Работа с файлами в Python – одна из самых часто используемых задач при обработке данных. Чтобы извлечь конкретную строку из текстового файла, существует несколько эффективных методов. Важно понимать, какой именно подход лучше всего подходит для вашей задачи, в зависимости от размера файла, его структуры и объема данных.
Прежде всего, при извлечении строки из файла важно учитывать, что операции чтения могут быть ресурсоемкими, особенно для больших файлов. Использование методов вроде readline(), readlines() и даже простого for цикла помогает выбрать нужную строку. Однако стоит помнить, что считывание всего содержимого файла в память – не всегда оптимальное решение. Поэтому для работы с большими файлами часто применяют построчное чтение, минимизируя использование памяти.
Одним из самых простых и быстрых способов является использование индексации в сочетании с циклом. Для этого нужно пройти по всем строкам файла, проверяя их с помощью условных операторов. Если строка соответствует критериям, вы можете обработать ее сразу. Такой подход идеален, если требуется извлечь одну строку, соответствующую определенному условию, например, строку с конкретным значением или определенной структурой.
В случае если файл достаточно большой и необходимо извлечь несколько строк, можно воспользоваться потоками для оптимизации работы программы. Это снизит нагрузку на память и ускорит выполнение операций. Рекомендуется заранее продумать стратегию работы с файлами, чтобы избежать излишней загрузки системы при чтении больших объемов данных.
Чтение содержимого файла с помощью Python
В Python для чтения содержимого файла используется встроенная функция open(), которая открывает файл и возвращает объект файла. После этого можно работать с ним с помощью различных методов: read(), readline() и readlines().
Для начала нужно открыть файл. Например, чтобы открыть файл в режиме чтения, используется следующий код:
file = open('путь_к_файлу', 'r')В режиме ‘r’ файл открывается для чтения, и если файл не существует, будет вызвана ошибка. Чтобы избежать этой ошибки, лучше использовать контекстный менеджер with, который автоматически закрывает файл после завершения работы с ним:
with open('путь_к_файлу', 'r') as file:Для извлечения всего содержимого файла можно использовать метод read(), который возвращает строку с полным содержимым файла:
with open('путь_к_файлу', 'r') as file:
content = file.read()Если нужно прочитать только одну строку, можно воспользоваться методом readline(). Он возвращает одну строку файла, включая символ новой строки в конце:
with open('путь_к_файлу', 'r') as file:
line = file.readline()Для чтения всех строк файла и их сохранения в список, используется метод readlines(). Этот метод возвращает список, где каждый элемент – строка из файла:
with open('путь_к_файлу', 'r') as file:
lines = file.readlines()Для обработки больших файлов рекомендуется читать их по частям, чтобы не загружать в память весь файл. Например, можно читать по строкам с помощью for цикла:
with open('путь_к_файлу', 'r') as file:
for line in file:
# обработка строкиЭтот подход значительно экономит память, особенно при работе с большими файлами.
После завершения работы с файлом его необходимо закрыть. Использование контекстного менеджера with гарантирует, что файл будет закрыт автоматически, даже если в процессе чтения возникнет ошибка.
Использование метода read() для извлечения строк
Метод read() позволяет загружать содержимое файла в виде одной строки. Это удобно для работы с небольшими файлами, где требуется получить весь текст целиком, или когда нужно извлечь определённый фрагмент. Метод считывает данные начиная с текущей позиции указателя и до конца файла.
При использовании read() важно учитывать два аспекта: размер файла и необходимость работы с отдельными строками. Метод загружает весь файл в память, что может быть неэффективно для больших файлов. Если необходимо извлечь только определённую строку, можно комбинировать read() с другими методами для обработки текста.
Пример использования read() для извлечения текста файла:
with open('example.txt', 'r') as file:
content = file.read()
print(content)lines = content.splitlines()
specific_line = lines[2] # Извлекаем третью строку
print(specific_line)Метод read() полезен, когда требуется работать с небольшими объемами данных. Для больших файлов, когда нужно извлечь несколько строк или обработать данные построчно, рекомендуется использовать другие методы, такие как readline() или обход файла в цикле.
