Работа с таблицами данных – ключевая задача для большинства специалистов по анализу данных и разработчиков. Один из самых популярных инструментов для этих целей в Python – библиотека pandas. Она предоставляет мощные возможности для манипуляции с данными в виде структурированных таблиц, которые называются DataFrame. В этой статье мы рассмотрим, как создать таблицу в pandas с нуля и эффективно работать с данными.
Для начала, необходимо установить pandas, если она ещё не установлена в вашей среде. Это можно сделать с помощью команды pip install pandas. После этого можно приступать к созданию таблиц. Pandas поддерживает несколько способов создания объектов DataFrame – от простых списков и словарей до работы с более сложными структурами данных, такими как CSV-файлы или базы данных.
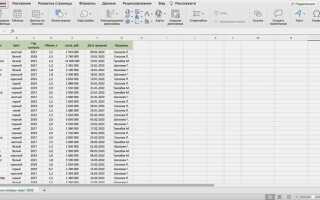
Одним из самых быстрых способов создания DataFrame является использование словаря, где ключи будут именами столбцов, а значения – списками с данными. Например, чтобы создать таблицу с данными о сотрудниках, можно использовать следующий код:
import pandas as pd
data = {
'Имя': ['Иван', 'Мария', 'Алексей'],
'Возраст': [29, 34, 22],
'Должность': ['Аналитик', 'Менеджер', 'Разработчик']
}
df = pd.DataFrame(data)
print(df)
В этом примере создаётся таблица с тремя столбцами: Имя, Возраст и Должность. Это достаточно простой, но эффективный способ для быстрой работы с данными. Такие таблицы легко фильтровать, изменять и выполнять различные операции, что делает pandas незаменимым инструментом для анализа данных.
В дальнейшем для более сложных задач можно использовать другие методы создания DataFrame, такие как загрузка данных из внешних источников (например, из CSV или Excel файлов) или конвертация других структур данных, например, из NumPy массивов или SQL-запросов. Все эти подходы обеспечивают гибкость и масштабируемость при работе с большими объёмами информации.
Установка библиотеки pandas и подготовка окружения

Для работы с библиотекой pandas необходимо установить её в вашу рабочую среду Python. Наиболее удобный способ установки – использование пакетного менеджера pip, который доступен в стандартной поставке Python.
Чтобы установить pandas, откройте командную строку или терминал и выполните следующую команду:
pip install pandas
Если вы используете Jupyter Notebook, установку можно выполнить прямо в ячейке с помощью команды:
!pip install pandas
После выполнения команды pip автоматически загрузит и установит последнюю стабильную версию библиотеки и все её зависимости. Для проверки успешности установки введите:
import pandas as pd
Если ошибок не возникло, значит установка прошла успешно.
В случае, если вы работаете с виртуальными окружениями, важно активировать нужное окружение перед установкой. Например, с помощью venv можно создать и активировать окружение так:
python -m venv myenv
source myenv/bin/activate # для Linux/macOS
myenv\Scripts\activate # для Windows
После активации окружения можно установить pandas, как было показано ранее. Это поможет избежать конфликтов с другими проектами и обеспечит совместимость с необходимыми версиями библиотек.
Если необходимо работать с определённой версией pandas, можно указать её при установке, например:
pip install pandas==1.2.3
Это гарантирует установку указанной версии, что особенно важно, если ваш проект зависит от конкретных изменений в API библиотеки.
Не забудьте периодически обновлять библиотеку до актуальной версии, чтобы использовать все последние улучшения и исправления. Для этого выполните команду:
pip install --upgrade pandas
Теперь ваша среда настроена для работы с pandas, и вы готовы к созданию таблиц и анализу данных.
Создание DataFrame из словаря в pandas

Для создания DataFrame в pandas из словаря, достаточно передать его в функцию pd.DataFrame(). Каждый ключ в словаре будет представлен как название столбца, а соответствующее значение – как данные в этом столбце. Словарь может содержать списки, кортежи, массивы NumPy или даже другие DataFrame.
