При обработке текстовых данных часто требуется определить, какие символы в строке встречаются более одного раза. Это может быть полезно при анализе качества ввода пользователя, поиске опечаток, создании частотных словарей или в задачах сжатия данных. Python предлагает несколько лаконичных и эффективных способов решения этой задачи без необходимости использовать сторонние библиотеки.
Для быстрой идентификации повторяющихся символов можно использовать встроенные структуры данных – словарь и множество. Подход с использованием collections.Counter позволяет подсчитать все символы за один проход по строке, а затем отфильтровать те, чья частота больше единицы. Этот метод оптимален для строк средней длины и обеспечивает читаемость кода.
Если важна производительность при работе с очень большими строками, стоит рассмотреть варианты без использования Counter. Например, последовательный обход строки с ручным подсчетом и промежуточным сохранением результата в словарь позволит избежать дополнительного импорта и даст контроль над точной логикой подсчета.
Для Unicode-строк важно учитывать, что символы могут занимать разное количество байт, но методы подсчета на уровне символов в Python 3 работают прозрачно благодаря полной поддержке Unicode в стандартных строках (str). Это делает описанные методы универсальными для работы с любыми языками и алфавитами, включая кириллицу, латиницу и символы CJK.
Как получить частоту каждого символа в строке с помощью словаря
Создайте пустой словарь и пройдитесь по строке в цикле. Если символ уже есть в словаре, увеличьте его значение на единицу. Если нет – добавьте его в словарь с начальным значением 1. Такой подход обеспечивает линейную сложность O(n), где n – длина строки.
Пример реализации:
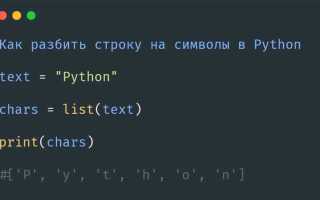
text = "пример"
frequency = {}
for char in text:
if char in frequency:
frequency[char] += 1
else:
frequency[char] = 1
print(frequency)
Для упрощения можно использовать collections.Counter, но при ручной реализации словаря лучше контролируется логика подсчёта и исключаются зависимости. Это особенно важно в задачах, требующих минимального потребления памяти или точной настройки поведения при обработке нестандартных символов.
Подсчет количества повторений конкретного символа
Для определения числа вхождений заданного символа в строку применяется метод count(). Он возвращает целое число, соответствующее количеству неперекрывающихся повторений символа.
Пример: «abracadabra».count(«a») вернёт 5, поскольку символ «a» встречается в строке пять раз.
Метод нечувствителен к регистру, только если строка предварительно приведена к одному регистру, например: text.lower().count(«а»).
Для обработки пользовательского ввода перед подсчётом рекомендуется применять strip() для удаления лишних пробелов и casefold() при сравнении без учёта регистра.
При проверке нескольких символов лучше использовать цикл с накоплением результатов:
symbols = ['a', 'b', 'r']
text = "abracadabra"
counts = {char: text.count(char) for char in symbols}
Подсчёт не поддерживает регулярные выражения. Для более гибкого анализа, например, с учётом подстрок или шаблонов, используется модуль re.
Использование collections.Counter для анализа повторений
Модуль collections предоставляет структуру Counter, оптимизированную для подсчёта количества вхождений элементов в итерируемые объекты. Применительно к строкам, Counter создает словарь, где ключи – символы, а значения – их количество.
Пример: from collections import Counter, затем Counter("программа") вернёт Counter({'р': 2, 'п': 1, 'о': 1, 'г': 1, 'а': 2, 'м': 2}). Объект поддерживает методы словаря, включая .items(), .most_common() и прямой доступ по ключу.
Для выявления символов с более чем одним вхождением используйте генератор: [символ for символ, счёт in Counter(строка).items() if счёт > 1]. Это эффективно даже на больших объемах текста, так как Counter реализован на C и работает быстрее ручного подсчета.
Функция .most_common(n) полезна для анализа частоты: она возвращает список из n наиболее часто встречающихся символов. Например, Counter("анализ").most_common(2) вернёт [('а', 2), ('н', 1)].
Для подсчета без учета регистра используйте Counter(строка.lower()). Для фильтрации только букв – предварительно удалите ненужные символы через генератор: Counter(c for c in строка if c.isalpha()).
При обработке строк часто возникает задача фильтрации символов, которые встречаются в строке более одного раза. Для этого можно использовать структуру данных, такую как словарь или коллекции в Python. С помощью этих инструментов можно быстро и эффективно находить дублирующиеся символы, исключая те, которые встречаются только один раз.
