В Python для подсчета количества символов в строке используется встроенная функция len(). Она возвращает количество символов, включая пробелы, спецсимволы и любые другие видимые или невидимые символы, такие как табуляция или символ новой строки. Простота этой функции позволяет эффективно решать задачи, связанные с анализом длины строк, будь то обработка текстовых данных или проверка условий.
Кроме стандартного способа с помощью len(), существуют и другие методы, позволяющие получить количество символов в строке, например, использование регулярных выражений или методов работы с байтами в строках, но они могут быть полезны в специфических ситуациях, требующих более детализированного подхода к подсчету символов. Однако для большинства стандартных задач достаточно базовой функции.
Важно помнить, что метод len() работает с любыми типами строк, включая строки с юникодными символами, и корректно подсчитывает все символы в строке, включая невидимые, такие как пробелы и символы переноса строки. Для работы с байтами или более сложными строковыми форматами могут потребоваться дополнительные методы, такие как encode() или decode().
Использование функции len() для подсчета символов
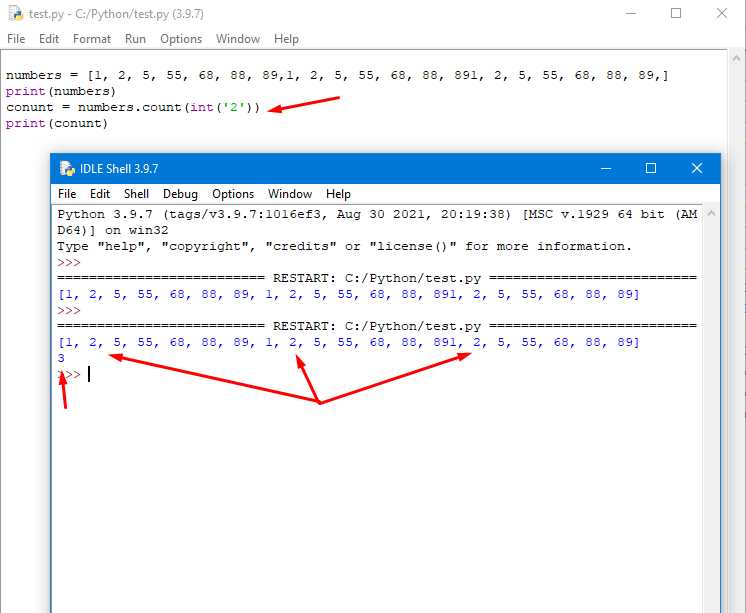
Пример использования:
s = "Привет, мир!" print(len(s)) # Выведет 12
Важный момент: len() учитывает все символы, включая невидимые, такие как пробелы и символы новой строки. Например, строка «Привет мир» (с пробелом между словами) будет иметь длину 12, а не 11.
Функция len() также работает с пустыми строками. В таком случае результат будет равен нулю:
s = "" print(len(s)) # Выведет 0
Необходимо помнить, что len() работает только с объектами, поддерживающими измерение длины, такими как строки, списки, кортежи и другие коллекции. Для строк это всегда количество символов, что делает len() удобным инструментом для быстрой работы с текстовыми данными.
Подсчет символов с учетом пробелов и спецсимволов

В Python для подсчета символов в строке, включая пробелы и спецсимволы, можно использовать встроенную функцию len(). Эта функция возвращает количество символов в строке, не делая различий между буквами, пробелами и знаками препинания.
Пример использования:
text = "Привет, мир!"
print(len(text)) # Выведет 13- Пробелы считаются отдельными символами.
- Спецсимволы (например,
\n,\t) также занимают одну позицию в строке. - Для строки с несколькими пробелами результат будет включать каждый из них в подсчет.
