В языке Java int представляет собой примитивный тип данных, тогда как Integer является объектной оболочкой для этого типа. Это различие имеет ключевое значение при работе с коллекциями, обработкой null-значений и в контексте автобоксинга и анбоксинга.
Примитивный тип int не может содержать значение null, что делает его непригодным для ситуаций, где требуется указание отсутствия значения. Integer, как объект, может быть null, что особенно важно при работе с объектами в базе данных или JSON-сериализацией, где значение может быть необязательным.
Работа с коллекциями, такими как ArrayList, требует использования объектов, а не примитивов. Следовательно, вы не сможете добавить int в список напрямую – он автоматически преобразуется в Integer через механизм автобоксинга. Однако такое преобразование может вносить накладные расходы на производительность и создавать скрытые точки возникновения NullPointerException.
Если требуется высокая производительность, например, в циклах или при выполнении большого количества арифметических операций, предпочтительно использовать int, так как он не создает объектов и не требует дополнительной памяти. Использование Integer оправдано только тогда, когда необходима объектная природа значения, как при работе с API, требующими объектов, или при использовании функциональных интерфейсов, где требуется передача лямбда-выражений с объектами.
Осознанный выбор между int и Integer позволяет избежать ненужных аллокаций памяти, ошибок выполнения и повысить читаемость кода, особенно при проектировании доменных моделей и взаимодействии с внешними системами.
Когда использовать int, а когда Integer в параметрах методов

Тип int следует использовать в параметрах методов, когда:
- Значение обязательно и не может быть
null. - Производительность критична:
intне требует упаковки и распаковки, что снижает нагрузку на сборщик мусора. - Метод выполняется в высокочастотных циклах или в рамках алгоритмов, чувствительных к ресурсоёмкости.
- Требуется арифметика без накладных расходов: операции с
intбыстрее, чем сInteger.
Тип Integer уместен в параметрах, когда:
- Допустимо отсутствие значения:
nullпозволяет явно указать отсутствие данных. - Метод должен работать с коллекциями, такими как
List<Integer>– примитивы не поддерживаются дженериками. - Планируется использование кэширования через
Integer.valueOf(): значения от -128 до 127 будут переиспользованы из пула. - Метод является частью API, где требуется объект: например, передача значений в JavaBeans или в библиотеки, ожидающие
Object.
Выбор влияет на читаемость и устойчивость к ошибкам. Если есть сомнения – использовать int безопаснее, при условии, что null не требуется.
Автоупаковка и автораспаковка: как работают и где скрытые ловушки
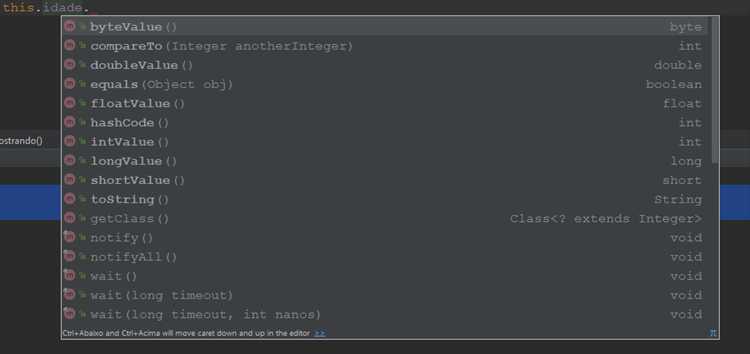
Скрытая проблема – лишние объекты. Каждый вызов new Integer() создаёт новый объект, в то время как Integer.valueOf() использует кэш значений от -128 до 127. Следовательно, Integer a = 100; и Integer b = 100; будут ссылаться на один объект, а Integer a = 200; и Integer b = 200; – на разные. Это приводит к неожиданностям при сравнении через ==: результат зависит от диапазона.
В условиях циклов и операций с коллекциями автоупаковка может резко снижать производительность. Пример: for (int i = 0; i < 1_000_000; i++) list.add(i); создаёт миллион объектов Integer, что ведёт к нагрузке на сборщик мусора и росту памяти.
Особую осторожность следует проявлять при арифметике с Integer. Выражение Integer a = 10; Integer b = 20; Integer c = a + b; на самом деле выполняет распаковку a и b в int, сложение и упаковку обратно в Integer. Это незаметно, но требует дополнительных операций и может вызвать NullPointerException, если один из операндов – null.
Рекомендации: избегать использования Integer вместо int там, где не требуется объектная обёртка; всегда использовать equals() для сравнения значений; проверять null перед автораспаковкой. Особенно критично это в API, работающих с данными из БД или внешних источников, где null – обычное явление.
