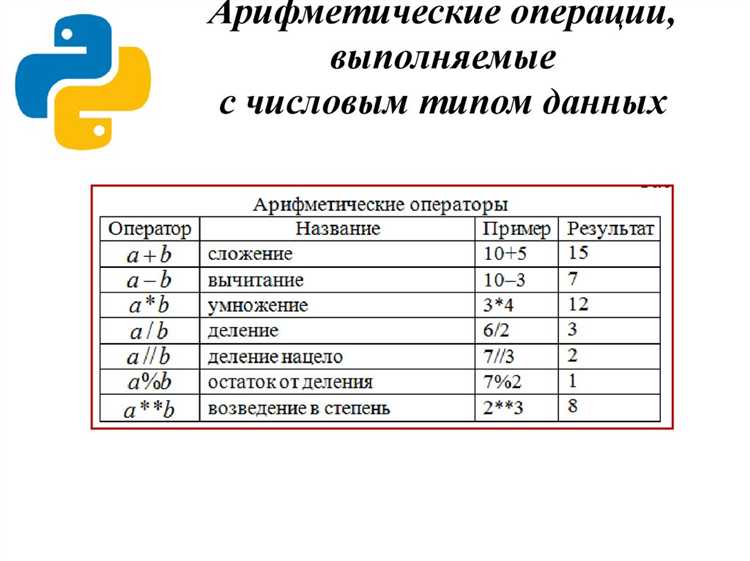
При выборе базы данных для масштабируемых приложений на Python важно учитывать несколько ключевых факторов, которые определяют производительность и способность системы расти. Это включает в себя тип данных, требуемую пропускную способность, возможности горизонтального масштабирования и совместимость с Python.
Для приложений с высокой нагрузкой часто выбираются базы данных, поддерживающие горизонтальное масштабирование, такие как NoSQL решения. MongoDB и Cassandra – популярные выборы для работы с большими объемами данных, так как они могут масштабироваться без потери производительности при увеличении числа узлов. MongoDB особенно эффективна для приложений, работающих с неструктурированными данными, такими как документы или события.
Если приложение требует транзакционной целостности и строгих гарантий, реляционные базы данных, такие как PostgreSQL или MySQL, могут быть подходящим выбором. PostgreSQL поддерживает сложные запросы, индексацию и отлично справляется с большими объемами данных при правильной настройке. Важно учитывать, что хотя реляционные БД традиционно используют вертикальное масштабирование, решения, такие как Citus для PostgreSQL, обеспечивают возможности горизонтального масштабирования, что позволяет работать с большими наборами данных.
В случае работы с приложениями, требующими очень высокой скорости чтения и записи, полезно рассмотреть использование in-memory баз данных, таких как Redis или Memcached. Redis не только обеспечивает кэширование данных, но и позволяет использовать его как основную базу данных для приложений, которым нужно быстрое реагирование при масштабировании. Эти решения особенно эффективны для сценариев, когда необходима минимальная задержка, например, в системах рекомендаций или реальном времени.
Важно также учитывать затраты на администрирование базы данных. Некоторые системы, такие как Amazon Aurora или Google Cloud SQL, предлагают управляемые сервисы, что избавляет от необходимости в ручном управлении инфраструктурой, однако может увеличивать стоимость. В случае самостоятельного развертывания базы данных нужно быть готовым к дополнительным трудозатратам на настройку и поддержку масштабируемости.
Кроме того, стоит обращать внимание на поддержку синхронных и асинхронных операций. Для Python особенно важна поддержка асинхронных операций, что позволяет улучшить производительность приложений при обработке большого числа одновременных запросов. В этом контексте PostgreSQL с библиотеками типа asyncpg становится хорошим выбором.
Оценка стоимости и доступности поддержки также является немаловажным аспектом при принятии решения. Для многих проектов критически важна возможность быстрой реакции на проблемы, а также наличие сообщества и документации для решения возникающих вопросов.
Что учитывать при выборе базы данных для работы с NoSQL в Python

Выбор базы данных NoSQL для Python зависит от нескольких факторов, которые определяют эффективность работы с данными в вашем проекте. Прежде чем остановиться на конкретной базе данных, важно оценить следующие ключевые аспекты:
- Тип данных и структура. Определите, какой тип данных вы будете хранить. NoSQL базы данных бывают различных типов: документно-ориентированные, графовые, ключ-значение и колоночные. Если данные структурированы как документы (например, JSON), то лучшим выбором может быть MongoDB или CouchDB. Для хранения графов лучше использовать Neo4j, а для простых ключ-значение – Redis или Riak.