В случае работы с многострочными текстами можно использовать тот же метод. Пример:
multi_line_text = """Первая строка
Вторая строка"""
print(len(multi_line_text)) # Выведет 27 (включая символы новой строки)Чтобы исключить пробелы и спецсимволы, можно использовать метод replace() для замены пробелов на пустую строку, а затем пересчитать длину:
text_without_spaces = text.replace(" ", "")
print(len(text_without_spaces)) # Выведет 12Для более сложных задач, таких как подсчет только видимых символов, можно использовать регулярные выражения. Например, чтобы посчитать только буквы и цифры:
import re
text = "Привет, мир! 123"
clean_text = re.sub(r'[^a-zA-Z0-9а-яА-Я]', '', text)
print(len(clean_text)) # Выведет 14Как посчитать количество символов без учета пробелов
Для того чтобы подсчитать количество символов в строке без учета пробелов, достаточно воспользоваться встроенными функциями Python. Простой и эффективный способ – использовать метод replace(), который удаляет пробелы из строки, и затем применить функцию len() для подсчета оставшихся символов.
Пример кода:
text = "Пример текста с пробелами"
text_without_spaces = text.replace(" ", "")
count = len(text_without_spaces)
print(count)В этом примере строка text передается в метод replace(" ", ""), который заменяет все пробелы на пустые строки. После этого вызывается len() для подсчета символов в измененной строке.
Если в строке могут быть не только пробелы, но и другие виды пробельных символов (например, табуляции или переводы строк), то можно использовать метод re.sub() из модуля re для замены всех пробельных символов на пустую строку.
Пример с использованием регулярных выражений:
import re
text = "Текст с пробелами и табуляциями\tи\nновыми строками"
text_without_spaces = re.sub(r'\s+', '', text)
count = len(text_without_spaces)
print(count)Здесь \s+ представляет собой регулярное выражение для всех видов пробельных символов, включая пробелы, табуляции и переводы строк. Метод re.sub() удаляет их из строки.
Этот подход работает эффективно для различных типов пробелов, и результат всегда точен.
Подсчет количества символов с учетом юникодных символов
В Python количество символов в строке можно посчитать с помощью функции len(), но важно учитывать особенности работы с юникодными символами. Юникод позволяет хранить символы из множества языков и письменностей, и не все символы занимают одинаковое количество байт в памяти.
Метод len() возвращает количество символов, как они представлены в строке, независимо от их внутреннего представления в памяти. Например, некоторые символы могут быть составными (состоящими из нескольких кодовых единиц в юникоде), что важно учитывать при работе с многоязычным текстом.
Для точного подсчета количества символов в строках, содержащих юникодные символы, рекомендуется использовать метод unicodedata.normalize() из стандартной библиотеки. Этот метод позволяет привести строку к нормализованному виду, где составные символы могут быть разделены на базовые символы и дополнительные элементы. В результате подсчета с использованием len() можно избежать ошибок, связанных с многократным учетом составных символов.
Пример использования нормализации для подсчета количества символов:
import unicodedata
text = "е́лка" # символ 'е' с акцентом (нормализуется в два символа)
normalized_text = unicodedata.normalize('NFC', text)
print(len(normalized_text)) # Выведет 5, а не 4
Также стоит учитывать, что для юникодных символов, таких как эмодзи или определенные арабские и китайские символы, один визуально представленный символ может занимать несколько кодовых единиц. В таких случаях стоит использовать методы, которые дают точную информацию о количестве визуально воспринимаемых символов, а не просто кодовых единиц.
Для работы с такими символами можно использовать библиотеку unidecode, которая помогает преобразовывать юникодные символы в более простые аналоги, если это необходимо для подсчета символов.
Как посчитать количество символов в строках с учетом регистров

В Python для подсчета количества символов в строке, включая символы разных регистров, используется встроенная функция len(). Она возвращает точное количество символов, независимо от того, в каком регистре они находятся. Например, строка «Привет» состоит из 6 символов, а строка «пРИВЕТ» также состоит из 6 символов, так как регистр не влияет на длину строки.
