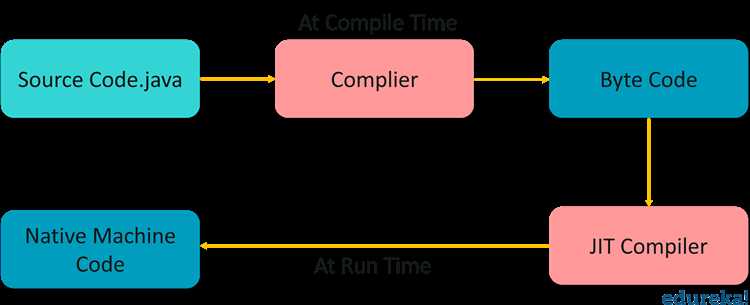
JIT-компиляция (Just-In-Time) в Java – это механизм оптимизации исполнения байт-кода JVM, активируемый в процессе выполнения программы. Вместо того чтобы интерпретировать каждую инструкцию по очереди, JIT-компилятор преобразует часто вызываемые участки байт-кода в машинный код на лету, что позволяет значительно ускорить выполнение программы.
JVM использует профилирование, чтобы определить так называемые горячие участки – методы или циклы, которые выполняются многократно. Как только код достигает определённого порога вызовов (по умолчанию 10 000 итераций для метода), JIT-компилятор (чаще всего HotSpot) инициирует его компиляцию в нативный код. Это уменьшает накладные расходы интерпретации и повышает производительность.
Существует несколько уровней JIT-компиляции: Client (C1), ориентированный на быстрое время запуска, и Server (C2), сосредоточенный на долгосрочной оптимизации. Современные JVM поддерживают гибридный подход через Tiered Compilation, позволяющий сначала использовать C1, а затем автоматически переключаться на C2 по мере накопления профилирующих данных.
JIT способен применять агрессивные оптимизации: инлайнинг методов, устранение мёртвого кода, устранение боковых эффектов, escape-анализ для размещения объектов на стеке вместо кучи. Однако эти преобразования строго зависят от профилируемой информации, и в случае недействительности предположений JIT может откатить оптимизацию, возвращаясь к интерпретации (механизм deoptimization).
Когда и почему JIT компилятор начинает свою работу
JIT-компилятор активируется во время выполнения программы, когда определённые методы достигают порога частоты вызовов. В JVM HotSpot этот порог по умолчанию составляет 10 000 интерпретируемых вызовов метода. После этого метод помечается как «горячий» и передаётся JIT-компилятору для оптимизации в машинный код.
Причина включения JIT – необходимость ускорить выполнение часто используемых фрагментов кода. В отличие от интерпретатора, который выполняет байт-код построчно, JIT генерирует высокоэффективный нативный код, минимизируя накладные расходы.
JIT также анализирует профили исполнения: сбор статистики об инлайнинге методов, предсказаниях ветвлений, частоте исключений. Это позволяет ему адаптировать сгенерированный код под реальные условия выполнения, в отличие от статической компиляции.
Существует несколько уровней JIT-компиляции в HotSpot: Client Compiler (C1) и Server Compiler (C2). C1 активируется раньше, оптимизируя методы с минимальными задержками. C2 применяется к методам, чья «горячесть» подтверждена длительным использованием. Такой двухуровневый подход позволяет сочетать скорость старта приложения и производительность на длительном интервале.
Для контроля поведения JIT-компилятора доступны JVM-флаги, например: -XX:CompileThreshold для настройки порога компиляции, -XX:+PrintCompilation для отслеживания компилируемых методов, -XX:+TieredCompilation для включения многоуровневой компиляции.
Что такое HotSpot и как он определяет «горячие» участки кода

HotSpot применяет профильное исполнение, чтобы выявить так называемые «горячие» участки – это методы или циклы, которые вызываются многократно и оказывают значительное влияние на производительность.
- Для отслеживания активности кода HotSpot использует счётчики вызовов и итераций циклов. При достижении определённого порога (например, 10 000 интерпретируемых вызовов метода) код считается «горячим».
- Интерпретатор JVM (интерпретатор C1) выполняет код и одновременно собирает статистику выполнения – частоту вызова, распределение ветвлений, инлайнинг и использование классов.
- После выхода за пороговое значение, управление передаётся JIT-компилятору C2, который компилирует этот участок байт-кода в высокооптимизированный машинный код.
HotSpot поддерживает две стратегии компиляции: клиентскую (C1) – быструю, но менее оптимизированную, и серверную (C2) – медленную, но с более агрессивными оптимизациями. При запуске с флагом -XX:+TieredCompilation используется гибридный подход, сочетающий C1 и C2 для ускоренного прогрева.
Разработчику рекомендуется использовать флаг -XX:+PrintCompilation для наблюдения за процессом JIT-компиляции, а также -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining для анализа инлайнинга, что позволяет выявить неэффективно оптимизируемые участки.
