

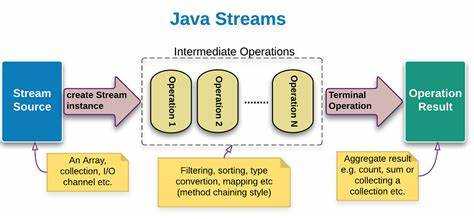
Stream API появился в Java 8 и предназначен для обработки коллекций данных с использованием функционального стиля. Потоки позволяют выполнять цепочки операций, таких как фильтрация, преобразование и агрегирование, не изменяя исходные структуры. Основное преимущество – возможность описывать вычисления декларативно, фокусируясь на логике, а не на деталях реализации.
Интерфейс Stream представляет собой последовательность элементов, над которой можно выполнять операции. Потоки бывают конечными (например, список) и бесконечными (сгенерированные функцией). После терминальной операции поток считается использованным и не подлежит повторному применению.
Важно понимать разницу между промежуточными и терминальными операциями. Первые возвращают новый поток (map, filter, sorted), вторые завершают цепочку и возвращают результат (collect, forEach, count). Все промежуточные операции выполняются лениво, только при вызове терминальной.
Рекомендуется использовать stream() для коллекций и Arrays.stream() для массивов. Для параллельной обработки доступен метод parallelStream(), но его применение оправдано только при ресурсоёмких операциях и больших объёмах данных.
Чем отличаются последовательные и параллельные стримы

Последовательный стрим обрабатывает элементы один за другим в том порядке, в котором они поступают из источника. При вызове методов stream() или Stream.of(...) создаётся именно такой поток. Он выполняется в текущем потоке без распараллеливания задач.
Параллельный стрим создаётся через parallelStream() или вызовом parallel() у обычного стрима. В этом случае элементы разбиваются на части и обрабатываются разными потоками внутри общего ForkJoinPool.commonPool(). Это даёт прирост производительности только при значительном объёме данных и ресурсоёмких операциях.
Параллельная обработка не гарантирует сохранение порядка. Если порядок важен – используйте forEachOrdered() вместо forEach(), но это снижает скорость. Также параллельные стримы плохо работают с коллекциями, у которых сложный доступ по индексам, например LinkedList.
Не рекомендуется использовать параллельные стримы для операций с побочными эффектами: запись в файл, изменение общих переменных, логгирование. Это может привести к ошибкам из-за отсутствия синхронизации.
Если требуется контролировать пул потоков, используйте Spliterator и StreamSupport с собственным ForkJoinPool. Это актуально, когда стандартный общий пул перегружен другими задачами.
Для предварительной оценки прироста производительности стоит измерять время выполнения и анализировать профилировщик. Параллельные стримы полезны только при правильной архитектуре и достаточном количестве ядер CPU.
Как применять фильтрацию и преобразование данных в стримах

Фильтрация выполняется методом filter, который принимает предикат. Элемент включается в поток, если результат предиката – true. Пример:
List<String> строки = List.of("java", "python", " ", "kotlin");
List<String> непустые = строки.stream()
.filter(s -> !s.isBlank())
.collect(Collectors.toList());Преобразование выполняется методом map, который применяет функцию к каждому элементу потока. Пример:
List<Integer> числа = List.of(1, 2, 3);
List<String> строки = числа.stream()
.map(n -> "Число: " + n)
.collect(Collectors.toList());Для вложенных коллекций используется flatMap, который разворачивает вложенные потоки. Пример:
List<List<String>> данные = List.of(
List.of("a", "b"),
List.of("c", "d")
);
List<String> результат = данные.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList());Сочетание filter и map позволяет упростить цепочку преобразований. Пример:
List<String> строки = List.of("1", "2", "три", "4");
List<Integer> числа = строки.stream()
.filter(s -> s.matches("\\d+"))
.map(Integer::parseInt)
.collect(Collectors.toList());Если нужно избежать NullPointerException, рекомендуется предварительная фильтрация:
List<String> имена = List.of("Анна", null, "Олег");
List<String> результат = имена.stream()
.filter(Objects::nonNull)
.map(String::toUpperCase)
.collect(Collectors.toList());Что происходит при ленивом выполнении операций в стримах