Чтение файла построчно с помощью метода readline()

Метод readline() позволяет эффективно читать файл строка за строкой. Это полезно, когда нужно работать с большими файлами, чтобы не загружать весь файл в память сразу. Метод возвращает одну строку из файла за вызов, включая символ новой строки в конце, если он присутствует.
Пример использования метода:
with open('example.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip()) # убираем символ новой строки
line = file.readline()Каждый вызов readline() возвращает следующую строку файла, пока не будет достигнут конец. Если конец файла достигнут, метод возвращает пустую строку.
Важно помнить, что метод readline() читает файл последовательно, что делает его удобным для обработки больших данных. Однако он может быть менее эффективен по сравнению с другими методами, такими как readlines(), если нужно извлечь все строки сразу.
Для безопасного открытия и чтения файлов рекомендуется использовать конструкцию with, чтобы гарантировать закрытие файла после завершения работы. Также стоит учитывать, что метод readline() может быть полезен в сценариях, где нужно обрабатывать данные поочередно, например, при анализе логов или построчной фильтрации информации.
При чтении больших файлов с помощью readline() также стоит учитывать возможное влияние скорости работы на производительность. В таких случаях можно дополнительно оптимизировать чтение, используя методы буферизации, например, с помощью io.BufferedReader.
Поиск строки по конкретному условию в файле
Для поиска строки в файле по конкретному условию в Python можно использовать различные методы. Главное – грамотно сформулировать условие и выбрать оптимальный способ обработки содержимого файла.
Для поиска строки с определённым условием рекомендуется работать с методом open() и итерацией по строкам файла. Вот несколько практических рекомендаций:
- Открытие файла для чтения: используйте контекстный менеджер
withдля автоматического закрытия файла после обработки. - Чтение построчно: это позволит вам обрабатывать файл по мере его чтения, не загружая весь файл в память.
- Использование условий: можно искать строки, удовлетворяющие определённым критериям, например, наличие подстроки или выполнение числового условия.
Пример поиска строки, содержащей определённую подстроку:
with open('file.txt', 'r') as file:
for line in file:
if 'ключевое слово' in line:
print(line)
Если условие более сложное, например, строка должна содержать число больше определённого значения, можно комбинировать фильтры:
with open('file.txt', 'r') as file:
for line in file:
try:
number = int(line.strip()) # Преобразуем строку в число
if number > 100:
print(line)
except ValueError:
continue # Пропускаем строки, которые не могут быть преобразованы в число
Если файл слишком большой, чтобы обрабатывать его целиком в памяти, полезно использовать пакет itertools для работы с потоковыми данными:
import itertools
with open('file.txt', 'r') as file:
for line in itertools.islice(file, 10, 20): # Чтение строк с 10 по 20
if 'условие' in line:
print(line)
Кроме того, если необходимо выполнять более сложные поисковые операции, например, регулярные выражения, можно использовать модуль re для поиска строк по шаблону:
import re
pattern = re.compile(r'\d{3}-\d{2}-\d{4}') # Пример для поиска по шаблону (например, SSN)
with open('file.txt', 'r') as file:
for line in file:
if pattern.search(line):
print(line)
Также полезно обрабатывать файлы с большими объёмами данных с помощью буферизации. В Python можно настроить размер буфера при открытии файла:
with open('file.txt', 'r', buffering=1024) as file: # Устанавливаем буфер размером 1 КБ
for line in file:
if 'искать' in line:
print(line)
Важно помнить, что такие операции могут занять много времени при работе с большими файлами, поэтому стоит оптимизировать код и использовать эффективные алгоритмы, такие как бинарный поиск для отсортированных файлов или индексация содержимого файла для быстрого поиска.
Извлечение строки по индексу с использованием списка
Для извлечения строки из файла по индексу можно использовать список в Python. Это эффективный метод, когда файл сначала загружается в память как список строк. После этого можно легко обратиться к нужной строке по индексу.
