Поиск ошибок в строках кода – неотъемлемая часть работы программиста. В Java, как и в других языках, ошибки могут возникать в самых разных формах: от синтаксических до логических и проблем с производительностью. Однако, несмотря на разнообразие типов ошибок, существуют проверенные методы для эффективного их нахождения и устранения.
Первый шаг – это понимание природы ошибки. Java компилятор может указать на точное место, где произошла ошибка, но важно понимать контекст. Если ошибка синтаксическая, например, неправильное использование оператора или забытный символ, то её обычно легко выявить с помощью средств разработки, таких как IntelliJ IDEA или Eclipse. Но когда речь идет о логической ошибке, которая не вызывает ошибок компиляции, приходится искать её вручную, исследуя логику работы программы.
Также полезно составить план поиска ошибки. Начните с проверки тех частей кода, которые недавно были изменены, поскольку большинство ошибок часто возникает именно после внесения правок. Использование unit-тестов поможет локализовать проблемы на ранней стадии, даже до того, как программа будет запущена в полной версии.
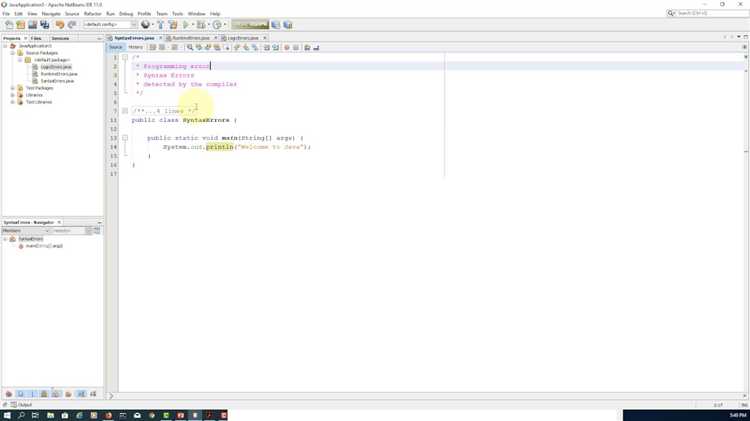
Поиск синтаксических ошибок с помощью компилятора
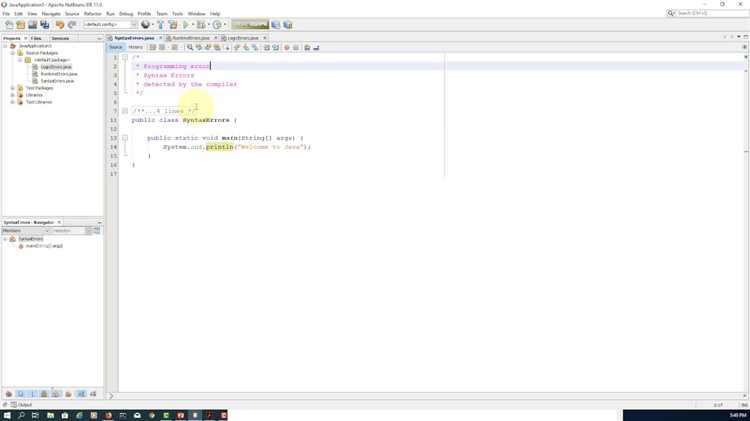
При компиляции Java программы компилятор анализирует каждую строку кода, проверяя синтаксис на соответствие стандартам языка. Ошибки синтаксиса обычно связаны с отсутствием или неправильным расположением элементов, таких как скобки, точки с запятой, операторы или ключевые слова. Это критично, поскольку даже небольшие несоответствия могут нарушить выполнение программы.
Понимание сообщений об ошибках
Когда компилятор обнаруживает ошибку, он генерирует сообщение, которое включает в себя строку с указанием местоположения ошибки и описание проблемы. Например, если забыта закрывающая скобка, компилятор может вывести сообщение, указывающее на строку с ошибкой и с пояснением, что необходимо добавить закрывающую скобку. Важно точно следовать этим рекомендациям и внимательно проверять указанный участок кода.
