Неразрывный пробел (символ U+00A0) часто появляется в тексте после копирования с веб-страниц, из PDF-документов или при экспорте из офисных программ. Визуально он неотличим от обычного пробела, но может вызывать ошибки при разбиении строк, поиске и обработке данных. Стандартные методы замены пробелов его не учитывают, что делает задачу менее тривиальной.
Для обнаружения и удаления таких символов в Python можно использовать явное указание символа ‘\u00A0’ или его Unicode-эквивалент в регулярных выражениях. Например, метод str.replace(‘\u00A0’, ‘ ‘) позволяет заменить все неразрывные пробелы обычными. Однако при наличии большого объема данных или сложной логики форматирования предпочтительнее использовать re.sub() с явным шаблоном символа Unicode.
Важно учитывать, что неразрывные пробелы могут встречаться в разных кодировках: при чтении файлов в cp1251 или utf-8 возможна некорректная интерпретация символов. Рекомендуется использовать utf-8 и явно обрабатывать текст как str, а не bytes, чтобы избежать искажений при замене символов.
Как определить наличие неразрывных пробелов в строке

Неразрывный пробел в Unicode обозначается символом \u00A0. Визуально он неотличим от обычного пробела (\u0020), но не участвует в переносах и может нарушать логику обработки текста. Чтобы выявить такие символы, необходимо использовать точное сравнение или регулярные выражения.
- Для прямой проверки наличия символа
\u00A0используйте выражение:'\u00A0' in строка. - Символ можно найти с помощью метода
str.find('\u00A0'). Возвращаемое значение >= 0 указывает на наличие неразрывного пробела. - Для поиска всех позиций используйте генератор:
[i for i, c in enumerate(строка) if c == '\u00A0'] - Регулярное выражение
re.search(r'\u00A0', строка)определяет наличие хотя бы одного символа. - Для подсчёта количества неразрывных пробелов:
строка.count('\u00A0').
Проверку следует выполнять на всех текстовых данных, особенно при работе с HTML, копированием из PDF и внешними источниками. Символ \u00A0 часто сохраняется при вставке текста, особенно из Microsoft Word и браузеров.
Кодовые обозначения неразрывных пробелов в Unicode и их отличие от обычных

Обычный пробел в Unicode представлен символом U+0020. Это наиболее часто используемый пробел, допускающий перенос строки и разбиение текста при автоматической верстке.
Неразрывный пробел обозначается как U+00A0 (NO-BREAK SPACE). Визуально он идентичен обычному, но не допускает разрыва строки в месте своего расположения. Он также используется для предотвращения разрыва чисел и единиц измерения, инициалов и фамилий, дат и других логических пар слов.
В текстах могут встречаться и другие виды пробелов с неразрывными свойствами. Например, U+202F (NARROW NO-BREAK SPACE) – узкий неразрывный пробел, используемый во французской типографике перед знаками препинания. Ещё один пример – U+2007 (FIGURE SPACE), который имеет ту же ширину, что и цифры, и также является неразрывным.
При обработке текста в Python необходимо учитывать все эти коды. Простая проверка на ' ' не выявит символы U+00A0 или U+202F. Для точного анализа следует использовать модуль unicodedata и проверять категорию символа или его кодовое значение явно. Рекомендуется удалять или заменять неразрывные пробелы на обычные, если они не требуются по смыслу, с помощью методов str.replace('\u00A0', ' ') и аналогичных.
Удаление неразрывных пробелов с помощью метода replace()

Неразрывный пробел в тексте представлен символом \u00A0. Этот символ визуально идентичен обычному пробелу (\u0020), но отличается семантически. В Python его можно удалить с помощью метода replace(), который заменяет указанные подстроки в строке.
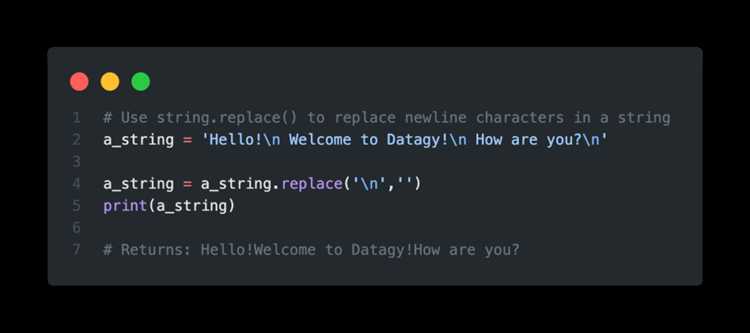
Для удаления всех неразрывных пробелов из строки необходимо вызвать метод replace(‘\u00A0’, »). Если требуется заменить их на обычные пробелы, используется replace(‘\u00A0’, ‘ ‘). Метод возвращает новую строку, исходная строка остаётся неизменной, так как строки в Python неизменяемы.