Сравнение int и Integer: поведение оператора == и метода equals()

Оператор == при сравнении int и Integer сравнивает значения, но только после распаковки объекта Integer в примитив. Например, int a = 100; и Integer b = 100;: a == b вернёт true, потому что b автоматически распаковывается.
Однако при сравнении двух объектов Integer поведение == зависит от диапазона значений. Для значений от -128 до 127 используется кеширование, и ссылки указывают на один и тот же объект. Пример: Integer x = 100;, Integer y = 100;, x == y вернёт true. Но уже при Integer x = 200;, Integer y = 200;, результат x == y будет false, так как создаются разные объекты.
Метод equals() у Integer всегда сравнивает значения, а не ссылки. new Integer(200).equals(new Integer(200)) вернёт true вне зависимости от диапазона. Этот метод безопасен для любых значений и должен использоваться при сравнении объектов-обёрток.
Рекомендуется: для сравнения примитивов и обёрток – использовать ==, если известно, что один из операндов точно int; для сравнения двух Integer – использовать equals() для избежания ошибок, связанных с кешированием.
Integer как ключ в HashMap: важные особенности и подводные камни

При использовании Integer в качестве ключа важно понимать, что HashMap использует методы hashCode() и equals() для поиска значений. Метод hashCode() у Integer возвращает само числовое значение, что делает ключи предсказуемыми. Проблемы возникают, когда в коде происходит автоупаковка и распаковка типов – это может приводить к неожиданным результатам при сравнении ключей или при попытке получить значение по ключу.
Особое внимание следует уделить диапазону кэширования Integer. Значения от -128 до 127 кэшируются виртуальной машиной. Это значит, что два объекта Integer с одинаковым значением из этого диапазона будут ссылаться на один и тот же объект в памяти. Вне этого диапазона создаются новые объекты, даже если значения совпадают. Это может повлиять на производительность и поведение кода, особенно при массовом создании ключей вне кэшируемого диапазона.
Не стоит использовать new Integer(...) для создания ключей. Это приводит к созданию новых объектов, даже для одинаковых значений, и нарушает контракт equals() и hashCode() при сравнении с объектами, созданными через автоупаковку. Всегда используйте Integer.valueOf(...) или автопреобразование – они учитывают внутренний кэш.
Изменение значения Integer, использованного в качестве ключа, невозможно напрямую из-за его неизменяемости, но логическая ошибка может возникнуть при повторном использовании переменной с другим значением. Например, если переменная id была ключом в HashMap, а затем ей присвоили другое значение и попытались получить значение из Map по этому новому ключу, результатом будет null, несмотря на то, что переменная осталась та же. Это частая ошибка при использовании переменных в циклах или при динамическом формировании ключей.
Для избежания проблем: избегайте создания новых объектов Integer вне необходимости, держите ключи неизменяемыми по логике, не переиспользуйте переменные с разными значениями и используйте отладку по hashCode() и equals(), если возникают неожиданные пропуски при получении значений из HashMap.
Обработка null: что произойдёт при попытке распаковать Integer
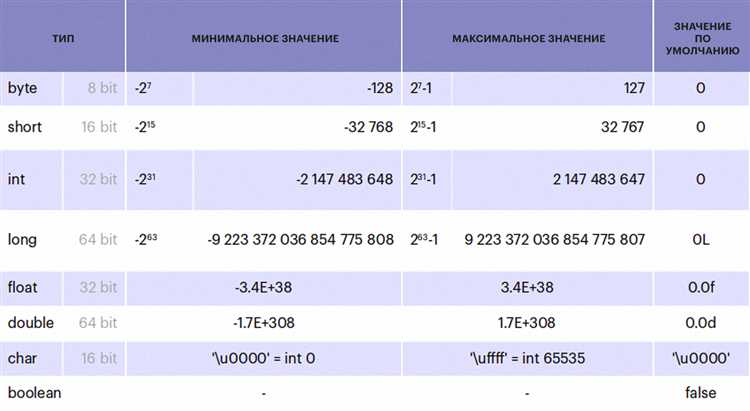
Если переменная типа Integer содержит null, попытка её распаковки в int вызывает NullPointerException. Это происходит из-за неявного вызова метода intValue() на объекте, равном null.
Например, следующий код завершится с ошибкой времени выполнения:
Integer value = null;
int result = value; // NullPointerException
JVM преобразует эту строку в:
int result = value.intValue();
Решение – явная проверка на null перед распаковкой или использование значения по умолчанию. Один из безопасных вариантов:
Integer value = null;
int result = (value != null) ? value : 0;
Альтернативно можно использовать Objects.requireNonNullElse() (начиная с Java 9):
int result = Objects.requireNonNullElse(value, 0);
Рекомендуется избегать использования null с Integer, если распаковка обязательна. Лучше применять OptionalInt или хранить значение сразу в int, если допустим 0 как отсутствие значения.
