

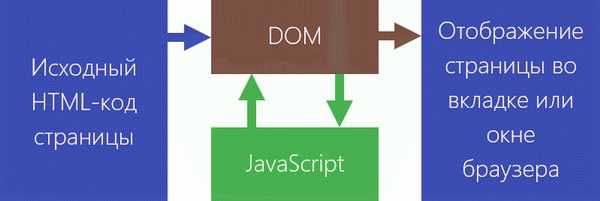
Для эффективного взаимодействия с элементами веб-страницы на уровне DOM (Document Object Model) разработчики часто сталкиваются с задачей извлечения данных из конкретных HTML-элементов. Этот процесс, как правило, используется для динамического получения информации, отображаемой пользователем, или для манипуляции содержимым страницы. Веб-разработчики используют несколько методов для получения содержимого, каждый из которых имеет свои особенности и применимость в зависимости от контекста задачи.
Один из самых распространенных методов – это использование метода innerHTML, который позволяет получить или установить HTML-содержимое элемента. Однако важно помнить, что innerHTML возвращает весь HTML-код внутри элемента, включая вложенные теги. Это может быть не всегда желаемым, особенно если нужно извлечь только текстовое содержимое. В таком случае, для получения только текста, можно использовать свойство textContent, которое возвращает текст без учета тегов.
Кроме того, существуют и более специализированные методы работы с элементами DOM, такие как getAttribute, который позволяет получить значение атрибута HTML-элемента. Например, чтобы извлечь значение атрибута src из изображения, можно воспользоваться этим методом. Такой подход позволяет более точно взаимодействовать с элементами, не меняя их внутреннего содержимого, что делает его полезным в ряде ситуаций, например, при манипуляциях с медиа-контентом.
Не стоит забывать и о методах, ориентированных на более сложные структуры, например, использование querySelector и querySelectorAll, которые позволяют получить элементы по CSS-селекторам. Эти методы дают возможность работать с элементами не только по их ID или классу, но и по любым другим признакам, что значительно расширяет возможности для извлечения данных.
Доступ к элементам с помощью document.getElementById()

Пример использования метода:
const элемент = document.getElementById("myElement");При вызове getElementById() важно учитывать, что ID должен быть уникальным в пределах страницы. Если на странице присутствует несколько элементов с одинаковыми ID, будет возвращен только первый найденный элемент. Это может привести к непредсказуемому поведению, поэтому рекомендуется избегать повторяющихся ID.
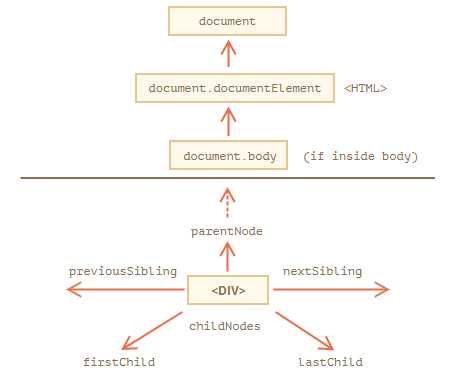
Возвращаемый объект является стандартным DOM-узлом, и с ним можно работать как с любым другим элементом: изменять содержимое, стили, добавлять обработчики событий и т.д. Для изменения содержимого элемента можно использовать свойство innerHTML или textContent, в зависимости от потребностей.
Пример изменения текста внутри элемента:
document.getElementById("myElement").textContent = "Новый текст";Кроме того, с помощью getElementById() можно изменять атрибуты элементов. Например, для изменения атрибута src у изображения:
document.getElementById("myImage").src = "newImage.jpg";Метод также используется для манипуляций с элементами формы. Например, можно получить доступ к полям ввода и их значениям:
const имя = document.getElementById("nameInput").value;Основное преимущество document.getElementById() заключается в его быстродействии, так как поиск осуществляется по уникальному идентификатору, что делает метод более эффективным по сравнению с другими способами поиска, такими как getElementsByClassName() или querySelectorAll().
Однако важно помнить, что ID должен быть уникальным для каждого элемента на странице. Нарушение этого принципа может привести к путанице и нежелательным последствиям при манипуляциях с DOM.
Использование querySelector для получения содержимого
Метод querySelector позволяет извлечь первый элемент, который соответствует заданному CSS-селектору. Это мощный инструмент для работы с DOM, который часто используется для получения содержимого элемента, включая текст или HTML.
Для того чтобы получить содержимое, нужно вызвать querySelector на объекте document или другом DOM-элементе и передать селектор в качестве аргумента. Например:
let element = document.querySelector('.example');После этого можно получить текстовое содержимое с помощью свойства textContent или innerHTML для получения HTML-кода внутри элемента.
let text = element.textContent;Если нужно извлечь HTML, а не текст, используйте innerHTML:
let htmlContent = element.innerHTML;Важно учитывать, что querySelector всегда возвращает первый найденный элемент, соответствующий селектору. Если требуется получить несколько элементов, следует использовать метод querySelectorAll.