Пример замены:
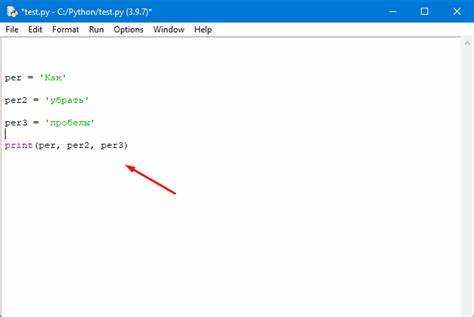
text = "Это\u00A0пример\u00A0текста"
cleaned = text.replace('\u00A0', ' ')
Метод replace() работает быстро и не требует подключения дополнительных модулей. Его следует использовать, если известна точная подстрока для замены и не требуется регулярное выражение.
Для повышения читаемости кода рекомендуется использовать символьную константу:
NBSP = '\u00A0'
text = text.replace(NBSP, ' ')
Очистка текста от неразрывных пробелов с применением регулярных выражений
Неразрывный пробел (U+00A0) визуально идентичен обычному, но мешает корректной обработке текста: нарушает разбиение на слова, влияет на выравнивание и ломает алгоритмы поиска. Для удаления таких символов удобно использовать модуль re.
Выражение re.sub(r'\xa0', ' ', text) заменяет все неразрывные пробелы на обычные. Однако, если цель – полное удаление, используйте re.sub(r'\xa0+', '', text). Это эффективно при множественных подряд идущих символах U+00A0, например, скопированных с PDF или веб-страниц.
Если необходимо сохранить структуру текста, но избавиться только от одиночных неразрывных пробелов между словами, применяйте re.sub(r'(?<=\w)\xa0(?=\w)', ' ', text). Это гарантирует, что замена произойдёт только между символами слов, не затрагивая границы предложений или разметку.
Важно учитывать кодировку входного текста. Перед применением регулярных выражений текст должен быть в Unicode-формате. При чтении из файла используйте open('file.txt', encoding='utf-8'), иначе \xa0 может не распознаваться корректно.
Для контроля результата рекомендуется использовать выражение re.findall(r'\xa0', text) – оно покажет, сколько неразрывных пробелов осталось после обработки.
Замена неразрывных пробелов на обычные пробелы при чтении из файлов
При работе с текстами, содержащими неразрывные пробелы (Unicode U+00A0), их наличие может вызывать ошибки при обработке или анализе. Чтобы заменить их на обычные пробелы сразу при чтении из файла, используйте встроенные методы Python без промежуточного хранения необработанных данных.
Пример для текстовых файлов в кодировке UTF-8:
with open("input.txt", "r", encoding="utf-8") as f:
content = f.read().replace('\u00A0', ' ')
Если файл большой, лучше читать его построчно, чтобы снизить потребление памяти:
with open("input.txt", "r", encoding="utf-8") as f:
for line in f:
cleaned_line = line.replace('\u00A0', ' ')
# дальнейшая обработка cleaned_line
Для работы с бинарными файловыми объектами, где заранее неизвестна кодировка, сначала определите её с помощью библиотеки chardet или charset-normalizer, а затем преобразуйте байты в строку с нужной заменой:
import chardet
with open("input.txt", "rb") as f:
raw = f.read()
encoding = chardet.detect(raw)['encoding']
text = raw.decode(encoding).replace('\u00A0', ' ')
Не используйте str.replace(' ', ' ') без указания Unicode-символа, так как визуально идентичный пробел может не соответствовать именно U+00A0. Убедитесь, что поиск и замена выполняются по точному коду символа.
Обработка HTML-текста с неразрывными пробелами в Python
При работе с HTML-текстом на Python часто встречаются неразрывные пробелы (HTML-сущность ), которые могут влиять на визуальное представление и структуру данных. Эти пробелы используются для предотвращения автоматического разрыва строки в местах, где это нежелательно. Однако в некоторых ситуациях необходимо удалить или заменить их, чтобы привести текст в более удобочитаемый формат для дальнейшей обработки.