Пример простого кода:
with open('file.txt', 'r') as file:
lines = file.readlines() # Чтение всех строк в список
line_at_index = lines[5] # Извлечение строки по индексу
print(line_at_index)
Функция readlines() разделяет содержимое файла на отдельные строки и сохраняет их в список. Индексы в Python начинаются с нуля, поэтому lines[5] вернет строку, которая находится на шестой позиции в файле.
Если необходимо извлечь строку по индексу в конце файла, можно использовать отрицательные индексы, например, lines[-1] для последней строки. Это удобно при работе с большими файлами, когда важно гибко управлять порядком строк.
Однако стоит учитывать, что такой способ работает только в случае, если файл полностью помещается в память. Для больших файлов лучше использовать другие подходы, например, поочередное чтение строк с помощью цикла, чтобы избежать переполнения памяти.
Если индекс выходит за пределы списка, возникнет ошибка IndexError. Чтобы избежать этого, можно проверять длину списка перед извлечением строки:
if 0 <= index < len(lines):
print(lines[index])
else:
print("Индекс выходит за пределы диапазона.")
Такой подход делает код более безопасным и устойчивым к ошибкам при обработке различных файлов.
Обработка ошибок при работе с файлами
При работе с файлами в Python важно правильно обрабатывать возможные ошибки. Наиболее распространенные ошибки связаны с отсутствием файла, неправильными правами доступа или попытками чтения несуществующих данных. Рассмотрим основные виды ошибок и способы их обработки.
Один из ключевых элементов – это использование конструкции try-except. Это позволяет ловить и обрабатывать исключения, которые могут возникнуть при взаимодействии с файловой системой.
Пример обработки ошибки при открытии файла:
try:
with open('data.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден")
except IOError:
В этом примере мы ловим ошибку FileNotFoundError, которая возникает, если файл не существует, а также IOError, которая может быть вызвана проблемами с доступом к файлу (например, отсутствие прав на чтение).
Кроме того, стоит учитывать, что файл может быть заблокирован другим процессом или поврежден. Чтобы минимизировать риски, можно использовать дополнительные проверки перед открытием файла:
import os
if os.path.exists('data.txt'):
try:
with open('data.txt', 'r') as file:
content = file.read()
except Exception as e:
print(f"Ошибка: {e}")
else:
print("Файл не существует")
Важно помнить, что исключения должны быть обработаны таким образом, чтобы программа продолжала работать без сбоев. Следует избегать использования пустых блоков except, так как это может скрыть реальные проблемы в коде.
Еще один аспект – правильное закрытие файлов. Использование конструкции with open гарантирует автоматическое закрытие файла после выхода из блока, что помогает избежать утечек ресурсов. Однако, если вы используете open без with, следует обязательно вызывать метод close() в блоке finally:
file = None
try:
file = open('data.txt', 'r')
content = file.read()
except Exception as e:
print(f"Ошибка: {e}")
finally:
if file:
file.close()
Таким образом, правильная обработка ошибок и грамотное управление файлами не только повышают стабильность работы программы, но и минимизируют риск потери данных и ошибок в процессе их обработки.
Как извлечь строку с использованием регулярных выражений

Регулярные выражения (регэкспы) позволяют находить и извлекать строки из текста, соответствующие определенному шаблону. В Python для работы с регулярными выражениями используется модуль re.
Для извлечения строки с помощью регулярных выражений используется функция re.search() или re.findall(), в зависимости от задачи.
re.search()возвращает только первое совпадение, в то время какre.findall()находит все совпадения в строке.- Регулярное выражение описывается с помощью специального синтаксиса, например:
\d+для поиска цифр. - Для работы с группами захвата используйте круглые скобки, что позволяет извлекать части строки.
Пример поиска строки, содержащей только цифры:
import re
text = "В этом тексте 123 числа и 4567 тоже."
pattern = r'\d+'
match = re.search(pattern, text)
if match:
print(match.group())
Если необходимо извлечь все числа из текста, используйте re.findall():
matches = re.findall(pattern, text)
print(matches)
Для более сложных условий поиска можно использовать метасимволы:
\b– граница слова.^– начало строки,$– конец строки.