Пример простого создания DataFrame:
import pandas as pd
data = {'Имя': ['Иван', 'Мария', 'Петр'], 'Возраст': [25, 30, 22]}
df = pd.DataFrame(data)
print(df)В результате будет создан DataFrame с двумя столбцами: «Имя» и «Возраст». Строки будут автоматически проиндексированы от 0 до n-1, где n – количество записей в данных.
Если вам нужно задать собственный индекс для строк, можно использовать параметр index. В качестве значений можно передать список, который будет использоваться в качестве индекса:
index_values = ['a', 'b', 'c']
df = pd.DataFrame(data, index=index_values)
print(df)Теперь строки DataFrame будут иметь индексы «a», «b» и «c». Это полезно, если вы хотите использовать специфичные метки для строк вместо стандартных числовых индексов.
При работе с DataFrame, созданным из словаря, важно помнить, что все столбцы должны иметь одинаковую длину. В случае несоответствия pandas выведет ошибку. Для решения этого можно использовать NaN для недостающих значений или привести данные к одинаковой длине перед созданием DataFrame.
Еще одной особенностью является возможность передачи вложенных словарей. В этом случае pandas автоматически создаст многоуровневую структуру колонок. Например:
data = {'Физика': {'Иван': 90, 'Мария': 85}, 'Математика': {'Иван': 80, 'Мария': 95}}
df = pd.DataFrame(data)
print(df)Этот код создаст DataFrame с мультииндексом по столбцам, где первый уровень – это название предмета, а второй уровень – это имя студента.
Как создать таблицу из списка списков в pandas
Для создания таблицы в pandas из списка списков, можно воспользоваться функцией pd.DataFrame(), которая принимает на вход двумерный список данных. Каждый вложенный список будет представлять собой строку в таблице.
Пример создания таблицы:
import pandas as pd
data = [[1, 'Alice', 25], [2, 'Bob', 30], [3, 'Charlie', 35]]
df = pd.DataFrame(data, columns=['ID', 'Name', 'Age'])
print(df)Здесь data – это список списков, где каждый внутренний список соответствует одной строке таблицы. Параметр columns задает имена столбцов, что делает таблицу более читаемой.
В результате выполнения кода будет создана таблица, в которой:
- Первая строка содержит значения: ID = 1, Name = ‘Alice’, Age = 25.
- Вторая строка: ID = 2, Name = ‘Bob’, Age = 30.
- Третья строка: ID = 3, Name = ‘Charlie’, Age = 35.
Важно помнить, что количество элементов в каждом подсписке должно быть одинаковым, иначе pandas выведет ошибку.
Если имена столбцов не указаны, pandas автоматически присвоит им числовые значения (например, 0, 1, 2…). Это может быть полезно, если вам не важны имена столбцов на начальном этапе работы.
Также можно создавать таблицы с помощью списка списков, где данные могут быть разных типов (строки, числа, даты). В pandas такие данные будут автоматически приведены к соответствующим типам, что позволяет работать с ними эффективно.
Импорт данных из CSV в pandas для создания таблицы

Для начала импортируем библиотеку pandas:
import pandas as pdОсновной синтаксис функции read_csv() следующий:
df = pd.read_csv('путь_к_файлу.csv')Здесь df – это переменная, в которую сохраняется загруженная таблица. Путь к файлу можно указать как абсолютный, так и относительный. Важно, чтобы файл CSV был доступен в указанной директории. В случае с ошибкой будет выведено сообщение об исключении.
