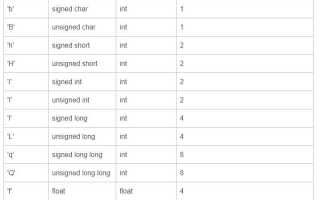
Списки в Python часто используются для хранения коллекций однотипных данных. Однако с течением выполнения программы может возникнуть необходимость удалить из списка элементы, не удовлетворяющие определённому критерию. Это может быть связано с фильтрацией данных, предварительной обработкой входных значений или оптимизацией ресурсоёмких операций.
Наиболее прямой способ – использование генератора списков: [x for x in list if условие]. Такой подход создаёт новый список, не модифицируя исходный. Это важно, если оригинальные данные ещё понадобятся. Например, чтобы удалить все отрицательные числа из списка nums, можно использовать: nums = [x for x in nums if x >= 0].
Если необходимо изменить список на месте, применяют цикл for с итерацией по копии: for x in list[:]. Иначе возможны ошибки из-за изменения длины списка во время итерации. Также стоит избегать метода remove() внутри цикла по оригинальному списку – это может привести к пропуску элементов.
Для удаления по сложным условиям удобно использовать функцию filter() с лямбда-выражением, особенно когда критерии фильтрации динамически формируются во время выполнения. Например: list(filter(lambda x: x % 2 == 0, nums)) удалит все нечётные числа.
Удаление элементов по условию – задача, к которой следует подходить осознанно, выбирая подходящий инструмент под конкретный сценарий. Ошибки в логике удаления могут привести к потере данных или некорректной работе программы.
Как удалить все элементы, равные заданному значению
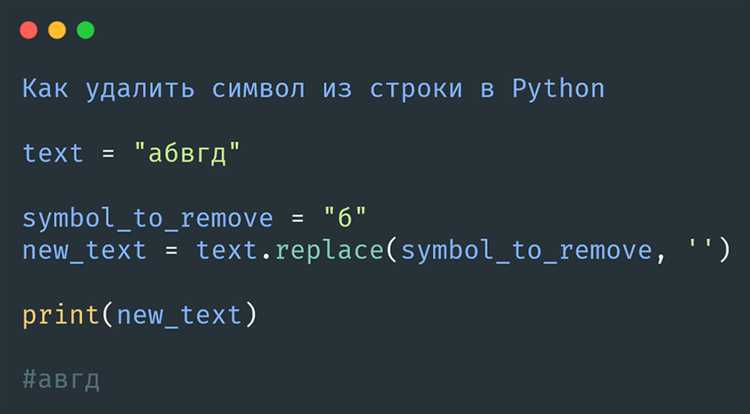
Для удаления всех вхождений заданного значения из списка применяйте генератор списков. Это позволяет создать новый список, исключив ненужные элементы:
lst = [3, 1, 2, 3, 4, 3]
target = 3
lst = [x for x in lst if x != target]
Операция не модифицирует исходный список, а создаёт новый, что обеспечивает чистоту данных и предотвращает ошибки при последующей обработке.
Если важно сохранить оригинальный объект, используйте list.clear() и list.extend() для обновления содержимого:
lst[:] = [x for x in lst if x != target]
Не используйте remove() в цикле – этот метод удаляет только первое вхождение и при последовательном вызове может привести к пропуску элементов из-за смещения индексов.
Для работы с большими списками эффективнее использовать итераторы из модуля itertools и встроенные функции фильтрации. Однако в большинстве случаев генератор списков остаётся наиболее читаемым и быстрым решением.
Удаление элементов по индексу при выполнении условия

Если необходимо удалить элементы списка по индексу, когда выполняется определённое условие, важно учитывать изменение индексов после удаления. Наиболее безопасный способ – итерация по индексам в обратном порядке.
Пример: удалить все элементы с нечётными индексами, если значение меньше нуля:
data = [3, -1, 4, -5, 9, -2]
for i in range(len(data) - 1, -1, -1):
if i % 2 == 1 and data[i] < 0:
del data[i]
print(data) # Результат: [3, -1, 4, 9]- Итерируйтесь от конца списка: это предотвращает смещение индексов при удалении.
- Используйте
range(len(...), ..., -1), чтобы не терять доступ к нужным элементам. - При сложных условиях избегайте вложенных циклов: используйте чёткие логические выражения.
При необходимости сохранить исходный список используйте генерацию нового списка с сохранением нужных индексов:
data = [3, -1, 4, -5, 9, -2]
result = [val for i, val in enumerate(data) if not (i % 2 == 1 and val < 0)]
print(result) # Результат: [3, -1, 4, 9]- Используйте
enumerateдля доступа к индексам и значениям одновременно. - Фильтрация через генераторы удобна для неизменяемых операций и упрощает отладку.
Использование list comprehension для фильтрации списка
List comprehension позволяет создавать новый список, исключая элементы, не соответствующие условию. Это особенно эффективно при работе с большими объёмами данных, где производительность имеет значение.
Для удаления элементов по условию используется синтаксис: [x for x in iterable if condition]. Например, чтобы исключить все отрицательные числа из списка: [x for x in numbers if x >= 0].
Если необходимо отфильтровать строки, содержащие подстроку, используется выражение вида: [s for s in strings if "ключ" in s]. Для удаления пустых строк: [s for s in strings if s].
Сложные условия допускаются с логическими операторами: [x for x in data if x > 10 and x % 2 == 0]. Это заменяет громоздкие конструкции с for и if, делая код короче и легче для чтения.
List comprehension можно использовать и с функциями: [x for x in values if is_valid(x)]. Это улучшает читаемость по сравнению с фильтрацией через filter() и lambda.
Для вложенных структур применяют вложенные выражения: [item for sublist in matrix for item in sublist if item != 0]. Это позволяет эффективно убирать ненужные элементы из многомерных списков.
Удаление элементов из вложенных списков по условию