Пример извлечения всех слов из текста:
pattern = r'\b\w+\b'
words = re.findall(pattern, text)
print(words)
Важный момент при использовании регулярных выражений – необходимо правильно экранировать специальные символы (например, точку ., звездочку * и другие). Для этого используется обратный слэш \.
Использование регулярных выражений позволяет извлекать строки по сложным и динамичным шаблонам, что делает их мощным инструментом при работе с текстовыми данными.
Оптимизация извлечения строк из больших файлов
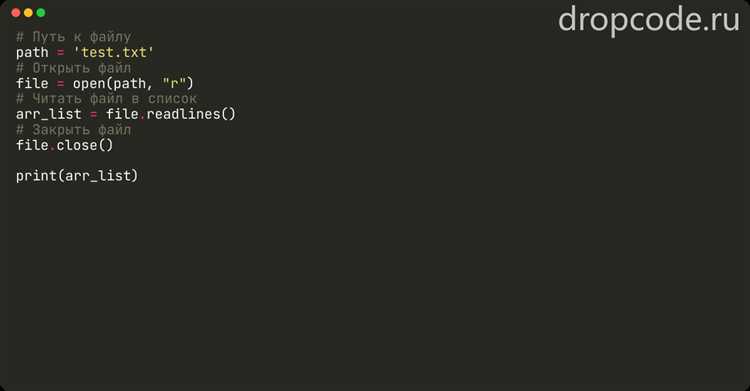
При работе с большими файлами, извлечение конкретных строк может стать узким местом в производительности. Чтобы эффективно извлекать данные из таких файлов, необходимо учитывать несколько факторов.
1. Использование буферизации
2. Индексация файлов
Для часто используемых файлов можно заранее создать индекс, который хранит позиции начала каждой строки. Это позволяет быстро находить необходимую строку без чтения всего файла. Создание индекса требует дополнительного времени на этапе подготовки, но значительно ускоряет последующие операции извлечения данных. Пример реализации: чтение файла построчно и сохранение позиций строк в отдельный индексный файл.
3. Многопоточность
Если файл большой и доступен для параллельного чтения (например, файл разбит на логические блоки), можно применить многопоточность. Использование библиотеки concurrent.futures или модулей для многозадачности (например, threading) позволяет ускорить процесс обработки файлов за счет параллельного извлечения строк из разных частей файла. Важно помнить, что эффективное использование многозадачности возможно только при условии, что файл можно разделить на независимые блоки.
4. Выбор подходящего формата файла
Формат хранения данных в файле оказывает значительное влияние на скорость извлечения строк. Например, бинарные форматы (такие как HDF5) позволяют быстрее получать доступ к данным по сравнению с текстовыми файлами. В случае с текстовыми файлами полезно использовать форматы, поддерживающие индексирование (например, CSV с заранее созданным индексом или JSON с разделением на несколько мелких файлов).
5. Минимизация операций с диском
Один из ключевых факторов – минимизация количества операций с диском. Открытие файла и закрытие его при каждом извлечении строки существенно увеличивает время выполнения. Лучше держать файл открытым на протяжении всего процесса извлечения данных. Также стоит избегать работы с дисковыми системами, имеющими низкую скорость передачи данных.
6. Алгоритмы поиска
Когда требуется извлечь строку по определенному критерию, важно выбрать правильный алгоритм. Если файл отсортирован или имеет структуру, допускающую бинарный поиск, это существенно ускоряет поиск по сравнению с простым последовательным чтением. В таких случаях можно использовать алгоритм бинарного поиска с дополнительной обработкой индекса, что снизит количество операций.
7. Использование сторонних библиотек
Существует ряд библиотек, оптимизирующих работу с большими файлами. Например, pandas предлагает высокоэффективные способы чтения больших CSV-файлов с возможностью индексации, а numpy – для работы с большими массивами данных. Использование специализированных библиотек часто позволяет повысить скорость обработки за счет использования более эффективных алгоритмов и реализации низкоуровневых операций.