Для решения задачи подсчета количества букв в слове на Python можно использовать несколько простых и эффективных методов. Основной принцип заключается в том, чтобы правильно обработать строку и посчитать количество символов, удовлетворяющих условиям задачи. В Python это можно сделать буквально в несколько строк кода, и для большинства случаев достаточно стандартных инструментов языка.
Первый и самый простой способ – воспользоваться встроенной функцией len(). Эта функция возвращает длину строки, то есть количество всех символов, включая пробелы, знаки препинания и буквы. Однако, если нужно посчитать только буквы, следует использовать дополнительные методы фильтрации символов.
Для фильтрации букв можно использовать генераторы или функции filter() и isalpha(), которые проверяют, является ли символ буквой. Например, используя комбинацию этих методов, можно быстро подсчитать только алфавитные символы в строке. Такой подход позволяет избежать лишних вычислений, когда в строке присутствуют цифры или знаки препинания.
Практический пример: если перед вами стоит задача подсчитать количество букв в строке, содержащей как буквы, так и другие символы, можно написать небольшой скрипт, который будет обрабатывать строку поэтапно, фильтруя ненужные символы. В этом случае алгоритм будет эффективным и простым, позволяя получить точный результат за минимальное время.
Как использовать функцию len() для подсчета символов

Функция len() в Python позволяет быстро узнать количество символов в строке. Она возвращает целое число, равное количеству символов, включая пробелы, знаки препинания и специальные символы. Чтобы использовать len(), достаточно передать строку как аргумент.
Пример использования:
word = "Пример"
print(len(word)) # Результат: 6В данном примере функция возвращает число 6, так как слово «Пример» состоит из 6 символов. Стоит отметить, что len() учитывает все символы, включая пробелы. Например, если строка будет содержать пробелы, их тоже посчитают:
sentence = "Пример с пробелами"
print(len(sentence)) # Результат: 18Результат в данном случае – 18, потому что пробелы между словами также считаются символами.
len() работает с любыми строками, включая строки с символами Юникода. Например:
emoji_string = "😊👍"
print(len(emoji_string)) # Результат: 2В данном случае функция вернет 2, так как в строке два символа (эмодзи), несмотря на то, что они могут занимать больше байтов в памяти.
Важно помнить, что len() не может быть использована для подсчета символов в других типах данных, таких как числа или списки, без предварительного преобразования этих типов в строку.
Пример для числа:
num = 12345
print(len(str(num))) # Результат: 5Таким образом, len() – это удобный инструмент для подсчета символов в строках, который учитывает все элементы, включая пробелы и специальные знаки, и позволяет работать с различными типами данных, преобразуя их в строковый формат.
Как исключить пробелы при подсчете букв в слове

Для более эффективного подхода можно использовать метод join() в сочетании с генераторами списка, чтобы удалить пробелы из строки и одновременно подсчитать количество символов. Пример кода:
word = "пример текста с пробелами"
clean_word = "".join(word.split())
letter_count = len(clean_word)
print(letter_count)Здесь split() делит строку на список слов по пробелам, а join() объединяет их обратно в строку без пробелов. После этого достаточно применить функцию len() для подсчета букв.
Также можно использовать регулярные выражения с модулем re, чтобы удалить все пробелы за один шаг:
import re
word = "пример текста с пробелами"
clean_word = re.sub(r"\s+", "", word)
letter_count = len(clean_word)
print(letter_count)Регулярное выражение \s+ находит все пробельные символы, включая пробелы, табуляции и новые строки, и заменяет их на пустую строку, что исключает их из подсчета.