Использование IDE для улучшения поиска ошибок
Интегрированные среды разработки (IDE), такие как IntelliJ IDEA или Eclipse, могут значительно ускорить процесс нахождения синтаксических ошибок. Эти инструменты не только отображают сообщения компилятора, но и подчеркивают строки с ошибками, показывая визуальные подсказки. Это помогает быстрее понять, где именно возникла проблема и какие элементы кода требуют корректировки.
Пример ошибки и рекомендация по исправлению
Если в коде присутствует забытая точка с запятой, компилятор может выдать сообщение вроде «Expected ‘;’». Это означает, что в указанной строке не завершен оператор. Для исправления ошибки достаточно добавить точку с запятой в нужное место.
Важно, что компилятор сообщает о первой обнаруженной синтаксической ошибке, но могут быть и другие ошибки в других частях кода, которые появятся только после исправления предыдущих. Поэтому следует корректировать ошибки по очереди, начиная с первых, указанных компилятором.
Использование отладчика для пошагового выполнения кода
Основной принцип работы отладчика заключается в установке так называемых точек останова (breakpoints), которые приостанавливают выполнение программы в определённой точке. Это позволяет разработчику наблюдать изменения переменных, отслеживать поток выполнения и изучать стек вызовов.
Для использования отладчика в IDE, например, в IntelliJ IDEA или Eclipse, достаточно установить точку останова, кликнув по левому полю строки с кодом. После этого можно запустить программу в режиме отладки. При достижении точки останова выполнение будет приостановлено, и появится возможность шагать по коду.
Основные шаги пошагового выполнения включают:
- Шаг в (Step Into) – выполняет текущую строку и заходит внутрь вызываемой функции, позволяя анализировать её выполнение.
- Шаг через (Step Over) – выполняет текущую строку, но пропускает вызовы методов, не заходя внутрь.
- Шаг выхода (Step Out) – завершает выполнение текущей функции и возвращает к предыдущей строке.
- Продолжить (Continue) – возобновляет выполнение программы до следующей точки останова.
Кроме того, отладчик позволяет изменять значения переменных в процессе выполнения, что полезно для проверки различных гипотез о поведении программы. Этот подход позволяет исключить множество ошибок на ранних этапах разработки.
Важно помнить, что отладка требует внимательности и последовательности. Использование отладчика не только помогает найти ошибки, но и способствует лучшему пониманию структуры программы и взаимодействия её частей.
Проверка типов данных и несовпадений в операторах
Чтобы избежать таких ошибок, важно строго следить за типами переменных при их использовании в операторах. Например, если пытаемся выполнить операцию деления целочисленных значений, результатом будет целое число, даже если делитель не делится нацело. Это может вызвать потерю точности, если ожидался результат с плавающей запятой.
Для устранения ошибок типизации рекомендуется использовать явное приведение типов, если необходимо выполнить операцию с переменными разных типов. Пример:
int a = 5; double b = 2.0; double result = a / b; // Приведение типа int к double
Однако нужно быть осторожным с операциями, при которых происходит автоматическое приведение типов. Java может не выполнить приведение, если это приведет к потере данных. Например, при попытке присвоить значение типа long переменной типа int произойдет ошибка компиляции:
long largeValue = 1000000000; int smallValue = largeValue; // Ошибка: incompatible types
Для исправления такой ошибки нужно использовать явное приведение типов:
int smallValue = (int) largeValue; // Приведение типа long к int
Еще один тип ошибок связан с несовпадением типов в логических операторах. Например, попытка выполнить операцию сравнения с несовместимыми типами данных, такими как int и String, приведет к ошибке компиляции:
int number = 10; String text = "10"; boolean isEqual = number == text; // Ошибка: incompatible types
Для корректного выполнения такой операции необходимо привести один из операндов к нужному типу, например:
boolean isEqual = Integer.toString(number).equals(text); // Приведение int к String