Если файл находится в другой кодировке, например, Windows-1251, то необходимо указать параметр encoding:
df = pd.read_csv('путь_к_файлу.csv', encoding='windows-1251')Если данные разделены не запятой, а другим символом (например, точкой с запятой), можно указать разделитель с помощью параметра sep:
df = pd.read_csv('путь_к_файлу.csv', sep=';')В случае, если файл имеет лишние строки в начале или конце, которые не содержат данных, можно пропустить их, указав параметр skiprows или skipfooter для исключения строк сверху или снизу соответственно:
df = pd.read_csv('путь_к_файлу.csv', skiprows=1)Для обработки ситуаций, когда в данных могут встречаться пропуски или пустые значения, можно использовать параметр na_values, который позволяет указать, какие символы или строки следует интерпретировать как пропуски:
df = pd.read_csv('путь_к_файлу.csv', na_values=['NA', 'N/A', 'None'])Если в CSV-файле отсутствуют заголовки, можно задать их вручную с помощью параметра names:
df = pd.read_csv('путь_к_файлу.csv', names=['Колонка1', 'Колонка2', 'Колонка3'])Для ускорения процесса чтения больших файлов можно использовать параметр usecols для указания только необходимых колонок. Это особенно полезно, если в файле слишком много данных:
df = pd.read_csv('путь_к_файлу.csv', usecols=['Колонка1', 'Колонка2'])После успешного импорта данных важно проверить их целостность. Вы можете вывести первые несколько строк с помощью метода head(), чтобы убедиться, что данные загружены правильно:
print(df.head())Кроме того, pandas автоматически обрабатывает типы данных для каждой колонки, но если необходимо задать типы вручную, можно воспользоваться параметром dtypes:
df = pd.read_csv('путь_к_файлу.csv', dtype={'Колонка1': int, 'Колонка2': float})Используя эти параметры, вы сможете настроить процесс импорта данных из CSV в pandas, оптимизируя его под специфические требования вашего проекта.
Приведение типов данных в таблице pandas
В pandas типы данных в столбцах таблицы могут быть изменены с помощью метода astype(). Это важная операция, если необходимо преобразовать данные для анализа или совместимости с другими библиотеками. Например, числовые значения могут быть представлены как строки, или наоборот, строки могут быть преобразованы в даты.
Для приведения типов данных в pandas используются различные способы, в зависимости от целей. Метод astype() позволяет явно указать тип данных столбца. Пример:
df['column_name'] = df['column_name'].astype('int64')Пример выше преобразует столбец в тип int64. Важно помнить, что при этом значения должны быть совместимы с целевым типом данных. Например, строка, содержащая текст, не может быть преобразована в число, и это вызовет ошибку.
Если требуется преобразовать столбец в категориальный тип, можно использовать astype('category'). Этот тип данных помогает снизить память, если в столбце содержатся повторяющиеся значения, и ускоряет операции сравнения.
df['column_name'] = df['column_name'].astype('category')Для работы с датами чаще всего применяется тип datetime. Для преобразования строки в тип datetime можно использовать метод pd.to_datetime(), который автоматически определит формат даты. Если формат известен заранее, его можно указать явно через параметр format.
df['date_column'] = pd.to_datetime(df['date_column'], format='%Y-%m-%d')Кроме того, если нужно преобразовать значения в тип float, то можно применить astype('float64'). Однако для данных, содержащих пропуски или неправильные значения, стоит сначала применить pd.to_numeric(), который имеет параметр errors='coerce', автоматически заменяющий некорректные данные на NaN.
df['numeric_column'] = pd.to_numeric(df['numeric_column'], errors='coerce')Иногда важно привести все данные в одном столбце к единому типу, особенно при работе с большими наборами данных. Например, при объединении нескольких источников данных типы данных могут различаться, что приведет к ошибкам при обработке. В таких случаях рекомендуется сначала привести столбцы к общему типу перед выполнением операций с ними.
Приведение типов данных – это не только вопрос производительности, но и гарантии корректности выполнения операций. Важно следить за совместимостью типов данных и избегать потери информации при преобразованиях, например, преобразование строк в числа, если строка не может быть интерпретирована как число.
Как добавить новые столбцы в таблицу pandas

Добавление новых столбцов в таблицу pandas – важный и частый процесс при работе с данными. Существует несколько способов добавления столбцов, и каждый из них может быть полезен в зависимости от ситуации.
- Добавление столбца с помощью оператора присваивания: наиболее простой способ – присвоить столбцу значение. Если столбца еще нет, pandas создаст новый столбец. Если столбец уже существует, его данные будут обновлены.
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3]})
df['B'] = [4, 5, 6]
print(df)Этот код создаст новый столбец «B» с указанными значениями.
- Добавление столбца с вычисляемыми данными: можно добавить столбец, выполняя операции над существующими данными.
df['C'] = df['A'] + df['B']
print(df)Здесь столбец «C» будет содержать сумму значений из столбцов «A» и «B».
