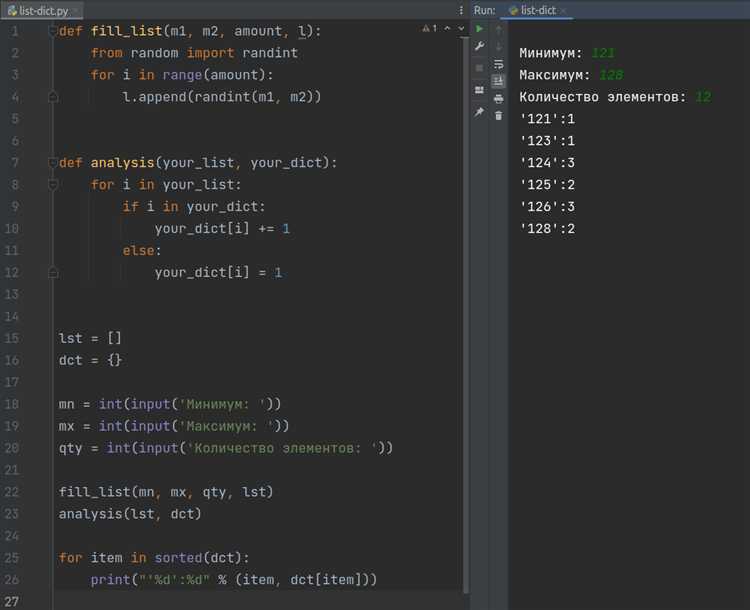
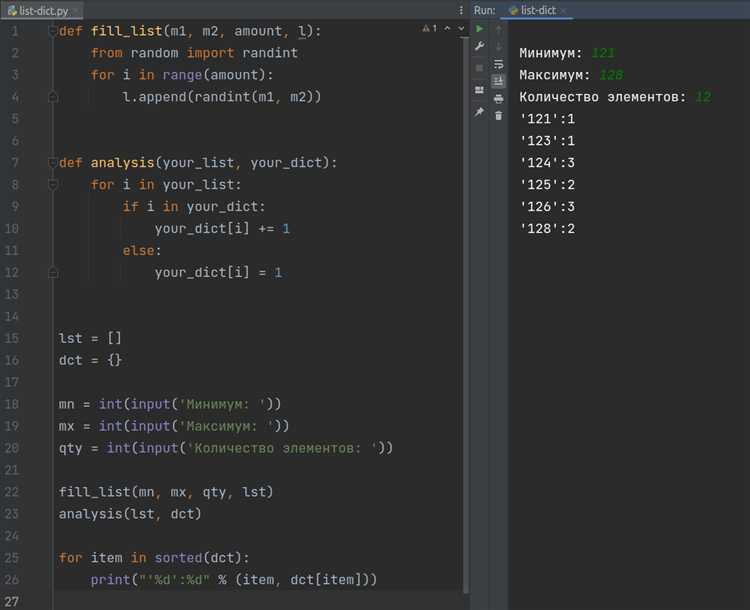
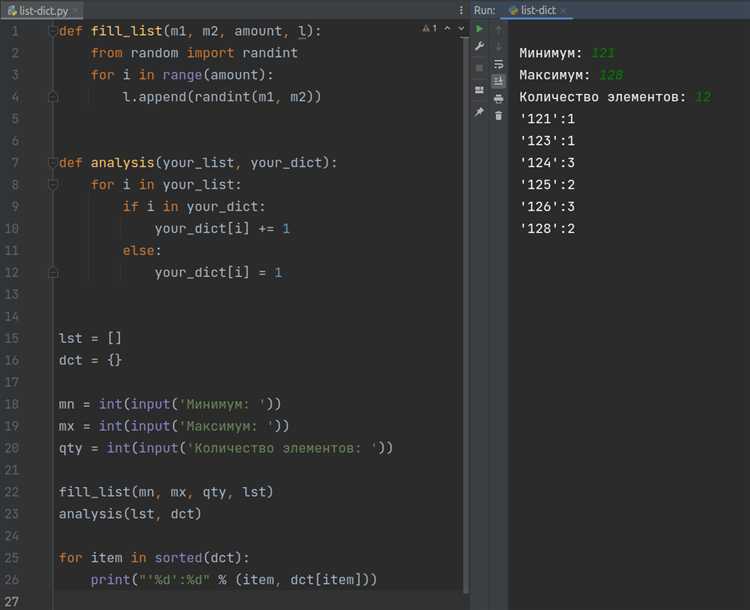
В Python список может содержать любое количество элементов, включая переменные различных типов. Под подсчётом переменных обычно понимается определение длины списка, что делается с помощью функции len(). Например, len(my_list) вернёт количество элементов в списке my_list.
Если требуется подсчитать не просто количество элементов, а только переменные определённого типа – например, только строки или только числа – можно использовать генераторы списков и функцию isinstance(). Пример: len([x for x in my_list if isinstance(x, str)]) выдаст количество строк в списке.