При работе с операциями сравнения следует учитывать, что для числовых типов, таких как int, double, float, правильный выбор оператора важен. Например, при сравнении значений типа double следует учитывать погрешности, вызванные особенностями представления чисел с плавающей запятой в памяти компьютера. Вместо оператора «==» рекомендуется использовать методы сравнения с точностью до заданной погрешности:
double x = 0.1 + 0.2;
double y = 0.3;
if (Math.abs(x - y) < 1e-9) {
// значения считаются равными
}
Ошибки типов могут также возникать при работе с коллекциями. Например, попытка добавить элемент другого типа в коллекцию, типизированную для определенного класса, приведет к ошибке времени выполнения. Чтобы избежать этого, всегда следует проверять типы элементов перед их добавлением в коллекцию:
Listnumbers = new ArrayList<>(); numbers.add(10); numbers.add("string"); // Ошибка времени выполнения
Кроме того, при использовании оператора instanceof важно правильно проверять тип объектов. Неверное использование instanceof может привести к неожиданным результатам, особенно в случае сложных иерархий классов:
Object obj = new Integer(5);
if (obj instanceof String) { // Ошибка: объект не является экземпляром String
System.out.println("String");
}
Таким образом, важно внимательно подходить к проверке типов данных в Java. Недооценка этих аспектов может привести к различным ошибкам, которые не всегда очевидны при компиляции, но проявляются в процессе выполнения программы. Регулярное использование явного приведения типов, проверок на null и правильной работы с операторами поможет избежать большинства проблем, связанных с типами данных.
Анализ логов и сообщений об ошибках в консоли
При анализе сообщений об ошибках стоит не только смотреть на тип исключения, но и проверять, какие методы и классы указаны в стеке вызовов. Это помогает сузить область поиска ошибки. Например, если ошибка появляется в методе `parseInt()` из класса `Integer`, возможно, строка, переданная в метод, не может быть преобразована в целое число. Важно учитывать возможные неправильные данные, передаваемые в методы.
Для поиска проблем в многозадачных приложениях полезно использовать логи с метками времени и уровнями логирования (например, DEBUG, INFO, WARN, ERROR). Это позволяет отслеживать порядок выполнения кода и определить, где именно возникает сбой в потоке исполнения.
При разработке и тестировании полезно добавлять собственные сообщения в лог, чтобы лучше понять, какие участки программы были выполнены перед возникновением ошибки. Это поможет быстрее найти и устранить проблему, особенно если ошибка возникает не всегда, а только при определенных условиях.
Наконец, важно не игнорировать предупреждения в логах. Ошибки типа `WARN` могут быть предвестниками более серьезных проблем в будущем, и своевременное обращение на них помогает избежать сложных сбоев в работе приложения.
Поиск ошибок, связанных с многозадачностью и потоками
Ошибки, возникающие в многозадачных приложениях Java, часто трудно выявить из-за особенности работы потоков. Основные проблемы включают состояния гонки, мертвые блокировки, а также неправильную синхронизацию. На этапе разработки важно не только избегать этих ошибок, но и правильно их диагностировать, чтобы минимизировать их влияние на производительность и корректность программы.
Состояния гонки – это одна из распространенных ошибок при работе с потоками. Они происходят, когда два или более потока одновременно изменяют одни и те же данные, что приводит к непредсказуемому поведению. Для выявления состояний гонки используйте инструменты, такие как Thread.dumpStack() и профилировщики, например, VisualVM или YourKit. Эти инструменты помогут вам отследить, какие потоки взаимодействуют с общими ресурсами.
Чтобы избежать состояний гонки, применяйте синхронизацию. Используйте synchronized блоки или атомарные классы из пакета java.util.concurrent. Например, AtomicInteger или ReentrantLock обеспечат безопасное изменение переменных, доступных нескольким потокам.
Мертвые блокировки происходят, когда два или более потока ждут освобождения ресурсов, заблокированных друг другом, что приводит к остановке программы. Для диагностики мертвых блокировок можно использовать ThreadMXBean и методы, такие как findDeadlockedThreads(). Это позволяет зафиксировать момент, когда потоки блокируются друг другом.
