Python имеет широкую коллекцию встроенных типов данных, но один тип, который отсутствует в стандартной библиотеке языка, – это массивы фиксированного размера, как, например, массивы в других языках программирования, таких как C или Java. В Python списки являются динамическими, то есть могут изменять свой размер во время работы программы. Это делает их удобными, но в некоторых случаях, например, при необходимости работать с большими объемами данных или с низкоуровневыми операциями, может возникнуть потребность в типе данных, который бы имел фиксированный размер.
Отсутствие встроенного типа для фиксированных массивов не означает, что Python не поддерживает работу с массивами вообще. Для этих целей существуют внешние библиотеки, такие как NumPy, которые предоставляют массивы с фиксированным размером и высокой производительностью. Однако такие массивы не являются частью стандартной библиотеки языка и требуют дополнительных установок.
Стоит отметить, что Python предлагает множество коллекций, таких как кортежи, множества и словари, которые могут быть использованы в качестве альтернативы массивам в зависимости от задачи. Но несмотря на гибкость и удобство этих типов, все они не решают проблему фиксированного размера, что может быть критически важным в некоторых сферах, например, в обработке сигналов или изображений.
Почему в Python нет типа данных «Массив»
В Python нет встроенного типа данных «Массив», что обусловлено особенностями философии языка и подходом к структурам данных. Вместо массивов Python предлагает более универсальный тип – списки (list). Несмотря на то, что по своей структуре списки могут быть похожи на массивы из других языков, их поведение и возможности отличаются.
Главная причина отсутствия отдельного типа данных «Массив» в Python заключается в гибкости списков. В отличие от массивов в других языках, которые часто ограничены фиксированным типом элементов, списки в Python могут содержать элементы разных типов. Это позволяет работать с более разнообразными данными в одном контейнере без необходимости использования нескольких типов данных или создания сложных структур.
Кроме того, Python активно использует библиотеку NumPy для работы с массивами в числовых вычислениях. Это решение позволяет использовать массивы с фиксированными типами данных, эффективно работая с большими объемами данных. В таком случае NumPy предоставляет специализированные структуры данных, которые более оптимизированы для математических операций, чем стандартные списки.
Также стоит учитывать, что в Python списки реализованы с динамическим изменением размера, что позволяет эффективно управлять памятью без необходимости заранее определять размер контейнера, как это требуется для массивов в других языках.
Подход Python к типам данных ориентирован на удобство и гибкость, и использование списков вместо массивов подтверждает этот принцип. Если же требуется высокая производительность при работе с большими массивами данных, решение с NumPy или другими специализированными библиотеками станет более подходящим вариантом.
Чем кортеж отличается от списка, если нет «Массивов»?
Основное отличие между кортежем и списком заключается в изменяемости. Кортежи – это неизменяемые объекты, что означает, что их элементы нельзя изменять после создания. В отличие от них, списки изменяемы: можно добавлять, удалять или изменять элементы в списке. Это свойство влияет на использование этих типов в разных сценариях.
Из-за неизменяемости кортежи имеют преимущество в скорости работы, особенно при работе с большими объемами данных. Они занимают меньше памяти и быстрее обрабатываются, что делает их подходящими для хранения фиксированных данных, таких как координаты точек или элементы, которые не должны изменяться в ходе выполнения программы.
Списки же, благодаря своей гибкости, идеально подходят для ситуаций, когда нужно работать с изменяемыми коллекциями. Их можно динамически изменять в зависимости от ситуации, например, добавляя или удаляя элементы по мере необходимости.
Если рассматривать их использование в контексте отсутствия массивов, то можно отметить, что и списки, и кортежи могут использоваться для хранения коллекций данных разного типа. Однако, поскольку массивы обычно предназначены для работы с однотипными данными, в Python чаще используются списки для таких задач, а кортежи для хранения данных, которые не должны изменяться, например, констант или фиксированных конфигураций.
Кортежи также могут быть использованы в качестве ключей в словарях, что невозможно для списков, поскольку списки изменяемы и не имеют хешируемого состояния. Это делает кортежи полезными в контекстах, где необходима уникальность и неизменяемость данных.
Как решить задачи без типа данных «Массив»?

В Python нет встроенного типа данных «Массив», который существует в других языках программирования, но для решения задач с подобными требованиями можно использовать несколько альтернативных подходов.
- Списки (list) – основной инструмент для хранения коллекций данных. Они поддерживают динамическое изменение размера, могут содержать элементы разных типов и предоставляют множество встроенных методов для манипуляции данными.