Для удаления неразрывных пробелов из HTML-текста можно воспользоваться стандартными инструментами Python. Одним из самых простых методов является использование библиотеки re для работы с регулярными выражениями.
Пример кода для удаления всех неразрывных пробелов:
import re
html_text = "Этот текст содержит неразрывные пробелы."
cleaned_text = re.sub(r' ', ' ', html_text)
print(cleaned_text)
Этот код заменяет все сущности на обычные пробелы, что позволяет улучшить читаемость текста без изменений в структуре документа.
Однако, если задача заключается не только в удалении HTML-сущностей, но и в обработке общего контента HTML-документа, рекомендуется использовать библиотеки, такие как BeautifulSoup из пакета bs4. Она позволяет эффективно извлекать текст из HTML-документов и работать с ним на более высоком уровне.
Пример с использованием BeautifulSoup для удаления неразрывных пробелов:
from bs4 import BeautifulSoup
html_text = "Этот текст содержит неразрывные пробелы.
"
soup = BeautifulSoup(html_text, 'html.parser')
cleaned_text = soup.get_text().replace(' ', ' ')
print(cleaned_text)
Здесь soup.get_text() извлекает весь текст из HTML-структуры, а метод replace заменяет все неразрывные пробелы на обычные. Такой подход позволяет не только избавиться от пробелов, но и извлечь текст в чистом виде без HTML-разметки.
Для сложных HTML-документов, где могут быть другие HTML-сущности или скрытые символы, можно комбинировать использование re с BeautifulSoup, чтобы более гибко обрабатывать текст. Важно помнить, что при удалении или замене сущностей нужно учитывать контекст, чтобы не нарушить структуру документа.
Работа с неразрывными пробелами в текстах, полученных из PDF
Когда текст извлекается из PDF-документов, часто встречаются неразрывные пробелы, которые сохраняются при конвертации из формата, поддерживающего точное отображение текста, в текстовый формат. Эти пробелы могут мешать дальнейшей обработке текста, например, при парсинге или анализе данных. Поэтому важно уметь эффективно их удалять и управлять ними.
Неразрывные пробелы (код символа 0xA0 в Unicode) используются для предотвращения разрыва строки между словами, что в контексте PDF-документов часто приводит к появлению нежелательных пробелов при извлечении текста. Для работы с такими пробелами в Python можно использовать несколько методов.
Основной подход к удалению неразрывных пробелов – это замена их на обычные пробелы или удаление. Для этого удобно использовать регулярные выражения или встроенные функции Python.
- Использование метода
replace():
Для простоты, если нужно заменить все неразрывные пробелы на обычные пробелы, можно воспользоваться методомreplace()строки. Например:text = text.replace(u'\xa0', ' ')
- Использование регулярных выражений:
Регулярные выражения позволяют гибко заменять неразрывные пробелы или выполнять более сложные манипуляции с текстом. Чтобы заменить все неразрывные пробелы на обычные, можно использовать следующий код:
import re text = re.sub(u'\xa0', ' ', text)
- Удаление неразрывных пробелов:
Если цель заключается в том, чтобы полностью удалить неразрывные пробелы из текста, можно воспользоваться тем же методомreplace(), но заменить символ на пустую строку:text = text.replace(u'\xa0', '')
Однако стоит учитывать, что не всегда требуется полностью удалять или заменять все неразрывные пробелы. В некоторых случаях их сохранение важно для точного отображения оригинальной структуры текста, например, в случаях с юридическими или техническими документами. Поэтому перед применением данных методов следует тщательно анализировать, какие части текста необходимо обработать, а какие оставить без изменений.
Для автоматизации работы с текстами из PDF можно использовать библиотеку PyMuPDF (также известную как fitz). Она предоставляет функции для извлечения текста с сохранением всех особенностей форматирования, включая неразрывные пробелы, что позволяет более точно контролировать процесс обработки:
- Извлечение текста с использованием PyMuPDF:
import fitz doc = fitz.open("document.pdf") text = "" for page in doc: text += page.get_text("text")
После того, как текст извлечен, можно применять описанные методы для замены или удаления неразрывных пробелов. Важно отметить, что библиотеки для работы с PDF могут по-разному интерпретировать пробелы в зависимости от конкретной реализации и особенностей документа, что стоит учитывать при выборе подхода.
Проверка текста на наличие скрытых неразрывных символов перед анализом
Перед выполнением любых операций с текстом важно убедиться, что в нем не содержатся скрытые неразрывные пробелы (U+00A0). Эти символы могут привести к некорректному анализу, так как визуально они идентичны обычному пробелу, но в то же время могут нарушить логику работы алгоритмов, например, при разделении текста на слова.