Если список содержит вложенные структуры, такие как другие списки или словари, и нужно подсчитать все переменные внутри, включая вложенные, потребуется рекурсивная функция. Например, можно обойти все уровни вложенности с помощью collections.abc.Iterable и проверки, является ли элемент вложенным контейнером, исключая строки и байтовые строки.
Для подсчёта только уникальных переменных в списке можно использовать set(), но это применимо только к хешируемым объектам. Вызов len(set(my_list)) даст количество уникальных значений, если все элементы можно хешировать.
Если в списке могут встречаться дубликаты ссылок на одни и те же объекты, и нужно учитывать именно разные объекты в памяти, стоит использовать id() вместе с set(): len(set(id(x) for x in my_list)).
Как отличить переменные от других объектов в списке
В Python нет прямого способа определить, была ли добавлена в список именно переменная, а не литерал или выражение. Однако можно анализировать типы и ссылки на объекты, чтобы получить максимально приближённую информацию.
- Если в список добавлен литерал (например,
42,"текст"), это не переменная, а значение напрямую. - Если в список добавлена переменная, то это ссылка на объект, ранее созданный с именем.
Для анализа рекомендуется использовать функцию globals() или locals():
vars_in_list = [x for x in globals() if globals()[x] in список]- Этот способ найдёт имена переменных, значения которых присутствуют в списке.
- Если одно и то же значение есть у нескольких переменных, отобразится первое найденное имя.
- Он не отличает переменные от временных значений, если они были присвоены ранее.
Чтобы исключить повторяющиеся значения или неявные объекты (например, функции, классы), нужно дополнительно фильтровать по типу:
[name for name in globals()
if globals()[name] in список and not callable(globals()[name])]Это исключит функции и классы, оставив только обычные объекты.
Важно учитывать, что переменные в Python – это просто имена, указывающие на объекты. В списке находятся сами объекты, а не имена. Поэтому определить, что именно было добавлено – имя или результат выражения – после добавления невозможно без дополнительной информации.
Чтобы обеспечить отслеживаемость, можно использовать именованные кортежи или словари с ключами, указывающими на изначальные имена.
Подсчёт уникальных переменных по идентификатору объекта
Чтобы определить, сколько уникальных объектов содержится в списке переменных, необходимо использовать функцию id(). Она возвращает уникальный идентификатор объекта в памяти, позволяя отличить даже идентичные по значению, но разные по ссылке элементы.
Пример:
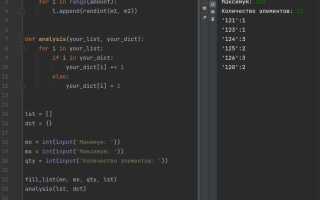
variables = [[], [], {}, {}, 1, 1, "a", "a", set(), set()]
unique_ids = set(id(obj) for obj in variables)
print(len(unique_ids))
Этот код создаёт список из 10 элементов разных типов, включая повторяющиеся значения. При помощи генератора и множества set() фиксируются уникальные идентификаторы. Функция len() возвращает количество уникальных объектов в списке – независимо от их значения.
Примитивные типы, такие как строки и целые числа, ссылаются на одни и те же объекты при совпадении значений, если они интернированы. Это влияет на результат. Например, 1 и "a" с одинаковыми значениями будут иметь одинаковые идентификаторы, если создаются интерпретатором Python автоматически. Чтобы обойти это, можно добавить проверку через copy.deepcopy(), если нужно учитывать каждую переменную как отдельную:
import copy
variables = [copy.deepcopy(x) for x in [1, 1, "a", "a", [], []]]
unique_ids = set(id(obj) for obj in variables)
print(len(unique_ids))
Результат изменится, так как deepcopy создаёт новые объекты. Этот подход полезен при необходимости анализа переменных как независимых, даже если они идентичны по значению.
Использование функции id() для анализа повторов

Функция id() возвращает уникальный идентификатор объекта в памяти. Это позволяет отличать одинаковые по значению, но разные по идентичности переменные.
- Если список содержит одинаковые значения,
id()помогает определить, ссылаются ли они на один и тот же объект. - Это особенно полезно при работе с изменяемыми типами данных (например, списками), где дублирование по значению не всегда означает совпадение по ссылке.
Пример анализа:
lst = [[1, 2], [1, 2], lst[0]]
ids = [id(item) for item in lst]
print(ids)
print(len(set(ids))) # Показывает количество уникальных объектов
Результат показывает, что третий элемент ссылается на первый, несмотря на идентичное содержимое у первых двух.
Для подсчёта уникальных объектов по идентификатору:
unique_objects = len(set(id(x) for x in список))
Если требуется выявить количество повторяющихся ссылок:
from collections import Counter
counts = Counter(id(x) for x in список)
повторы = {k: v for k, v in counts.items() if v > 1}
Таким образом можно отличить копии от повторных ссылок на один и тот же объект.
