Библиотека requests предоставляет простой способ отправки HTTP-запросов и обработки ответов. Для загрузки изображений с удалённых серверов достаточно выполнить GET-запрос и сохранить содержимое ответа в файл. Это особенно актуально при автоматизации сбора данных, создании скрейперов и работе с API, возвращающими изображения.
Для начала необходимо убедиться, что сервер возвращает корректный код ответа: 200 OK. Использовать следует метод requests.get() с параметром stream=True, чтобы избежать загрузки содержимого в память целиком. Это снижает нагрузку при работе с большими файлами.
Пример базового кода:
import requests
url = "https://example.com/image.jpg"
response = requests.get(url, stream=True)
if response.status_code == 200:
with open("image.jpg", "wb") as file:
for chunk in response.iter_content(1024):
file.write(chunk)
Важно использовать iter_content() с указанием размера блока, чтобы избежать ошибок при передаче больших файлов и повысить стабильность загрузки. Также рекомендуется проверять заголовок Content-Type перед сохранением, чтобы убедиться, что полученный ресурс действительно является изображением:
if "image" in response.headers["Content-Type"]:Эти шаги обеспечивают надёжную загрузку изображений без использования сторонних библиотек. Для более сложных сценариев – например, обработки редиректов или авторизации – также можно использовать параметры allow_redirects, headers и auth в запросе.
Как скачать одно изображение по URL и сохранить его на диск
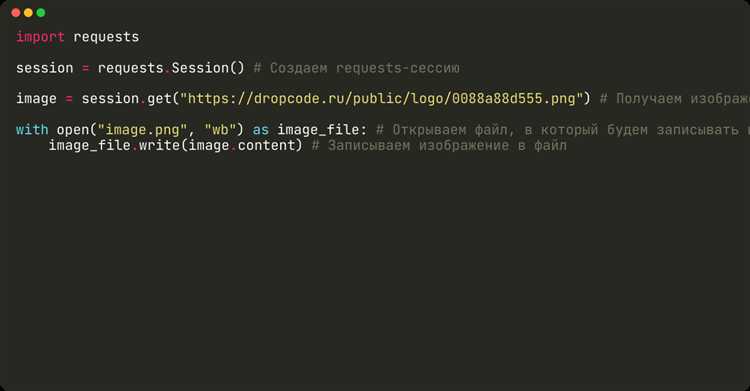
Для загрузки изображения по URL используется метод get из библиотеки requests с параметром stream=True, чтобы избежать загрузки всего файла в память сразу.
Пример:
import requests
url = 'https://example.com/image.jpg'
path = 'image.jpg'
response = requests.get(url, stream=True)
if response.status_code == 200:
with open(path, 'wb') as file:
for chunk in response.iter_content(1024):
file.write(chunk)
else:
print(f'Ошибка: статус {response.status_code}')
Параметр stream=True позволяет обрабатывать содержимое по частям, что важно для крупных файлов. Метод iter_content гарантирует контроль над размером буфера, здесь он установлен в 1024 байта.
Перед сохранением стоит проверить статус ответа: 200 означает успешную загрузку. Файл открывается в бинарном режиме 'wb', поскольку изображение представляет собой двоичные данные. Путь 'image.jpg' можно заменить на абсолютный или относительный, в зависимости от нужного каталога сохранения.
Если URL ведёт на нестабильный источник, рекомендуется обернуть запрос в блок try-except для обработки исключений, таких как requests.exceptions.RequestException.
Как задать пользовательский User-Agent при скачивании
Браузеры и большинство HTTP-клиентов отправляют заголовок User-Agent, чтобы идентифицировать себя серверу. Некоторые сайты блокируют запросы с пустым или подозрительным значением этого заголовка. Чтобы задать собственный User-Agent в библиотеке requests, необходимо явно указать его в параметре headers.
Пример корректного использования:
import requests
url = "https://example.com/image.jpg"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/123.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
with open("image.jpg", "wb") as f:
f.write(response.content)
Значение User-Agent можно скопировать из браузера, открыв инструменты разработчика и перейдя на вкладку «Network». Лучше использовать строку, имитирующую реальный браузер, чтобы избежать блокировки.
Если нужно часто использовать одинаковый User-Agent, можно создать сессию:
session = requests.Session()
session.headers.update({"User-Agent": "Ваш User-Agent"})
response = session.get(url)
Некоторые сайты проверяют соответствие User-Agent и других заголовков, таких как Accept или Referer. Если сервер возвращает ошибку 403 или пустой ответ, имеет смысл задать дополнительные заголовки.
Обработка ошибок: что делать при недоступности изображения

Если сервер возвращает ошибку или изображение не удаётся получить, необходимо анализировать статус ответа и обрабатывать исключения. Использование try-except блоков и проверка response.status_code позволяет избежать сбоев выполнения скрипта.