Как JIT оптимизирует байткод во время исполнения

JIT-компилятор анализирует байткод в момент исполнения и преобразует горячие участки кода в машинные инструкции. Это позволяет устранить накладные расходы интерпретации и ускорить выполнение.
Профилирование исполнения – ключевой этап. JVM отслеживает частоту вызовов методов, инлайнинг, ветвления. Как только метод считается «горячим», JIT активирует оптимизации. Например, метод, вызываемый 10 000 раз, будет скомпилирован в нативный код.
Инлайнинг методов – агрессивная оптимизация. JIT подставляет тело метода прямо в место вызова, снижая накладные расходы на стек и ускоряя переходы. Метод с небольшим телом (до 35 байт) инлайнится автоматически, если не задействует сложные конструкции.
Удаление мертвого кода применяется, если условные блоки никогда не исполняются. JIT исключает такие пути из финального нативного кода, что уменьшает объем инструкций и ускоряет выполнение.
Преобразование циклов включает в себя разворачивание и устранение лишних проверок. Например, JIT может распознать, что границы цикла инвариантны, и вынести проверку за пределы цикла.
Escape-анализ позволяет определить, выходит ли объект за границы текущего метода. Если нет – объект размещается в стеке, минуя heap и сборщик мусора. Это снижает нагрузку на GC и уменьшает паузы.
Специализация кода происходит на основе наблюдаемого поведения. Если JIT видит, что переменная всегда одного типа (например, `ArrayList`), он генерирует специализированный код без проверки типа в рантайме.
Переоптимизация и откат применяются, если поведение программы меняется. JIT может отменить ранее сгенерированный код и пересобрать его с другими допущениями. Это делает оптимизацию адаптивной к реальным условиям.
Для достижения максимального эффекта рекомендуется запускать приложение с параметрами JVM -XX:+PrintCompilation и -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining – это позволит отслеживать, какие методы JIT компилирует и как применяет инлайнинг.
Влияние инлайнинга методов на производительность

Методы, которые чаще всего инлайнит компилятор, – это короткие, часто вызываемые функции. Например, геттеры, математические операции и простые проверки. Согласно данным профилирования, инлайнинг может уменьшить общее время выполнения на 20–30% в вычислительно интенсивных задачах за счёт исключения вызовов и раскрытия дополнительных оптимизаций.
HotSpot использует эвристики, зависящие от длины байткода метода (по умолчанию 35 байт для обычных и 325 байт для горячих методов). Порог можно изменить параметрами -XX:MaxInlineSize и -XX:FreqInlineSize. Повышение этих значений может быть полезным для глубоко вложенных цепочек вызовов, но увеличивает размер скомпилированного кода и нагрузку на кэш инструкций CPU.
Важно учитывать, что чрезмерный инлайнинг может привести к эффекту code bloat, снижая общую эффективность JIT-компиляции. Рекомендуется анализировать профилировщики, такие как JFR или async-profiler, чтобы определить, какие методы реально выигрывают от инлайнинга.
Для критичных к производительности участков кода можно использовать аннотацию @ForceInline (в пакете jdk.internal.vm.annotation) в тестовых или специальных сборках, но её применение требует особой осторожности и понимания архитектуры JVM.
Как работает профилирование в JIT и зачем оно нужно

Основная цель профилирования – предоставить JIT-компилятору достаточную информацию для принятия решений об оптимизациях. Например, если метод вызывается чаще заданного порогового значения (по умолчанию 10 000 раз для клиентского компилятора C1 и 15 000 для серверного C2), он помечается как «горячий» и компилируется в машинный код с применением агрессивных оптимизаций.
Профилирование позволяет реализовывать такие техники, как инлайнинг методов, устранение виртуальных вызовов (devirtualization), предсказание ветвлений и удаление мёртвого кода. Без точных профилей компилятор не смог бы отличить критически важный путь исполнения от второстепенного, что привело бы к неэффективному машинному коду.
Важно учитывать, что профили основаны на реальных данных, характерных для текущего запуска. Это делает JIT-оптимизации чувствительными к нагрузке. Резкое изменение поведения программы может вызвать триггеринг механизма deoptimization – откат к интерпретации и перекомпиляция с новыми данными профиля.
Для анализа профилей в JVM можно использовать флаги -XX:+PrintCompilation, -XX:+UnlockDiagnosticVMOptions и -XX:+LogCompilation, а также инструменты вроде JITWatch. Это позволяет отслеживать, какие методы компилируются, какие оптимизации применяются и когда происходит деоптимизация.
Понимание профилирования в JIT позволяет разрабатывать код, который будет эффективно исполняться на HotSpot JVM. Например, упрощение полиморфизма, минимизация редких ветвлений и стабилизация типов передаваемых аргументов могут напрямую повлиять на качество JIT-оптимизаций.