- Кортежи (tuple) – упорядоченные неизменяемые коллекции. Используются, если необходимо работать с фиксированным набором элементов, которые не должны изменяться после их создания.
- Множества (set) – коллекции, содержащие уникальные элементы без порядка. Множества эффективны для решения задач, где важно избежать дублирования данных.
- Словари (dict) – удобный инструмент для хранения пар «ключ-значение». Если нужно решить задачу с ассоциативными данными, словарь будет хорошей заменой массиву.
Вместо массивов для операций с несколькими элементами можно также использовать структуры данных из стандартной библиотеки Python, такие как:
- deque из модуля collections – двусторонняя очередь, эффективно поддерживающая добавление и удаление элементов с обоих концов.
- array из модуля array – специализированный тип данных, который хранит элементы фиксированного типа и размера, аналогичный массивам в других языках. Подходит для работы с числовыми данными при необходимости оптимизации памяти.
- heapq – модуль для работы с кучей, что позволяет эффективно решать задачи сортировки и поиска минимальных/максимальных элементов.
Вместо использования массива можно комбинировать эти структуры данных в зависимости от задачи. Например, для поиска по индексам лучше всего подойдут списки или кортежи, а для решения задач с уникальными элементами – множества. Использование словарей эффективно при необходимости хранения пар значений.
Рассмотрим пример замены массива на список. Если необходимо обработать коллекцию чисел и вычислить их сумму, можно использовать обычный список:
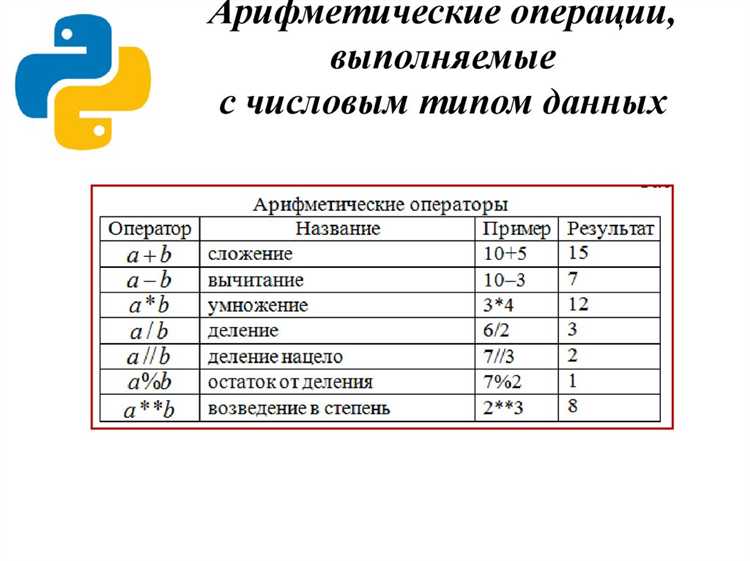
numbers = [1, 2, 3, 4, 5] sum_of_numbers = sum(numbers)
Задачи, требующие работы с большими данными или высокой производительностью, могут потребовать использования специализированных типов данных, таких как array для числовых коллекций или deque для эффективных операций добавления/удаления элементов с концов коллекции.
Почему в Python нет типа данных «Множество» с индексами?
Во-первых, главная цель множества – обеспечить быстрые операции над уникальными элементами, такие как проверка принадлежности, объединение, пересечение и разность. Для этих операций важен лишь сам факт присутствия элемента, а не его позиция в коллекции. Индексация, которая требует поддержания порядка элементов, противоречит этому принципу. Добавление индексов может снизить производительность операций с множествами, так как это потребует дополнительных усилий по отслеживанию порядка элементов.
Во-вторых, поскольку множество – это неупорядоченная коллекция, предоставление индексов на элементы нарушает основное свойство структуры. В Python множество реализовано через хеш-таблицы, что позволяет быстро находить элементы по хешу, но этот процесс не предполагает сохранение порядка элементов. Ввод индексации привел бы к необходимости хранить и обрабатывать не только сами элементы, но и их порядковые номера, что усложнило бы внутреннюю структуру данных.
Если требуется возможность индексации, вместо множества можно использовать другие типы данных, такие как списки или кортежи. Однако стоит помнить, что списки позволяют хранить дубликаты, что не соответствует принципу множества. В случае, если необходимо работать с уникальными элементами, но с индексами, можно применить комбинированные подходы, например, использовать словарь, где ключи – это уникальные элементы, а значения могут быть индексами.