Ленивое выполнение означает, что промежуточные операции, такие как map, filter или distinct, не исполняются сразу. Вместо этого они накапливаются в цепочку, которая активируется только при вызове терминальной операции – forEach, collect, reduce и других.
До вызова терминальной операции стрим не выполняет ни одного действия над элементами. Это позволяет избежать ненужной обработки данных. Например, при использовании filter() и limit(1), даже при миллионе элементов, будет отфильтрован только первый подходящий, остальные игнорируются.
Каждый элемент проходит всю цепочку операций поочерёдно. То есть сначала первый элемент обрабатывается всеми функциями, затем второй и так далее. Это позволяет встроить логирование или отладку на этапе peek() и видеть точный порядок действий.
Если промежуточная операция не влияет на результат, она не будет вызвана. Например, если после filter() идёт sorted(), но limit() ограничивает выбор до одного элемента, сортировка применяется только к тем, что прошли фильтр до лимита.
При проектировании цепочек важно располагать наиболее селективные операции раньше, чтобы сократить объём обрабатываемых данных. Например, filter() должен предшествовать map(), если фильтрация может отсечь большую часть потока.
Избегай промежуточных операций с побочными эффектами, особенно в map() и filter(). Они не гарантируют порядок вызовов, особенно в параллельных стримах, и могут не выполняться, если не будет терминальной операции.
Когда стоит использовать метод collect и как он работает

Метод collect применяется для преобразования элементов Stream в другую форму – список, множество, карту, строку или агрегированное значение. Он завершает потоковую операцию, возвращая результат, пригодный для дальнейшей работы вне Stream API.
Использование collect оправдано в следующих случаях:
- Необходимо сохранить элементы потока в коллекцию –
List,Set,Map. - Требуется агрегировать данные – подсчитать, сгруппировать, объединить.
- Нужно получить результат в произвольной структуре с помощью собственного Collector-а.
Метод имеет сигнатуру <R,A> R collect(Collector<? super T,A,R> collector). Он принимает объект типа Collector, который определяет:
- supplier – начальное значение аккумулятора (например,
ArrayList::new). - accumulator – функция добавления элемента (например,
List::add). - combiner – объединение частичных результатов в параллельных потоках.
- finisher – преобразование аккумулятора в конечный результат.
На практике чаще всего используют фабричные методы из класса Collectors:
Collectors.toList()– собирает элементы вList.Collectors.toSet()– вSet.Collectors.toMap()– вMapпо ключу и значению.Collectors.joining()– объединяет строки.Collectors.groupingBy()– группирует по ключу.Collectors.partitioningBy()– разделяет на две группы по предикату.
Пример: сбор строк длиной больше 3 в список:
List<String> result = list.stream()
.filter(s -> s.length() > 3)
.collect(Collectors.toList());Для сложных задач можно создавать свои Collector-ы через Collector.of.
Как избежать распространённых ошибок при использовании Stream API
Не используйте стримы для изменения внешнего состояния. Методы внутри цепочек должны быть чистыми и не влиять на переменные вне потока. Например, попытка накапливать значения в списке через forEach ведёт к некорректному поведению в многопоточном окружении.
Избегайте повторного использования одного и того же стрима. Поток можно использовать только один раз, после терминальной операции он закрывается. Чтобы переиспользовать источник данных, нужно создать новый стрим.
Не вставляйте операции с побочными эффектами внутрь map, filter или peek. Это нарушает декларативный стиль API и затрудняет отладку. Метод peek допускается исключительно для отладки и логирования.
Не применяйте parallelStream() без анализа структуры данных и цели обработки. Параллельные потоки дают выигрыш только при большом объёме независимых задач и наличии достаточного числа процессорных ядер. Для коротких коллекций или I/O-операций это может привести к деградации производительности.
Избегайте излишнего создания стримов в циклах. Например, вызов stream() внутри for по другому списку создаёт избыточную нагрузку. Используйте flatMap для объединения вложенных структур без промежуточных циклов.
Не забывайте про терминальные операции. Поток без вызова collect, forEach, count и других завершает работу без выполнения промежуточных шагов.
Старайтесь не использовать Collectors.toList() или toSet() без необходимости. Если нужен специфический тип коллекции (например, LinkedHashSet), задавайте его явно через Collectors.toCollection.
Не используйте стримы, когда требуется простой проход по коллекции. Например, простой фильтр или подсчёт суммы проще и быстрее реализуются с помощью классического цикла, особенно при критичных требованиях к производительности.
Зачем и как использовать собственные коллекторы

Собственные коллекторы в Java Stream API позволяют гибко управлять процессом агрегации данных. Когда стандартные коллекторы не удовлетворяют требованиям, создаются собственные, которые могут оптимизировать производительность или обеспечить специфическую логику обработки данных.
Коллектор представляет собой объект, реализующий интерфейс Collector, который отвечает за накопление элементов потока в результирующую коллекцию или структуру. Для создания собственного коллектора важно понимать три ключевых этапа: инициализация, накопление и завершение.
Инициализация начинается с создания начального состояния, которое будет использовано для накопления данных. Например, можно использовать ArrayList::new для создания списка или StringBuilder::new для строк. Это состояние создается в методе supplier() коллектора.
Накопление данных выполняется методом accumulator(), который принимает промежуточное состояние и элемент потока. Здесь можно выполнить необходимые преобразования или фильтрации. Например, можно фильтровать данные или изменять их перед добавлением в коллекцию.

 (пока оценок нет)
(пока оценок нет)