Разница в производительности при работе с большими массивами
Использование массивов типа int[] обеспечивает максимальную производительность благодаря хранению примитивных значений без оберток. Доступ к элементам осуществляется напрямую, без дополнительных затрат на распаковку. Это особенно критично при работе с массивами размером от миллиона элементов и выше, где разница в скорости может достигать десятков раз.
Массивы типа Integer[] требуют хранения ссылок на объекты, что увеличивает объем памяти примерно в 2–3 раза из-за дополнительных метаданных и выравнивания. Кроме того, при инициализации таких массивов создаются отдельные экземпляры Integer, если значения не попадают в диапазон кэширования от –128 до 127. Это приводит к повышенной нагрузке на сборщик мусора, особенно при частых операциях записи и удаления.
В циклах и алгоритмах с высокой интенсивностью доступа к элементам массивов int[] минимизируют накладные расходы. При использовании Integer[] каждый доступ вызывает автоупаковку или распаковку, что добавляет дополнительные вызовы методов и затраты на CPU. Это особенно заметно в задачах численного моделирования, обработки изображений и анализа данных, где миллисекунды критичны.
Для достижения максимальной производительности при работе с большими объемами данных рекомендуется использовать int[] или List<Integer> с предварительным выделением памяти и минимизацией автоупаковки, если объектная обертка необходима по архитектурным причинам. В остальных случаях прямое использование примитивов существенно снижает накладные расходы.
Особенности кэширования значений Integer и его влияние на сравнение

В Java объекты типа Integer кэшируются в диапазоне от -128 до 127. Это реализуется через внутренний пул значений, используемый методом Integer.valueOf(). При использовании этого метода для чисел в пределах указанного диапазона возвращаются уже существующие объекты, а не создаются новые.
Сравнение ссылок на объекты Integer с помощью оператора == даёт true только при попадании значения в кэшируемый диапазон и использовании Integer.valueOf() либо автоупаковки. Например, Integer a = 100; и Integer b = 100; дадут true при сравнении a == b. Однако Integer a = 200; и Integer b = 200; уже дадут false, поскольку создаются разные объекты вне диапазона кэширования.
Создание объекта через new Integer(…) всегда приводит к созданию нового экземпляра, независимо от значения. Это делает == непригодным для сравнения значений Integer вне кэшируемого диапазона или при явном использовании конструктора. Вместо этого следует использовать метод equals(), который корректно сравнивает значения, а не ссылки.
Рекомендуется избегать new Integer(), отдавая предпочтение автоупаковке или Integer.valueOf(), чтобы уменьшить количество создаваемых объектов и повысить производительность. При сравнении всегда использовать equals(), если необходимо сравнение по значению, особенно за пределами диапазона -128…127.
Вопрос-ответ:
Почему в Java есть и `int`, и `Integer`, разве они не одно и то же?
Нет, `int` и `Integer` — это разные вещи. `int` — это примитивный тип данных, который хранит числовое значение напрямую. `Integer` — это объект-обёртка, то есть класс, который содержит значение типа `int` внутри себя. Они используются в разных ситуациях. Например, коллекции Java, такие как `ArrayList`, не могут работать с примитивами напрямую, поэтому приходится использовать `Integer`.
Когда лучше использовать `Integer`, а не `int`?
`Integer` стоит применять, если требуется работа с объектами. Это может быть полезно при передаче значений в методы, где ожидаются объекты, или если нужно использовать null для обозначения отсутствия значения. Также `Integer` нужен, если вы работаете с дженериками, например при создании списков: `List
Есть ли разница в производительности между `int` и `Integer`?
Да, есть. `int` работает быстрее, потому что это примитив, и операции с ним выполняются напрямую. `Integer` — это объект, и с ним связаны дополнительные затраты: например, на создание объекта, упаковку (boxing) и распаковку (unboxing). В вычислениях, особенно в циклах, предпочтительнее использовать `int`, чтобы избежать лишней нагрузки на память и процессор.
Что произойдёт, если сравнивать `int` и `Integer` с помощью оператора `==`?
Если сравнивать `int` и `Integer` с помощью `==`, Java сначала автоматически преобразует объект `Integer` в примитив `int` (происходит распаковка), и потом уже сравнивает значения. То есть `int x = 5; Integer y = 5;` и `x == y` даст `true`. Однако, если сравнивать два `Integer` между собой, результат может быть неожиданным, особенно если значения выходят за пределы кэшируемого диапазона от -128 до 127. В этом случае `==` может вернуть `false`, даже если числовые значения равны. Для сравнения значений объектов `Integer` лучше использовать метод `.equals()`.