Для каких задач в Python используется словарь вместо структуры данных «Хеш-таблица»?
В Python словарь (тип данных dict) и хеш-таблица имеют схожую основу: оба используют хеширование для организации данных. Однако их применения могут отличаться в зависимости от задачи и особенностей работы с данными. В отличие от чистых хеш-таблиц, словари Python предлагают дополнительные возможности, такие как порядок вставки элементов, что делает их удобными в некоторых случаях.
Словарь в Python используется, когда требуется быстрое обращение к данным по ключу с сохранением порядка элементов. Это может быть важно в случаях, когда нужно обрабатывать данные в том порядке, в котором они были добавлены в структуру, например, при анализе и сохранении логов или сборе статистики, где порядок имеет значение.
Другим отличием является поддержка различных типов данных в качестве ключей. В хеш-таблицах ключи обычно ограничиваются только хешируемыми типами данных, такими как строки, числа и кортежи. В Python словарь также использует хеширование для ключей, но позволяет использовать не только базовые типы, но и пользовательские объекты, если они реализуют методы __hash__ и __eq__.
Если задачу можно решить с использованием стандартных хеш-таблиц, но требуется поддержка более сложной логики взаимодействия с ключами или значениями, например, обработка коллизий или проверка на уникальность элементов, словарь может быть предпочтительнее за счет гибкости и интеграции с остальными инструментами Python, такими как исключения и встроенные функции.
Словарь полезен в задачах, где важно эффективно хранить и извлекать данные по ключу с минимальными затратами на память. В отличие от традиционных хеш-таблиц, которые могут использовать дополнительные структуры для разрешения коллизий, словари Python обеспечивают решение этого вопроса за счет динамического изменения размера и встроенных механизмов работы с коллизиями.
Можно ли в Python создать свой тип данных, аналогичный «Массиву»?
В Python стандартные типы данных, такие как списки, представляют собой динамические массивы. Однако, если требуется создать свой тип данных, аналогичный массиву, можно использовать возможности языка для создания собственного класса. Это особенно полезно, если необходимы специфичные операции или характеристики, не поддерживаемые стандартными типами.
Для начала, можно использовать классы, чтобы создать структуру данных, напоминающую массив. В этом случае необходимо определить методы для работы с элементами массива, такие как добавление, удаление и доступ к элементам. Пример простого массива:
class MyArray: def __init__(self, *args): self.data = list(args) def __getitem__(self, index): return self.data[index] def __setitem__(self, index, value): self.data[index] = value def append(self, value): self.data.append(value)
Этот код создает тип данных, в котором элементы хранятся в списке, и определяет основные операции, такие как доступ по индексу и добавление элементов.
Если нужна большая производительность и функциональность, можно использовать модуль array, который предоставляет массивы фиксированного типа. Однако для более гибкой работы, если важно поддержание типизации или дополнительные методы, лучше создать собственный тип данных с использованием классов. Важно учитывать, что при создании собственного типа данных нужно учитывать совместимость с другими операциями, которые стандартно поддерживаются массивами и списками Python.
При создании кастомного типа данных следует также внимательно подходить к вопросам памяти и производительности, так как стандартные типы данных в Python оптимизированы для общего использования. Массивы из стандартной библиотеки могут быть эффективнее для специфичных задач, связанных с числовыми данными.
В случае создания собственных типов данных, похожих на массивы, необходимо учитывать, что такой тип будет вести себя иначе в плане производительности и совместимости с библиотеками. Для множества приложений стандартные списки Python вполне подходят, но в некоторых случаях создание кастомного типа данных может быть полезным решением.
Как работа с коллекциями данных в Python влияет на производительность?
Выбор коллекции данных в Python оказывает прямое влияние на производительность программы. Каждый тип коллекции имеет свои особенности, которые могут либо ускорить, либо замедлить выполнение кода в зависимости от ситуации.
Список (list) – один из наиболее часто используемых типов данных. Он поддерживает быстрые операции добавления и изменения элементов в конце, но при добавлении или удалении элементов в середине или в начале списка производительность значительно падает. Это связано с необходимостью сдвига элементов.
Множество (set) и словарь (dict) оптимизированы для поиска и проверки принадлежности, что делает их эффективными для работы с уникальными элементами и для случаев, когда важна скорость проверки наличия элемента. Однако они требуют больше памяти по сравнению с другими коллекциями, поскольку используют хеширование.