Что происходит при деоптимизации и почему она важна
Деоптимизация в JIT-компиляции (Just-In-Time) происходит, когда виртуальная машина Java (JVM) принимает решение вернуть метод или участок кода к более низкому уровню оптимизации. Это может произойти по нескольким причинам: изменению условий выполнения, отклонению от предполагаемой модели поведения, неожиданному снижению производительности, а также изменению структуры данных или метаданных.
Когда JVM компилирует код, она сначала пытается его оптимизировать с учётом предполагаемых данных и исполнения. Однако, если в процессе выполнения программы оказывается, что предположения, на которых строилась оптимизация, были ошибочными, JIT может принять решение о деоптимизации, чтобы избежать дальнейших потерь в производительности. Например, если во время работы программы фактические данные или условия значительно отличаются от тех, что были использованы при первоначальной оптимизации, этот участок кода может быть деоптимизирован для большей гибкости и корректности выполнения.
При деоптимизации JVM заменяет скомпилированный код на более общий, менее оптимизированный, что позволяет избежать ошибок или чрезмерных затрат на вычисления. Однако это может привести к снижению производительности, так как более общий код может не использовать преимущества специфичных для определённых данных оптимизаций.
Деоптимизация важна, потому что она служит своего рода механизмом «обратной связи», позволяя системе динамически адаптироваться к изменениям условий работы. Это также даёт JVM возможность корректировать решения, принятые на этапе первоначальной компиляции, что критично для долгосрочной производительности приложений с непредсказуемым поведением. Важно отметить, что деоптимизация не является обычной практикой и происходит лишь в случае явных несоответствий в поведении кода.
Понимание процесса деоптимизации может помочь разработчикам лучше прогнозировать поведение программы при использовании JIT-компиляции, а также оптимизировать код для минимизации потребности в деоптимизации. Чтобы избежать частых деоптимизаций, рекомендуется тщательно анализировать горячие участки кода, применять профилирование для выявления узких мест и следить за типами данных, которые используются в критичных участках программы.
Вопрос-ответ:
Что такое JIT-компиляция в Java и как она работает?
JIT (Just-In-Time) компиляция — это технология компиляции, используемая в виртуальной машине Java (JVM). Вместо того чтобы компилировать весь код заранее (как в случае с традиционной компиляцией), JIT компиляция выполняет преобразование байт-кода в машинный код непосредственно во время выполнения программы. Это позволяет ускорить выполнение приложения, поскольку часто используемые участки кода компилируются в машинный код, что значительно повышает производительность по сравнению с интерпретацией байт-кода на каждом шаге.
Как JIT-компилятор решает, какие части кода компилировать?
JIT-компилятор выбирает для компиляции те части программы, которые выполняются наиболее часто. Этот процесс называется «горячими участками» (hot spots). JIT анализирует поведение программы во время её выполнения и на основе статистики решает, какие участки стоит компилировать в машинный код, чтобы улучшить производительность. Чем чаще используется определённый метод или участок кода, тем больше вероятность, что он будет скомпилирован для повышения скорости работы программы.
Какие преимущества предоставляет использование JIT-компиляции в Java?
Одним из основных преимуществ JIT-компиляции является повышение производительности программы. За счёт компиляции часто используемых участков кода в машинный код происходит значительное ускорение выполнения, так как виртуальная машина Java не тратит время на повторную интерпретацию байт-кода. Дополнительно JIT-компиляция позволяет адаптироваться к специфике исполнения на конкретной платформе, что также способствует улучшению работы программы. Важным аспектом является то, что компиляция происходит во время работы программы, что позволяет оптимизировать её работу в реальном времени.
Что происходит, если JIT-компилятор не успевает скомпилировать код во время выполнения программы?
Если JIT-компилятор не успевает скомпилировать код до того, как он будет выполнен, то виртуальная машина Java всё равно может выполнить байт-код, интерпретируя его. Это может снизить производительность в начале работы программы, но по мере её выполнения JIT-компилятор сможет скомпилировать самые «горячие» участки кода, что позволит ускорить дальнейшее выполнение. В некоторых случаях также используется смешанная модель, когда часть кода выполняется в интерпретированном виде, а часть компилируется, что помогает сбалансировать производительность и время компиляции.
Какие недостатки может иметь использование JIT-компиляции в Java?
Одним из недостатков использования JIT-компиляции является то, что на начальных этапах выполнения программы может наблюдаться замедление, так как компилятор должен анализировать и преобразовывать байт-код в машинный код. Также стоит отметить, что JIT-компиляция требует дополнительных ресурсов, таких как память и вычислительная мощность, для проведения анализа и компиляции кода в реальном времени. В некоторых случаях это может привести к увеличению использования системных ресурсов, что не всегда оптимально для приложений с ограниченными ресурсами или в случае, когда производительность в начальный момент времени критична.