Пример получения текста внутри первого элемента с классом message:
let message = document.querySelector('.message').textContent;Для более сложных выборок можно комбинировать селекторы. Например, для получения текста внутри div, который находится внутри элемента с классом container, используйте следующий код:
let text = document.querySelector('.container div').textContent;Метод querySelector идеально подходит для получения содержимого, если нужно работать только с одним элементом. В случае, когда необходимо получить все элементы, которые соответствуют условию, стоит использовать querySelectorAll и затем обработать коллекцию элементов.
Как работать с текстовым содержимым элемента
Для получения текстового содержимого элемента в DOM используется несколько методов, каждый из которых подходит для различных ситуаций.
- textContent – возвращает или изменяет текстовое содержимое элемента, включая текст всех его дочерних узлов. Это самый быстрый и эффективный способ, так как он не учитывает HTML-теги внутри элемента.
- innerText – возвращает текст, видимый пользователю на странице, игнорируя скрытые элементы. Также можно изменять текст, но при этом происходит перерасчет стилей, что замедляет выполнение.
- innerHTML – позволяет работать с HTML-разметкой внутри элемента. Это удобно, когда нужно получить или изменить не только текст, но и HTML-содержимое. Однако использование этого метода может быть небезопасным, если данные поступают из ненадежных источников, поскольку это открывает возможность для XSS-атак.
Для того чтобы получить текст из элемента, можно использовать следующий код:
let text = element.textContent;
Для изменения текста элемента, используйте следующий синтаксис:
element.textContent = "Новый текст";
Когда необходимо получить текст, который виден пользователю, можно использовать innerText:
let visibleText = element.innerText;
Если нужно манипулировать HTML-разметкой элемента, используйте innerHTML:
let htmlContent = element.innerHTML; element.innerHTML = "Измененный текст с тегами";
Важно помнить, что textContent и innerText могут возвращать разные значения, если внутри элемента присутствуют скрытые элементы, такие как те, что имеют стиль display: none или visibility: hidden. В этом случае textContent отобразит текст всех дочерних узлов, включая скрытые, в то время как innerText – только видимые элементы.
Для безопасной работы с внешними данными используйте textContent, чтобы избежать выполнения ненадежного кода при манипуляциях с HTML. Если же необходимо обновить HTML-разметку, следите за тем, чтобы она была проверена на безопасность.
Извлечение значений атрибутов с помощью getAttribute()
Метод getAttribute() позволяет извлекать значения атрибутов у HTML-элементов. Это важный инструмент для работы с динамическим контентом страницы, когда необходимо получить значение, присвоенное атрибуту элемента.
Применение getAttribute() является наиболее прямолинейным способом получения значения атрибута. Метод принимает один аргумент – имя атрибута, значение которого нужно извлечь. Например:
let href = document.querySelector('a').getAttribute('href');Этот код возвращает значение атрибута href первого найденного элемента <a> на странице.
Важно помнить, что метод всегда возвращает строку, независимо от типа данных атрибута. Например, если атрибут представляет собой булевое значение, как disabled, метод всё равно вернёт строку:
let disabled = document.querySelector('button').getAttribute('disabled');Если атрибут не существует, метод вернёт null.
При использовании getAttribute() стоит учитывать несколько аспектов:
- Метод работает только с атрибутами, которые были явно указаны в HTML или изменены через JavaScript.
- Для некоторых атрибутов, таких как
id,classиstyle, возможно использование специальных свойств (например,element.id,element.className,element.style), которые могут быть более удобными и оптимизированными. - Метод
getAttribute()не извлекает свойства элементов. Например, для получения текущего значения поля ввода можно использоватьinput.value, а неgetAttribute('value').
Часто getAttribute() используется в обработчиках событий для динамической работы с атрибутами. Например, если необходимо извлечь данные, связанные с элементом, для дальнейшего использования:
document.querySelector('button').addEventListener('click', function() {
let data = this.getAttribute('data-info');
console.log(data);
});В этом примере извлекается атрибут data-info, когда кнопка нажимается.
Для извлечения атрибутов, значениями которых являются URL или другие строки, getAttribute() остаётся удобным выбором, особенно при работе с динамическими элементами, созданными через JavaScript.
Чтение данных из формы с помощью form.elements
Метод form.elements предоставляет доступ к коллекции всех элементов формы. Это позволяет удобно извлекать значения полей ввода, флажков, радио-кнопок и других элементов формы без необходимости обращаться к каждому элементу по ID или name отдельно.
Каждый элемент формы имеет атрибут name, который служит в качестве ключа для его извлечения через form.elements. Например, при доступе к форме можно использовать document.forms['myForm'].elements['username'], чтобы получить поле ввода с атрибутом name="username".
Важно: коллекция form.elements является упорядоченным набором, что значит, что можно обращаться к элементам по индексу, например form.elements[0], что удобно, если нет атрибута name.