Чтобы избежать мертвых блокировок, следуйте рекомендациям по проектированию, таким как всегда блокировать ресурсы в одном и том же порядке и использовать тайм-ауты при ожидании блокировок. В случае с ReentrantLock используйте метод tryLock(), чтобы избежать зависания программы.
Неэффективное использование потоков может привести к снижению производительности. Например, создание слишком большого количества потоков может вызвать чрезмерную нагрузку на процессор. В таких случаях стоит использовать ExecutorService для управления пулом потоков. Этот подход не только упрощает управление потоками, но и улучшает производительность за счет повторного использования существующих потоков.
Для выявления подобных ошибок можно использовать профилировщики, которые отслеживают загрузку процессора и использование памяти каждым потоком. Они позволяют визуализировать потоки, выявлять узкие места и оптимизировать многозадачность.
Ошибки синхронизации возникают, когда потоки обращаются к разделяемым данным без должной синхронизации. Часто это приводит к некорректным результатам и сбоям. Для диагностики можно использовать Thread.sleep() для имитации задержек и проверки поведения системы в различных состояниях синхронизации.
Правильное использование синхронизации и атомарных операций значительно уменьшает вероятность таких ошибок. Обратите внимание на volatile переменные и CountDownLatch для правильного контроля порядка выполнения потоков.
Использование статического анализа кода и IDE для обнаружения ошибок
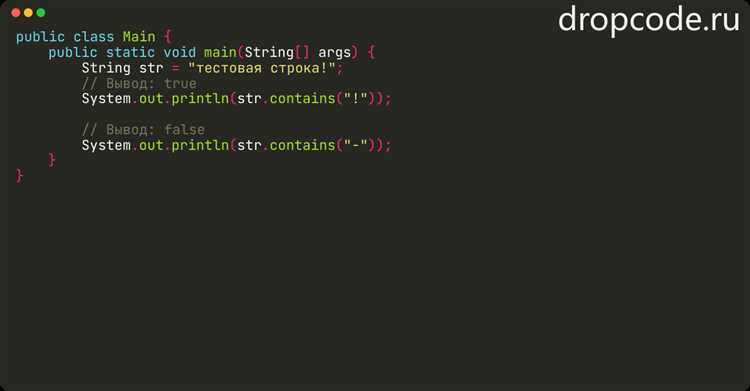
Для эффективного использования статического анализа и IDE в Java разработке важно учитывать следующие аспекты:
- Интеграция с IDE: Большинство современных IDE, таких как IntelliJ IDEA, Eclipse или NetBeans, имеют встроенные инструменты для статического анализа. Эти инструменты анализируют код в реальном времени и немедленно подсказывают о возможных ошибках или недостатках. Например, IntelliJ IDEA автоматически подчеркивает ошибки синтаксиса, предупреждает о неиспользуемых переменных и методах.
- Использование плагинов: Для более глубокого анализа можно подключать плагины, такие как CheckStyle, PMD или FindBugs. Эти инструменты анализируют код с разных точек зрения: от соблюдения стандартов кодирования до выявления потенциальных проблем с производительностью или безопасностью.
- Конфигурация правил анализа: Важно настроить инструменты статического анализа с учетом специфики проекта. Например, можно задать правила для проверки стиля кодирования, обработки исключений, использования многозадачности и других аспектов. Правильная настройка поможет получить точные результаты и избежать ложных срабатываний.
Некоторые из наиболее полезных возможностей статического анализа в IDE:
- Подсветка синтаксических ошибок: Ошибки в синтаксисе могут быть обнаружены уже на этапе набора кода. IDE подскажет вам, если вы забыли точку с запятой или неправильно закрыли фигурные скобки.
- Предупреждения о возможных исключениях: IDE может предупреждать о потенциальных исключениях, которые могут быть выброшены в случае неправильной обработки ошибок, например, NullPointerException или IOException.
- Выявление неиспользуемого кода: Некоторые инструменты автоматически сообщают о неиспользуемых переменных, методах или классах, что помогает поддерживать код чистым и удобным для поддержки.