Фильтрация переменных по типу данных внутри списка
Для подсчёта переменных определённого типа в списке используется функция isinstance() или оператор type(). Предпочтительнее использовать isinstance(), так как он учитывает наследование.
Пример: пусть список содержит переменные разных типов:
данные = [1, "текст", 3.14, True, None, 42, "ещё", 0.5]Чтобы выделить только строки:
строки = [x for x in данные if isinstance(x, str)]Чтобы посчитать количество целых чисел:
числа = [x for x in данные if isinstance(x, int) and not isinstance(x, bool)]
print(len(числа))Булевы значения – это подкласс int, поэтому требуется дополнительная проверка через not isinstance(x, bool), иначе True и False будут ошибочно засчитаны как числа.
Для фильтрации по нескольким типам:
результат = [x for x in данные if isinstance(x, (int, float)) and not isinstance(x, bool)]Чтобы выделить только объекты, не принадлежащие к определённому типу:
не_строки = [x for x in данные if not isinstance(x, str)]Фильтрация по типу – ключевой шаг перед агрегацией или анализом содержимого списка, особенно при работе с неструктурированными данными.
Как учитывать вложенные списки при подсчёте переменных
Чтобы подсчитать количество переменных в списке с учётом вложенности, требуется рекурсивный подход. Обычный вызов len() работает только на верхнем уровне и не охватывает вложенные элементы.
Используйте функцию, которая будет обходить список на всех уровнях вложенности. В качестве переменной будем считать каждый элемент, не являющийся списком.
Пример функции:
def count_variables(lst):
count = 0
for item in lst:
if isinstance(item, list):
count += count_variables(item)
else:
count += 1
return count
Вызов count_variables([1, [2, 3], [4, [5, 6]], 7]) вернёт 7, так как в списке семь элементов, не являющихся списками.
Чтобы отличать переменные от других структур, можно уточнить проверку. Например, исключить словари, множества и кортежи:
def count_primitives(lst):
count = 0
for item in lst:
if isinstance(item, list):
count += count_primitives(item)
elif not isinstance(item, (dict, set, tuple)):
count += 1
return count
Такой подход позволяет контролировать, какие типы учитывать при подсчёте, и гибко обрабатывать вложенные структуры без искажения результата.
Способы исключения литералов и констант из подсчёта
Первый способ – использовать проверку типов через isinstance(). Например, можно отфильтровать только имена переменных, исключив строки, числа и другие литералы:
variables = [x, y, "текст", 42, z]
filtered = [v for v in variables if not isinstance(v, (int, float, str, bool, complex))]Второй способ – использовать модуль inspect и анализировать исходные объекты. Это особенно полезно, если список создаётся динамически или содержит объекты функций:
import inspect
filtered = [v for v in variables if not inspect.isbuiltin(v) and not inspect.isfunction(v) and not isinstance(v, (int, float, str))]Если список составлен вручную, можно использовать фильтрацию по именам через globals() или locals(), исключая элементы, имя которых записано в верхнем регистре (по соглашению – это константы):
filtered_names = [name for name in locals() if name.islower()]
result = [locals()[name] for name in filtered_names]При работе с модулями следует исключать элементы, чьи имена начинаются с подчёркивания или полностью записаны в верхнем регистре:
filtered = [v for name, v in globals().items() if name.islower() and not name.startswith("_")]Все способы желательно комбинировать, если список создаётся автоматически или его содержимое неизвестно заранее. Это снижает вероятность учёта нежелательных элементов.
Подсчёт переменных в списке с использованием множества

Множество позволяет быстро определить количество уникальных элементов в списке. Это полезно, когда требуется убрать повторы и получить точное число различных переменных.
Пример:
список = ['x', 'y', 'z', 'x', 'y']
уникальные = set(список)
print(len(уникальные))Результат: 3, так как ‘x’ и ‘y’ повторяются.
Если нужно учесть типы данных, следует привести значения к строковому виду или использовать кортежи с типом:
список = [1, '1', 1.0, True]
уникальные = set((type(элемент), элемент) for элемент in список)
print(len(уникальные))Результат: 3, поскольку 1, 1.0 и True считаются равными в обычном множестве, но различаются по типу.
Для вложенных структур лучше использовать рекурсивное преобразование во фризованные типы:
def заморозить(объект):
if isinstance(объект, list):
return tuple(заморозить(э) for э in объект)
if isinstance(объект, dict):
return tuple(sorted((ключ, заморозить(знач)) for ключ, знач in объект.items()))
return объект
список = [[1, 2], [1, 2], [2, 1]]
уникальные = set(заморозить(э) for э in список)
print(len(уникальные))Результат: 2, так как [1, 2] и [2, 1] – разные по порядку элементы.