- Проверяйте код ответа:
200означает успех,404– файл не найден,403– доступ запрещён,500+– ошибка на сервере. - Обрабатывайте исключения
requests.exceptions.RequestException, включая тайм-ауты и ошибки соединения. - Устанавливайте тайм-аут через параметр
timeoutвrequests.get(), чтобы скрипт не зависал при долгом ожидании ответа. - Используйте повторные попытки при временных сбоях. Модуль
urllib3.util.retryили библиотекаtenacityпозволяет реализовать контролируемый повтор. - Логируйте URL с ошибками и статусами для последующего анализа. Это поможет выявить закономерности сбоев.
- При сохранении файла проверяйте, не является ли ответ HTML-страницей с ошибкой, а не изображением. Например, по заголовку
Content-Type.
Пример проверки и обработки:
import requests
from requests.exceptions import RequestException
def download_image(url, path):
try:
response = requests.get(url, timeout=5)
if response.status_code == 200 and 'image' in response.headers.get('Content-Type', ''):
with open(path, 'wb') as f:
f.write(response.content)
else:
print(f'Ошибка: код {response.status_code}, тип контента {response.headers.get("Content-Type")}')
except RequestException as e:
print(f'Сбой запроса: {e}')
Скачивание изображений с сайта по списку URL из файла
Создайте текстовый файл, например urls.txt, где каждая строка содержит прямую ссылку на изображение. Пример содержимого:
https://example.com/image1.jpg
https://example.com/image2.png
Для загрузки используйте библиотеку requests и встроенные средства Python:
import requests
import os
output_dir = "downloaded_images"
os.makedirs(output_dir, exist_ok=True)
with open("urls.txt", "r") as file:
urls = [line.strip() for line in file if line.strip()]
for i, url in enumerate(urls, 1):
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
ext = os.path.splitext(url)[1] or ".jpg"
filename = f"image_{i}{ext}"
path = os.path.join(output_dir, filename)
with open(path, "wb") as img_file:
img_file.write(response.content)
except requests.RequestException as e:
print(f"Ошибка при загрузке {url}: {e}")
Убедитесь, что ссылки ведут напрямую к файлам. Если URL генерируются скриптом, понадобится предварительный анализ HTML или использование BeautifulSoup.
Рекомендуется ограничивать количество одновременных запросов при большом числе URL, используя time.sleep() или concurrent.futures с контролем потока.
Скачивание и сохранение изображений в потоковом режиме
Для загрузки изображений большого размера или при нестабильном соединении рекомендуется использовать потоковый режим передачи данных. Это позволяет считывать файл частями, не загружая его полностью в оперативную память.
- Импортируйте необходимые модули:
import requests - Установите заголовки (опционально), если сервер требует их:
headers = {'User-Agent': 'Mozilla/5.0'} - Откройте поток запроса с параметром
stream=True:response = requests.get(url, headers=headers, stream=True) - Проверьте статус ответа:
if response.status_code == 200: - Откройте файл в бинарном режиме и записывайте данные по частям:
with open('image.jpg', 'wb') as f: for chunk in response.iter_content(chunk_size=8192): if chunk: f.write(chunk)
Используйте chunk_size кратный 4096 или 8192. Это оптимально для большинства сетей и накопителей. Условие if chunk исключает пустые фрагменты, которые иногда могут встречаться при нестабильной передаче.
Не забудьте закрыть соединение вручную, если используете нестандартные методы работы с потоком:
response.close()Для исключения повреждённых файлов добавляйте проверку типа контента:
if 'image' not in response.headers.get('Content-Type', ''):
raise ValueError('URL не содержит изображение')
Как получить имя файла изображения из HTTP-заголовков
Для извлечения имени файла изображения можно использовать заголовок Content-Disposition, который часто содержит информацию о файле при его загрузке с сервера. Чтобы получить это имя, необходимо отправить запрос на сервер и проанализировать ответ.
Пример кода на Python с использованием библиотеки requests:
import requests
url = 'https://example.com/image.jpg'
response = requests.get(url, stream=True)
# Получаем значение заголовка Content-Disposition
content_disposition = response.headers.get('Content-Disposition')
# Если заголовок присутствует, извлекаем имя файла
if content_disposition:
filename = content_disposition.split('filename=')[1].strip('"')
else:
# Если заголовок отсутствует, можно взять имя файла из URL
filename = url.split('/')[-1]
print(filename)1. Если заголовок Content-Disposition присутствует, его значение будет содержать имя файла, которое можно извлечь с помощью метода split.
2. В случае отсутствия заголовка можно использовать последний сегмент URL как имя файла.
Это решение подходит для большинства случаев, но стоит учитывать, что некоторые серверы могут не предоставлять заголовок Content-Disposition. В таких случаях, если важно получить правильное имя файла, стоит использовать дополнительные проверки или парсинг URL.