- Анализ сложности кода: Многие инструменты статического анализа анализируют сложность алгоритмов и структуру кода. Это помогает выявить участки, которые могут быть трудными для понимания или поддержания.
Кроме того, статический анализ можно интегрировать с системами непрерывной интеграции (CI). Это позволяет автоматически проверять код на наличие ошибок при каждом коммите и на стадии сборки проекта. В результате разработчики получают быстрые отзывы о проблемах, которые можно исправить до того, как код попадет в основную ветку проекта.
Для повышения эффективности статического анализа полезно сочетать его с другими методами тестирования, такими как юнит-тесты и динамическое тестирование. Статический анализ выявляет ошибки, которые невозможно обнаружить простым запуском программы, например, неправильное использование API или потенциальные утечки памяти.
Для серьезных проектов рекомендуется настроить автоматические правила для анализа кода с использованием статического анализатора при каждом коммите. Это помогает поддерживать высокий уровень качества и предотвращать распространение ошибок в проекте.
Вопрос-ответ:
Как найти ошибку в строках кода Java, если программа не компилируется?
Когда код не компилируется, первым делом нужно внимательно прочитать сообщение об ошибке, которое дает компилятор. Это поможет определить, в каком месте возникает ошибка. Часто проблемы связаны с синтаксическими ошибками, такими как пропущенные скобки, точка с запятой в конце строки или неправильный порядок слов в выражении. Также стоит проверить правильность импорта классов и наличие необходимых библиотек. Если ошибка касается типа данных, то необходимо убедиться, что используемые переменные и методы соответствуют ожидаемым типам.
Что делать, если программа в Java выполняется, но работает неправильно?
Когда программа выполняется, но результат неверный, следует начать с анализа логики кода. Важно проверить, правильно ли реализованы все условия и циклы, а также не пропущены ли важные шаги в алгоритме. Подходя к исправлению ошибок, полезно использовать отладчик (debugger), чтобы пошагово просматривать выполнение программы и видеть значения переменных на каждом шаге. Также можно вставить выводы в консоль с текущими значениями переменных, чтобы понять, на каком этапе программа начинает вести себя не так, как ожидалось.
Какие инструменты помогают искать ошибки в коде на Java?
Для поиска ошибок в коде Java существует несколько инструментов, которые значительно упрощают этот процесс. В первую очередь, это IDE (интегрированные среды разработки), такие как IntelliJ IDEA или Eclipse, которые предлагают подсветку синтаксиса, автодополнение и исправление ошибок. Также полезен статический анализатор кода, например, SonarQube, который помогает обнаруживать потенциальные проблемы, такие как неправильные названия переменных, неиспользуемые участки кода или ошибки в логике. Для выявления ошибок в логике можно использовать юнит-тесты, с помощью которых можно проверить корректность работы отдельных частей программы.
Почему в Java может возникнуть ошибка "NullPointerException" и как с ней бороться?
"NullPointerException" возникает, когда программа пытается использовать объект, который не был инициализирован (т.е. равен null). Чтобы избежать этой ошибки, нужно всегда проверять, что объект не равен null перед тем, как вызвать его методы или обратиться к его полям. Можно использовать условные операторы для проверки null или воспользоваться инструментами, которые поддерживают обработку таких случаев, например, Optional из библиотеки Java 8. Еще один способ – использовать аннотации, такие как @NonNull и @Nullable, для явного указания, какие переменные могут быть null, а какие нет.
Как исправить ошибку компиляции в Java, если появляется сообщение о "неправильном типе данных"?
Ошибка "неправильный тип данных" часто возникает, когда вы пытаетесь присвоить переменной значение, которое не соответствует ее типу. Например, если вы пытаетесь записать строку в переменную целочисленного типа, то компилятор выдаст ошибку. Чтобы исправить такую ошибку, необходимо проверить, что типы данных правильно согласованы в операции или присваивании. Если вы хотите преобразовать один тип в другой, используйте соответствующие методы преобразования типов, такие как parseInt для строковых значений, которые нужно преобразовать в числа. Важно также обратить внимание на использование оберток типов (например, Integer вместо int), если работа ведется с объектами.