- Масштабируемость. Если ваш проект предполагает большие объемы данных или необходимость в масштабировании, важно выбрать базу данных, которая поддерживает горизонтальное масштабирование. Например, Cassandra и Couchbase обеспечивают высокую доступность и масштабируемость на распределенных кластерах.
- Производительность. Важно учитывать скорость обработки запросов, которая зависит от специфики работы с данными. Redis обеспечивает сверхбыструю работу с данными благодаря хранению в памяти, что идеально подходит для кэширования и обработки сессий. Однако если нужны более сложные запросы, MongoDB или Couchbase предложат хороший баланс между производительностью и функциональностью.
- Гибкость запросов. Некоторые NoSQL базы данных, такие как MongoDB, поддерживают богатый синтаксис запросов, аналогичный SQL, что упрощает работу с большими и сложными данными. В то время как базы данных, ориентированные на ключ-значение, как Redis, ограничены в функционале запросов и чаще требуют использования простых операций над данными.
- Поддержка транзакций. Если вашему приложению необходимы транзакции, следует выбирать NoSQL систему, поддерживающую атомарные операции. MongoDB с транзакциями на уровне нескольких документов или Couchbase с поддержкой мульти-документных транзакций подойдут для этого случая. Базы данных как Cassandra могут не поддерживать такие транзакции в полном объеме, что ограничивает их использование в некоторых сценариях.
- Интеграция с Python. Разные базы данных имеют различные библиотеки для работы с Python. Например, для MongoDB существует библиотека PyMongo, для Redis – redis-py. Убедитесь, что выбранная база данных имеет хорошо поддерживаемый и эффективный Python клиент, который предоставит вам нужные функции и удобство работы.
- Сообщество и документация. Важно учитывать наличие активного сообщества и хорошей документации. Базы данных с большим сообществом (например, MongoDB или Redis) обладают множеством примеров и решений распространенных проблем. Это существенно ускоряет процесс разработки и интеграции в проект.
- Поддержка и лицензирование. Перед выбором стоит ознакомиться с лицензией базы данных, особенно если проект коммерческий. Многие популярные базы данных NoSQL, такие как MongoDB и Cassandra, имеют открытые лицензии, но важно учитывать возможные изменения в лицензировании и особенности поддержки в будущем.
Как интегрировать базу данных с фреймворками Python

В Django интеграция происходит через ORM, настроенный в файле settings.py. Для PostgreSQL необходимо установить пакет psycopg2 и задать параметры подключения: ENGINE = 'django.db.backends.postgresql', NAME, USER, PASSWORD, HOST, PORT. После этого модели создаются как Python-классы, а миграции автоматически синхронизируют структуру базы данных с кодом.
Во Flask базу данных подключают вручную или через расширения. С использованием SQLAlchemy достаточно установить flask_sqlalchemy, задать URI подключения в app.config['SQLALCHEMY_DATABASE_URI'] и инициализировать объект SQLAlchemy(app). Для асинхронной работы лучше использовать SQLModel с FastAPI и asyncpg. Подключение выполняется через create_async_engine и AsyncSession из sqlalchemy.ext.asyncio.
В Pyramid работа с базой реализуется через конфигурационные файлы и регистрацию фабрик подключения. Используется zope.sqlalchemy для управления транзакциями. Инициализация проходит в __init__.py приложения через сканирование модулей с моделями и настройку DBSession.
При использовании Tortoise ORM с асинхронными фреймворками необходимо явно вызывать Tortoise.init с конфигурацией подключения и Tortoise.generate_schemas для создания схем. Поддерживаются SQLite, PostgreSQL и MySQL.
Каждый фреймворк требует учитывать особенности жизненного цикла приложения, чтобы правильно управлять сессиями, миграциями и асинхронными вызовами. Универсальных решений нет – выбирайте библиотеку и способ интеграции, ориентируясь на масштаб проекта, тип нагрузки и требования к производительности.