Для получения значений полей, например, текстовых полей или радио-кнопок, нужно использовать соответствующие свойства, такие как value. Пример:
let form = document.forms['myForm']; let username = form.elements['username'].value;
Для чекбоксов и радио-кнопок важно проверять состояние через свойство checked. Например, если в форме есть несколько радио-кнопок, можно получить выбранный вариант:
let gender = form.elements['gender'].value;
Для множественного выбора, например, в списке select, доступно свойство selectedOptions, которое позволяет получить все выбранные элементы:
let selectedOptions = form.elements['languages'].selectedOptions;
Рекомендация: Использование form.elements упрощает работу с большими формами, так как позволяет обрабатывать данные более гибко и без необходимости вручную искать каждый элемент по его атрибутам. Однако, важно помнить, что данные из коллекции всегда нужно извлекать в зависимости от типа элемента.
Получение содержимого через innerHTML и innerText
innerHTML возвращает или устанавливает HTML-содержимое элемента. Это свойство позволяет извлекать как текст, так и вложенные теги. Например, если у элемента есть дочерние элементы, они будут также включены в результат. Использование innerHTML подходит, когда нужно работать с тегами или извлечь весь HTML код, заключённый внутри элемента.
Пример использования innerHTML:
let content = document.getElementById('example').innerHTML;Этот код вернёт весь HTML код внутри элемента с id=»example». Будет учтён как текст, так и любые вложенные теги.
innerText возвращает или устанавливает текстовое содержимое элемента, игнорируя любые HTML-теги. Этот метод подходит, если нужно работать только с текстом и не учитывать структуру HTML.
Пример использования innerText:
let text = document.getElementById('example').innerText;Этот код вернёт только текст, который отображается в элементе, исключая любые вложенные теги.
Разница между innerHTML и innerText:
- innerHTML может содержать HTML-разметку, а innerText – только текст, что делает их полезными в разных случаях.
- innerHTML может быть использовано для манипуляции с элементами внутри контейнера, в то время как innerText ограничено только текстовым содержимым.
- Использование innerHTML может быть связано с рисками безопасности (например, при вставке пользовательского контента), в отличие от innerText, который не может выполнить вредоносный код.
Для обработки текста без выполнения HTML-кода рекомендуется использовать innerText, особенно при работе с данными, поступающими от пользователей или внешних источников.
Как обрабатывать динамически изменяющиеся элементы
Для работы с динамическими элементами DOM, которые могут быть добавлены или изменены после загрузки страницы, важно использовать подходы, которые позволяют отслеживать и взаимодействовать с элементами в реальном времени. Рассмотрим несколько ключевых методов.
Одним из самых эффективных способов является использование события MutationObserver, которое позволяет отслеживать изменения в DOM-дереве, такие как добавление, удаление или изменение атрибутов элементов. Это позволяет реагировать на изменения, происходящие после начальной загрузки страницы, без необходимости постоянно проверять состояние DOM.
Пример использования MutationObserver:
const observer = new MutationObserver((mutationsList, observer) => {
for (let mutation of mutationsList) {
if (mutation.type === 'childList') {
console.log('Добавлен или удален элемент');
} else if (mutation.type === 'attributes') {
console.log('Изменен атрибут элемента');
}
}
});
const targetNode = document.getElementById('container');
const config = { childList: true, attributes: true };
observer.observe(targetNode, config);
Важное замечание: MutationObserver не будет реагировать на изменения, произошедшие в других частях страницы или на элементы, не входящие в наблюдаемую область. Это позволяет минимизировать нагрузку на производительность, особенно при работе с большими и сложными DOM-структурами.
Другим методом является использование делегирования событий. Это особенно полезно для динамически добавляемых элементов, таких как кнопки или ссылки. Вместо того чтобы назначать обработчик для каждого нового элемента, можно повесить обработчик на родительский элемент, который уже присутствует в DOM, и реагировать на события дочерних элементов, добавленных позже.
Пример делегирования событий:
document.getElementById('parent').addEventListener('click', function(event) {
if (event.target && event.target.matches('button.classname')) {
console.log('Кнопка нажата');
}
});
Этот метод работает, даже если кнопка будет добавлена в DOM после инициализации обработчика события, что делает его удобным при работе с динамически генерируемым контентом.
Наконец, для обработки динамических изменений, связанных с временем, стоит обратить внимание на setInterval или setTimeout. Однако они должны использоваться с осторожностью, так как могут вызывать проблемы с производительностью при частых обновлениях DOM.
Пример:
setInterval(() => {
const element = document.querySelector('.dynamic-element');
if (element) {
console.log('Элемент существует');
}
}, 1000);
Важно понимать, что в случае с динамическими элементами всегда следует учитывать особенности их добавления в DOM. При неправильной настройке методов можно столкнуться с избыточной нагрузкой или ошибками при доступе к элементам, которые еще не были загружены.