Подсчет количества букв в строке с учетом регистра
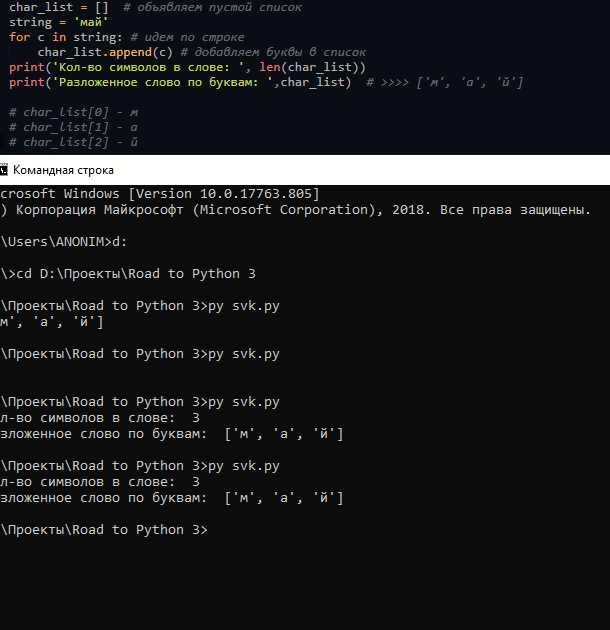
При подсчете букв в строке на Python важно учитывать, как прописные, так и строчные символы. Это может быть полезно, если нужно провести точную статистику по каждому символу, включая различия между большими и маленькими буквами.
Для этого можно воспользоваться встроенными методами языка, такими как count(), который позволяет подсчитывать количество конкретных символов, учитывая регистр. Рассмотрим пример:
text = "Python и python"
count_upper = text.count('P')
count_lower = text.count('p')
В данном примере count_upper вернет количество заглавных букв «P», а count_lower – строчных букв «p». Это позволяет разделить подсчет по регистрационным различиям.
Если требуется посчитать все буквы в строке с учетом регистра, можно воспользоваться методом filter() в сочетании с функцией isalpha(), чтобы исключить неалфавитные символы. Например:
text = "Python и python!"
letters = list(filter(str.isalpha, text))
count = len(letters)
Этот код создает список, состоящий только из букв, игнорируя пробелы и знаки препинания, и затем считает количество элементов в списке.
Также можно использовать collections.Counter для подсчета частоты появления каждой буквы с учетом регистра:
from collections import Counter
text = "Python и python"
counter = Counter(text)
print(counter)
Этот способ возвращает объект, в котором ключами являются символы строки, а значениями – их частота. С помощью этого можно легко подсчитать, сколько раз появляется каждая буква, учитывая ее регистр.
Важно помнить, что строковые методы Python чувствительны к регистру. Если необходимо игнорировать его, следует преобразовать строку в один регистр (например, через lower() или upper()).
Как посчитать количество конкретных букв в слове
Для того чтобы посчитать количество конкретных букв в слове на Python, можно использовать встроенные методы строк. Рассмотрим несколько способов решения этой задачи.
Метод count() является самым простым и эффективным способом подсчета количества вхождений символа в строку. Он возвращает целое число, равное числу повторений буквы в слове. Например:
слово = "программирование"
буква = "р"
результат = слово.count(буква)
print(результат) # Выведет 3Этот метод удобен, если вам нужно посчитать одну конкретную букву. Если необходимо посчитать несколько букв, можно использовать цикл.
Цикл для подсчета нескольких букв можно реализовать, перебирая все символы слова. Например, чтобы посчитать, сколько раз встречаются буквы «р» и «м», используйте следующий код:
слово = "программирование"
буквы = ["р", "м"]
результаты = {буква: слово.count(буква) for буква in буквы}
print(результаты) # Выведет {'р': 3, 'м': 2}Этот способ удобен, если вы хотите посчитать вхождения нескольких букв одновременно, но для большого количества букв он может быть не таким эффективным, как другие методы.