- Добавление столбца с помощью функции apply(): если требуется более сложная логика для заполнения столбца, можно использовать метод
apply(), который позволяет применять функцию ко всем строкам DataFrame.
df['D'] = df['A'].apply(lambda x: x**2)
print(df)Здесь столбец «D» будет содержать квадраты значений столбца «A».
- Добавление столбца с условием: для добавления столбца с условными значениями можно использовать конструкцию
np.where().
import numpy as np
df['E'] = np.where(df['A'] > 1, 'Yes', 'No')
print(df)Этот код создаст столбец «E», в котором будут записаны значения ‘Yes’, если значения в столбце «A» больше 1, и ‘No’ в противном случае.
- Добавление столбца с пустыми значениями: иногда бывает полезно добавить столбец с NaN значениями, например, для дальнейшей обработки данных.
df['F'] = pd.NA
print(df)Этот код создаст столбец «F» с пустыми значениями для каждой строки.
- Добавление столбца с помощью функции insert(): метод
insert()позволяет вставить столбец в определенную позицию DataFrame.
df.insert(1, 'G', [7, 8, 9])
print(df)Здесь столбец «G» будет добавлен в позицию 1, то есть сразу после столбца «A».
Каждый метод подходит для разных случаев. Выбор подходящего способа зависит от задач, которые стоят перед вами, и структуры данных, с которыми вы работаете.
Сохранение таблицы pandas в файл формата CSV
Для сохранения таблицы pandas в CSV-файл используется метод to_csv(). Это один из самых распространенных форматов для экспорта данных, который легко читается в большинстве приложений, включая Excel и текстовые редакторы.
Пример базового использования:
import pandas as pd
Создание DataFrame
df = pd.DataFrame({
'Имя': ['Алексей', 'Мария', 'Иван'],
'Возраст': [25, 30, 22],
'Город': ['Москва', 'Санкт-Петербург', 'Новосибирск']
})
Сохранение в CSV
df.to_csv('output.csv', index=False)В этом примере создается DataFrame и сохраняется в файл output.csv. Важный момент: параметр index=False исключает запись индекса в файл, что часто бывает не нужно при экспорте данных.
Дополнительные параметры метода to_csv() позволяют настроить процесс сохранения:
sep: Указывает разделитель в CSV-файле. По умолчанию используется запятая, но можно изменить на любой символ, например, точку с запятойsep=';'.header: Если не требуется записывать заголовки столбцов, можно установитьheader=False.columns: Позволяет выбрать только определенные столбцы для экспорта, указав их списокcolumns=['Имя', 'Возраст'].encoding: Можно указать кодировку файла, например,encoding='utf-8'илиencoding='utf-16', для корректного отображения символов.na_rep: Задает строку, которая будет использоваться для представления пропущенных значенийna_rep='NaN'.
Пример с дополнительными параметрами:
df.to_csv('output.csv', sep=';', index=False, header=True, encoding='utf-8', na_rep='N/A')Если нужно сохранить таблицу в несколько частей, можно использовать параметр chunksize для записи данных по частям, что полезно при работе с большими объемами данных:
df.to_csv('output_part.csv', index=False, header=True, chunksize=1000)Этот подход записывает данные по 1000 строк за раз, что уменьшает нагрузку на память и ускоряет процесс записи.
Кроме того, при сохранении данных в CSV можно указать путь к файлу, как в локальной системе, так и на удаленном сервере, если используется соответствующий механизм. Например, путь к файлу может быть сетевым или на облачном хранилище.
Таким образом, сохранение таблицы pandas в формат CSV – это простой и гибкий процесс, позволяющий эффективно экспортировать данные в стандартный формат для дальнейшего анализа или обмена информацией.
Вопрос-ответ:
Что такое DataFrame в pandas и зачем он нужен?
DataFrame в pandas — это структура данных, представляющая собой таблицу с данными. Он похож на таблицу в Excel или базу данных. В каждой строке могут быть различные значения, а в столбцах — одинаковые данные, например, числа или текст. DataFrame используется для обработки данных, их анализа и модификации.