При работе с вложенными списками важно учитывать, что простая фильтрация верхнего уровня не затрагивает вложенные структуры. Чтобы удалить элементы внутри вложенных списков по условию, необходимо применить вложенную итерацию и модифицировать каждый подсписок отдельно.
Рассмотрим список, содержащий подсписки с числами. Необходимо удалить все отрицательные значения:
data = [[1, -2, 3], [-5, 6, -7], [0, 8, -9]]
for i in range(len(data)):
data[i] = [x for x in data[i] if x >= 0]
После выполнения кода список data станет: [[1, 3], [6], [0, 8]].
Если вложенные списки могут содержать различные типы данных, и требуется удалить, например, все строки короче 4 символов:
data = [["cat", "dog", "elephant"], ["a", "tree", "sun"]]
for i in range(len(data)):
data[i] = [x for x in data[i] if not (isinstance(x, str) and len(x) < 4)]
Результат: [["elephant"], ["tree", "sun"]].
Удаление элементов по сложному условию (например, удалить все чётные числа, кроме тех, которые делятся на 4):
data = [[2, 4, 6, 8], [3, 12, 14]]
for i in range(len(data)):
data[i] = [x for x in data[i] if not (x % 2 == 0 and x % 4 != 0)]
Результат: [[4, 8], [3, 12]].
Рекомендуется не изменять список во время итерации по нему, особенно при удалении, чтобы избежать ошибок. Используйте генераторы списков или создавайте копии.
Удаление элементов из списка словарей по значению ключа

Предположим, у нас есть список словарей, например:
data = [
{'id': 1, 'name': 'Alice'},
{'id': 2, 'name': 'Bob'},
{'id': 3, 'name': 'Charlie'},
]
Задача – удалить все словари, где значение ключа ‘name’ равно ‘Bob’. Для этого можно применить list comprehension:
data = [item for item in data if item['name'] != 'Bob']
Этот код создаст новый список, исключая из него все элементы, где значение ключа ‘name’ равно ‘Bob’. Он не изменяет оригинальный список, а создаёт новый.
Если же нужно модифицировать исходный список непосредственно, можно использовать метод del или метод remove, но с учётом, что такие операции требуют более тщательного подхода для сохранения корректности индексов. Например, удаление с помощью метода remove или del может вызвать проблемы, если перебор списка происходит одновременно с изменением его структуры.
Пример с использованием фильтрации:
data = list(filter(lambda item: item['name'] != 'Bob', data))
Метод filter работает схоже с list comprehension, но возвращает итератор, который нужно привести к списку, как показано в примере.
Важное замечание: при удалении элементов из списка, который изменяется во время перебора, могут возникать ошибки или пропуски элементов. Чтобы избежать таких проблем, рекомендуется итерировать по копии списка или применять методы фильтрации, которые не изменяют его во время выполнения.
Такой подход позволяет гибко управлять списками словарей, обеспечивая высокую эффективность при работе с данными. Важно выбирать метод, который лучше всего соответствует конкретной задаче, особенно если работа идет с большими объёмами данных.
Удаление элементов в процессе итерации без ошибок
При удалении элементов из списка в процессе его итерации важно учесть несколько ключевых аспектов, чтобы избежать ошибок и неожиданных результатов. Итерация по списку изменяется при удалении элементов, что может привести к пропуску или дублированию элементов. Чтобы избежать этих проблем, существует несколько проверенных подходов.
Рассмотрим эффективные способы удаления элементов:
- Использование индекса с обратным проходом
Один из способов безопасно удалить элементы – это проходить по списку в обратном порядке. При этом удаление не повлияет на индексы предыдущих элементов, что позволяет избежать пропуска элементов.
list = [1, 2, 3, 4, 5] for i in range(len(list) - 1, -1, -1): if list[i] % 2 == 0: list.pop(i)
- Создание нового списка
Для того чтобы избежать изменения списка во время его обхода, можно создать новый список, добавляя в него только те элементы, которые удовлетворяют определенному условию.
list = [1, 2, 3, 4, 5] new_list = [x for x in list if x % 2 != 0]
- Использование функции filter()
Функция filter() позволяет отфильтровывать элементы списка, не изменяя его напрямую. Это безопасный и компактный способ для удаления элементов по условию.
list = [1, 2, 3, 4, 5] list = list(filter(lambda x: x % 2 != 0, list))
- Итерация с использованием копии списка
Если необходимо изменять список во время итерации, можно пройти по его копии, удаляя элементы из оригинала. Это позволит избежать ошибок, связанных с изменением списка во время его обхода.
list = [1, 2, 3, 4, 5] for item in list[:]: if item % 2 == 0: list.remove(item)
Использование копий или итераций в обратном порядке – это два простых и надежных метода для безопасного удаления элементов из списка в процессе его обхода. Эти методы позволяют избежать большинства ошибок, связанных с изменением структуры списка во время его обработки.