Как выбрать базу данных, учитывая требования безопасности и резервного копирования

При выборе СУБД важно оценить поддерживаемые механизмы шифрования, контроль доступа и возможности для автоматизированного резервного копирования. Ниже приведены конкретные параметры, на которые следует опираться.
| Критерий | Рекомендации |
|---|---|
| Шифрование данных | Выбирайте СУБД с поддержкой Transparent Data Encryption (TDE), например PostgreSQL с расширением pgcrypto или MS SQL Server с встроенным TDE. Для MongoDB включите Encryption at Rest. |
| Аутентификация и авторизация | Оцените наличие ролевой модели доступа (RBAC), интеграции с LDAP/Active Directory и поддержки многофакторной аутентификации. PostgreSQL и MySQL предоставляют расширенные механизмы контроля доступа на уровне ролей и IP-ограничений. |
| Аудит операций | Выбирайте СУБД с возможностью логирования DDL и DML-операций. Oracle, PostgreSQL (через pgaudit) и MS SQL поддерживают настройку детального аудита. |
| Резервное копирование | Отдавайте предпочтение системам с встроенными средствами создания инкрементных и полноценных бэкапов (например, PostgreSQL с pgBackRest, MongoDB с mongodump/mongorestore). Убедитесь в поддержке шифрования и хранения бэкапов вне основного узла. |
| Автоматизация | Важно наличие API или CLI-инструментов для интеграции в CI/CD и cron-джобы. SQLite исключите из рассмотрения, если требуются автоматизированные бэкапы и масштабируемость. |
Безопасность и резервное копирование – не абстрактные требования, а конкретные технические характеристики. При выборе базы данных нужно не просто проверять наличие нужных функций, но и тестировать их в контексте вашей инфраструктуры и угроз.
Вопрос-ответ:
Какая база данных лучше подойдёт для небольшого веб-приложения на Flask?
Для небольшого проекта на Flask часто выбирают SQLite. Она встроена в Python, не требует отдельной установки сервера и хорошо подходит для приложений с небольшим объёмом данных и низкой нагрузкой. При этом её легко использовать — достаточно стандартной библиотеки `sqlite3`. Если приложение планируется расширять или запускать в многопользовательской среде, стоит рассмотреть PostgreSQL или MySQL.
Что выбрать для проекта, где важна масштабируемость и высокая нагрузка?
Если предполагается большая нагрузка, стоит рассмотреть PostgreSQL или MongoDB. PostgreSQL — надёжная реляционная СУБД с хорошей поддержкой масштабирования, транзакций и сложных запросов. MongoDB — нереляционная СУБД, лучше справляется с документно-ориентированными данными и может быть проще в настройке для горизонтального масштабирования. Выбор зависит от структуры данных: если она строго табличная — PostgreSQL; если данные гибкие или часто меняются по структуре — MongoDB.
Можно ли использовать одну и ту же СУБД для локальной разработки и продакшн-сервера?
Да, это возможно и даже желательно. Однако при разработке часто используют SQLite из-за её простоты, а на сервере — PostgreSQL или MySQL. Если приложение серьёзное и будет развёрнуто в продакшне, лучше с самого начала использовать ту же СУБД, которая будет на сервере. Это помогает избежать неожиданного поведения и несовместимостей при переносе данных или запросов.
Насколько сложно использовать MongoDB с Python?
Работать с MongoDB из Python довольно просто благодаря библиотеке `pymongo`. Она предоставляет понятный интерфейс для взаимодействия с коллекциями, документов и запросов. Также доступны дополнительные инструменты, такие как `mongoengine`, которые позволяют использовать объектно-ориентированный подход. Однако нужно учитывать, что MongoDB не поддерживает SQL, и работа с данными устроена по-другому — вместо таблиц используются коллекции документов.
Какая СУБД будет наиболее удобной для начинающего разработчика на Python?
Для начала подойдёт SQLite. Её легко подключить — она входит в стандартную библиотеку, не требует отдельного сервера и хорошо документирована. Она позволяет быстро начать работать с запросами SQL и понять основы взаимодействия между Python и базой данных. Позже можно перейти к более функциональным СУБД, таким как PostgreSQL или MongoDB, когда появится потребность в дополнительной гибкости или производительности.
Какие факторы нужно учитывать при выборе базы данных для проекта на Python?
При выборе базы данных для Python нужно учитывать несколько факторов. Во-первых, важно понять, какие требования предъявляются к проекту: объем данных, частота запросов, необходимость масштабирования, тип данных (структурированные или неструктурированные). Во-вторых, стоит учитывать возможности интеграции с Python, например, наличие поддерживаемых библиотек и драйверов. Также важен вопрос производительности, безопасности и поддержки транзакций. Нужно также понимать, как база данных будет работать в условиях роста нагрузки и как быстро можно будет масштабировать систему. Выбор между реляционными и нереляционными базами данных зависит от структуры данных и требований к гибкости. Например, для сложных запросов и строгих связей между данными лучше подойдет реляционная СУБД, а для гибких и масштабируемых решений можно рассмотреть NoSQL базы данных.