Для фильтрации дублирующихся символов можно воспользоваться следующим подходом: сначала посчитаем количество вхождений каждого символа, затем выберем те, что встречаются больше одного раза. Для этого подойдет метод collections.Counter, который автоматически считает количество каждого символа в строке. После этого можно отфильтровать только те символы, которые имеют счетчик больше единицы.
Пример кода:
from collections import Counter
def get_duplicates(input_string):
counts = Counter(input_string)
return [char for char, count in counts.items() if count > 1]
input_string = "aabbccde"
duplicates = get_duplicates(input_string)
print(duplicates) # ['a', 'b', 'c']
Этот метод позволяет получить список символов, которые повторяются в строке. Важно заметить, что мы фильтруем только символы с количеством вхождений больше одного, игнорируя все уникальные символы.
Пример с сохранением порядка:
def get_duplicates_ordered(input_string):
seen = set()
duplicates = set()
result = []
for char in input_string:
if char in seen:
if char not in duplicates:
result.append(char)
duplicates.add(char)
else:
seen.add(char)
return result
input_string = "aabbccde"
duplicates = get_duplicates_ordered(input_string)
print(duplicates) # ['a', 'b', 'c']
Этот подход позволит получить дублирующиеся символы в том порядке, в котором они появляются в исходной строке, исключая дублирования в результирующем списке.
Учет регистра и пробелов при подсчете символов

При подсчете символов в строке важно четко определить, как учитывать регистр и пробелы. Без ясных правил результат подсчета может значительно различаться.
Рассмотрим два основных аспекта:
- Регистр символов: Если строка содержит символы в разных регистрах, важно понимать, следует ли воспринимать их как одинаковые. Например, буквы «a» и «A» могут быть посчитаны как одинаковые или разные символы в зависимости от задачи.
- Пробелы: Пробелы также могут быть значимыми. В некоторых случаях их нужно игнорировать, а в других – считать, как обычные символы.
Для учета этих факторов можно использовать различные подходы:
- Игнорирование регистра: Для того чтобы не учитывать регистр, можно привести все символы строки к одному регистру перед подсчетом. Для этого используйте метод
lower()илиupper(). - Исключение пробелов: Для исключения пробелов можно воспользоваться методом
replace(" ", ""), который удалит все пробелы из строки перед подсчетом. - Учет пробелов: Если пробелы должны учитываться как символы, их не следует удалять. Подсчет будет включать все пробелы в строке, как и любые другие символы.
Пример учета регистра и пробелов:
input_string = "Hello World"
# Игнорирование регистра
normalized_string = input_string.lower()
# Учет пробелов
count_dict = {}
for char in normalized_string:
count_dict[char] = count_dict.get(char, 0) + 1
print(count_dict)
Этот код игнорирует регистр символов и учитывает пробелы. Если пробелы не важны, можно удалить их перед подсчетом.
Таким образом, выбор метода учета регистра и пробелов зависит от задачи и того, какие символы должны быть подсчитаны. Важно заранее определить, как обработать регистр и пробелы, чтобы избежать ошибок в результате подсчета.
Сортировка символов по количеству повторений

Для того чтобы отсортировать символы строки по количеству их повторений, можно использовать стандартные средства Python, такие как Counter из модуля collections и функцию sorted.
Первым шагом будет подсчет частоты каждого символа в строке. Для этого применяется Counter, который создает словарь, где ключами будут символы, а значениями – их количество. Пример:
from collections import Counter
text = "example string"
counter = Counter(text)
Теперь у нас есть объект counter, который содержит частоту каждого символа. Для сортировки по количеству повторений используется sorted, где можно указать, что сортировка должна быть по значениям (по количеству повторений), а не по ключам. Пример:
sorted_counter = sorted(counter.items(), key=lambda x: x[1], reverse=True)
Этот код отсортирует элементы по убыванию частоты появления символов. reverse=True позволяет получить сортировку от наиболее часто встречающегося символа к наименее частому.
Если нужно вывести только отсортированные символы без учета их частоты, можно использовать следующий подход:
sorted_symbols = [item[0] for item in sorted_counter]
Этот метод поможет легко получить список символов, отсортированных по частоте их появления в строке. Если требуется учитывать регистр символов или учитывать пробелы, важно заранее обрабатывать строку в зависимости от контекста задачи.
Для улучшения производительности, особенно при работе с большими объемами данных, можно использовать heapq для получения наиболее часто встречающихся символов, если не нужно полностью сортировать все элементы.