Кортежи (tuple) имеют значительно меньшие накладные расходы, чем списки, поскольку они неизменяемы. Это делает их более быстрыми для операций чтения, но их невозможно изменить после создания. Они полезны, когда необходимо хранить фиксированные данные, которые не требуют модификаций.
Очередь (queue) и стек (stack) могут быть реализованы с помощью списка или deque. Использование deque, который является двусторонней очередью, позволяет избежать проблем с производительностью при добавлении и удалении элементов в начале коллекции, в отличие от списка, где такие операции требуют перемещения всех элементов.
С точки зрения памяти важно учитывать, что списки и множества требуют перераспределения памяти при добавлении элементов. Это может быть дорогостоящей операцией, особенно при больших объемах данных. Использование генераторов и итераторов помогает снизить нагрузку на память, так как они позволяют работать с данными по одному элементу, не загружая всю коллекцию в память.
Оптимальные рекомендации:
- Для частых поисков и проверок наличия используйте множества или словари.
- Когда важна неизменность данных и скорость доступа, используйте кортежи.
- Для последовательной обработки данных с минимальными накладными расходами выбирайте генераторы или итераторы.
- Использование deque вместо списка для операций на обоих концах коллекции может значительно улучшить производительность.
В результате выбор коллекции зависит от конкретной задачи, где важно учитывать не только функциональные потребности, но и требования к производительности в зависимости от типа операций с данными.
Вопрос-ответ:
Какого встроенного типа данных нет в Python?
В Python нет встроенного типа данных для работы с множествами с повторяющимися элементами. Стандартный тип данных для множеств — это set, который не допускает дублирования элементов. Если нужно работать с множествами, где элементы могут повторяться, можно использовать список (list), но для множества повторяющихся элементов в Python нет отдельного типа данных.
Почему в Python нет типа данных для множеств с повторяющимися элементами?
Python фокусируется на предоставлении простых и эффективных инструментов для обработки данных. Множества (set) по своей природе не допускают дублирования элементов, что соответствует большинству сценариев использования. Когда требуется работать с повторяющимися элементами, используют список (list), который позволяет хранить все элементы в заданном порядке, включая дубликаты. Такая структура данных более гибкая и подходит для различных задач.
Что использовать, если нужно хранить элементы с повторениями, если в Python нет типа данных для таких множеств?
Если вам нужно хранить элементы с возможными повторениями, следует использовать список (list), так как он позволяет добавлять одинаковые элементы. Однако, если вам требуется сохранить уникальные элементы и при этом знать количество каждого из них, можно использовать коллекцию Counter из модуля collections. Этот инструмент автоматически считает количество повторений элементов и позволяет эффективно работать с ними.
В Python есть тип данных, который позволяет хранить элементы с повторениями, но без их сортировки?
Да, в Python это список (list). Он не ограничивает количество одинаковых элементов, позволяя сохранить их в порядке добавления. Если же вам необходимо работать с такими коллекциями, где порядок не важен, а важна только частота элементов, используйте Counter из модуля collections. Этот тип данных поможет легко подсчитать количество повторений каждого элемента в коллекции, но сам порядок элементов не будет сохраняться.
Можно ли в Python создавать свои типы данных, аналогичные тем, которых нет в стандартной библиотеке?
Да, в Python можно создавать собственные типы данных с помощью классов. Используя классы, вы можете реализовать структуру данных, которая будет работать с повторяющимися элементами или даже с более сложными требованиями. Это позволит вам настроить поведение структуры так, как вам нужно, добавляя методы для обработки данных, их сортировки или подсчёта повторений. Пользовательские типы данных часто создаются для более специфических задач, когда стандартных решений недостаточно.
Почему в Python нет встроенного типа данных «множество с сохранением порядка»?
Python имеет встроенный тип данных «множество» (set), который является неупорядоченным. Это значит, что элементы в нем могут быть расположены в любом порядке, и этот порядок не сохраняется при добавлении или удалении элементов. В отличие от списков (list), множества не предназначены для хранения элементов в определенном порядке. Однако начиная с Python 3.7, словари (dict) начали сохранять порядок добавления элементов, что позволяет использовать их в качестве альтернативы, если нужно сохранить порядок. Важно понимать, что для множеств порядок не был задуман как важный аспект их работы, поскольку их основная цель — это быстрые операции проверки наличия элемента и выполнения операций над множествами, таких как объединение, пересечение и разность.