Для начала можно использовать регулярные выражения для поиска этих символов в тексте. В Python для этого подойдёт стандартный модуль re. Регулярное выражение для поиска неразрывных пробелов будет выглядеть как \u00A0. Пример кода:
import re
text = "Пример текста с неразрывным пробелом"
if re.search(r'\u00A0', text):
print("Найдены неразрывные пробелы")
else:
print("Неразрывных пробелов нет")
Этот код эффективно обнаружит все неразрывные пробелы в строке. Если нужно заменить такие символы на обычные пробелы, это можно сделать с помощью метода re.sub():
text = re.sub(r'\u00A0', ' ', text)
Проверка текста на наличие скрытых символов полезна, если планируется работа с большими объемами данных, например, при обработке текстов из разных источников. В таких случаях часто встречаются неожиданные символы, которые могут искажать результаты анализа или обработки.
Для повышения надежности можно сочетать поиск неразрывных пробелов с другими типами контроля, например, проверкой на наличие других невидимых символов, таких как табуляции или переносы строки. Это обеспечит более качественную предварительную обработку текста перед его анализом.
Вопрос-ответ:
Что такое неразрывные пробелы и зачем их удалять в тексте?
Неразрывные пробелы — это символы, которые используются для того, чтобы два слова или знака не разделялись переносом на следующую строку. Они полезны в ситуациях, когда необходимо сохранить смысл фразы или числовые данные (например, в датах или единицах измерения). Однако в некоторых случаях, например при обработке текста, удаление таких пробелов может быть необходимо для нормализации текста, если они вызывают проблемы при его дальнейшей обработке или выводе на экран.
Каким образом можно удалить неразрывные пробелы в тексте с помощью Python?
Для удаления неразрывных пробелов в Python можно использовать метод `replace()` строки. Например, чтобы заменить все неразрывные пробелы на обычные пробелы, достаточно вызвать метод так: `text.replace('\u00A0', ' ')`. Это заменит все символы неразрывного пробела (с кодом Unicode `\u00A0`) на обычный пробел, который можно использовать без ограничений в тексте.
Можно ли удалять неразрывные пробелы только в определенных частях текста?
Да, можно. Например, если нужно заменить неразрывные пробелы только в заголовках или абзацах, можно использовать регулярные выражения. Для этого можно применить библиотеку `re` и задать нужное условие. Пример: `re.sub(r'(\u00A0)', ' ', text)` заменит неразрывные пробелы только в тех местах, которые подходят под шаблон регулярного выражения. Это даёт возможность гибко работать с текстом и удалять пробелы там, где это необходимо.
Что будет, если не удалить неразрывные пробелы в тексте?
Если не удалить неразрывные пробелы в тексте, могут возникнуть проблемы с его отображением, особенно если текст будет переноситься на несколько строк. Например, в текстовых редакторах или на веб-страницах, где важен правильный перенос текста, неразрывные пробелы могут привести к неправильному форматированию или сделать текст трудным для восприятия. Также, если такие пробелы остаются в данных, это может создать трудности при их анализе или обработке в программных приложениях.
Какие есть альтернативы для удаления неразрывных пробелов в Python?
Кроме метода `replace()`, для удаления неразрывных пробелов можно использовать другие инструменты, такие как регулярные выражения, например с помощью библиотеки `re`. Регулярные выражения позволяют гибко настраивать поиск и замену символов в тексте, что полезно, если нужно учитывать более сложные шаблоны. Также, если текст очень большой, для более эффективной работы с ним можно использовать функции библиотеки `pandas`, если данные представлены в таблице или датафрейме.
Что такое неразрывные пробелы и почему их нужно удалять в тексте на Python?
Неразрывные пробелы — это символы, которые выглядят как обычные пробелы, но не могут быть заменены переносом строки или разрывом строки. Они часто используются в текстах для того, чтобы сохранить несколько слов на одной строке, например, в случае с числами или в случаях, когда нужно, чтобы два слова не разрывались. Однако такие пробелы могут привести к неудобствам при обработке текста, например, при форматировании или при поиске и замене. Удаление неразрывных пробелов позволяет очистить текст и сделать его более удобным для дальнейшей обработки и анализа. В Python это можно сделать с помощью стандартных методов работы со строками, таких как `replace()` или регулярных выражений.