Метод collections.Counter() из стандартной библиотеки Python предоставляет более универсальный способ подсчета символов. Он создает объект, который хранит количество каждого символа в строке. Например:
from collections import Counter
слово = "программирование"
счётчик = Counter(слово)
print(счётчик['р']) # Выведет 3Этот подход позволяет не только посчитать количество букв, но и сразу получить частотный анализ всех символов в слове. Также, если вам нужно посчитать несколько букв, можно использовать методы get() или доступ к элементам через ключи:
счётчик = Counter(слово)
результаты = {буква: счётчик.get(буква, 0) for буква in ["р", "м"]}
print(результаты) # Выведет {'р': 3, 'м': 2}Выбор метода зависит от вашего конкретного случая. Если нужно просто подсчитать одну букву, count() – это самый простой и быстрый вариант. Для подсчета нескольких букв с использованием Counter() можно получить не только результаты, но и частотную таблицу для дальнейшего анализа. Метод с циклом и count() подойдёт для небольших слов, но для более сложных задач с большими объемами данных лучше использовать Counter().
Использование регулярных выражений для подсчета букв
Регулярные выражения (regex) позволяют эффективно работать с текстовыми данными, включая подсчет букв в словах. Вместо того чтобы вручную перебирать символы строки, регулярное выражение предоставляет удобный способ выделить только те символы, которые соответствуют определенному паттерну. В Python для работы с регулярными выражениями используется модуль re.
Для подсчета букв в строке можно использовать регулярное выражение, которое ищет все символы, являющиеся буквами. Пример такого выражения: [a-zA-Z], которое соответствует любому символу латинского алфавита в верхнем или нижнем регистре.
Рассмотрим пример, как использовать регулярные выражения для подсчета букв в слове:
import re
# Текст, в котором будем искать буквы
text = "Привет, мир 123!"
# Регулярное выражение для поиска всех букв
pattern = r'[a-zA-Zа-яА-Я]'
# Использование re.findall для поиска всех букв в тексте
letters = re.findall(pattern, text)
# Подсчет количества букв
count = len(letters)
print(f"Количество букв в слове: {count}")
В приведенном примере мы используем регулярное выражение [a-zA-Zа-яА-Я], которое включает как латинские, так и кириллические буквы. Функция re.findall() находит все символы, соответствующие этому выражению, и возвращает их список. Затем мы просто подсчитываем количество элементов в этом списке.
Важно отметить, что регулярные выражения могут быть настроены под любые специфические требования, например, если необходимо исключить буквы с диакритическими знаками или другие символы, которые могут быть ошибочно интерпретированы как буквы. Для этого нужно модифицировать регулярное выражение с учетом нужной локализации и типа символов.
Также стоит учитывать, что использование регулярных выражений может быть более затратным по времени для очень длинных строк, но в большинстве случаев это наиболее простой и эффективный способ решения задачи подсчета букв.
Как оптимизировать подсчет для больших объемов текста

Для эффективного подсчета букв в большом объеме текста важно учитывать несколько факторов: использование оптимальных алгоритмов, минимизация затрат по памяти и времени выполнения. Простое использование метода `len()` в Python не всегда подходит для обработки гигантских строк, так как каждый вызов может привести к избыточному времени на выполнение при наличии огромных объемов данных.
Одним из способов оптимизации является использование генераторов. Вместо того чтобы создавать в памяти большие строки, можно проходить по тексту построчно или посимвольно с помощью генераторов. Это позволяет избежать создания лишних копий строк и существенно экономит память.
Для подсчета букв в тексте эффективно использовать метод `collections.Counter()`, который позволяет быстро посчитать количество каждого символа в строке. Он работает за линейное время, что значительно быстрее, чем обычный цикл.
При работе с очень большими текстами важно учитывать распараллеливание вычислений. Использование многозадачности с библиотеками, такими как `concurrent.futures`, позволяет разделить текст на несколько частей и считать количество символов параллельно, сокращая общее время выполнения.
Если текст хранится в файле, для подсчета символов не стоит загружать весь файл в память. Лучше работать с ним поблочно, обрабатывая данные построчно или используя буферизацию. Это помогает минимизировать потребление памяти, особенно при работе с текстами в несколько гигабайт.
Для поиска букв в тексте можно использовать регулярные выражения через модуль `re`. Это особенно полезно, если необходимо учитывать только определенные символы (например, исключать пробелы или знаки препинания). Регулярные выражения позволяют быстро и эффективно фильтровать символы без дополнительной обработки.