Если необходимо учитывать регистры при анализе текста, можно использовать методы, которые позволяют обрабатывать символы по отдельности. Например, метод str.count() может быть использован для подсчета количества вхождений символов в строке с учетом их регистра. В отличие от метода len(), str.count() будет учитывать различия между заглавными и строчными буквами.
Пример подсчета символов с учетом регистра:
text = "ПрИвет"
count = text.count("и") # Посчитает только буквы "и", без учета регистра
print(count) # Выведет 1
Важно отметить, что метод len() не различает заглавные и строчные буквы. Чтобы получить точную информацию о количестве символов с учетом их регистра, достаточно использовать стандартную функцию, как показано в примере ниже:
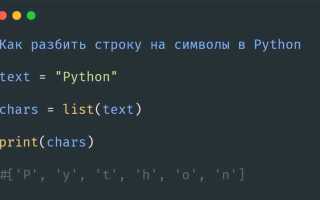
text = "Python" print(len(text)) # Выведет 6, так как в строке 6 символов
Если цель – подсчитать количество символов в строках, разделенных по какому-либо признаку, например, по пробелам или другим разделителям, следует использовать метод split(). Это позволит разделить строку на отдельные слова и затем подсчитать длину каждого слова с учетом регистра.
text = "Hello World" words = text.split() lengths = [len(word) for word in words] print(lengths) # Выведет [5, 5]
Подсчет символов в строках с многократными пробелами
При подсчете символов в строках с несколькими пробелами важно учитывать их как отдельные символы, если они не удалены. Python предоставляет несколько методов для работы с такими строками.
- len(): функция
len()возвращает общее количество символов, включая все пробелы. Например, для строки"Привет мир"(с двумя пробелами) результатом будет 13.
s = "Привет мир"
print(len(s)) # Выведет 13
Этот способ прост, но не позволяет манипулировать пробелами. Если нужно, например, игнорировать многократные пробелы, следует использовать дополнительные методы обработки строк.
- strip() и replace(): для удаления лишних пробелов используйте
strip()для обрезки пробелов по краям строки иreplace()для замены нескольких пробелов на один.
s = " Привет мир "
s = s.strip().replace(" ", " ")
print(len(s)) # Выведет 12
Для подсчета символов после удаления избыточных пробелов используйте методы работы с пробелами и функции для их замены.
- split(): если необходимо разделить строку на слова, а затем подсчитать количество символов, включая все пробелы, можно использовать метод
split().
s = "Привет мир"
words = s.split() # Разделит строку на слова
char_count = sum(len(word) for word in words) # Считает количество символов без учета пробелов
print(char_count) # Выведет 11
Этот подход полезен, если пробелы между словами не важны и нужно подсчитать только реальные символы без учета интервалов.
- re.sub(): для более сложных случаев, когда необходимо точно контролировать количество пробелов или их распределение, можно использовать регулярные выражения с функцией
re.sub().
import re
s = "Привет мир"
s = re.sub(r'\s+', ' ', s) # Заменяет все множественные пробелы на один
print(len(s)) # Выведет 12
В таких случаях регулярные выражения позволяют гибко контролировать формат строки и выполнять нужные преобразования.
Как посчитать количество символов в строках с учетом переводов строк
Для подсчета количества символов в строках с учетом символов перевода строки в Python можно использовать встроенные функции и методы. Строки, содержащие символы переноса строки, учитываются в общем количестве символов как обычные символы.
Метод len() является самым простым и эффективным способом подсчета длины строки, включая все символы, такие как пробелы и переводы строки. Например, строка с несколькими переводами строки будет включать каждый символ перевода как часть общего подсчета.
text = "Первая строка\nВторая строка\nТретья строка"
print(len(text))
Результат выполнения кода покажет количество символов в строке, включая символы переноса строки \n, которые занимают один символ каждый. В данном примере длина строки составит 33 символа, включая три символа перевода строки.
Если требуется подсчитать количество строк в тексте, то можно использовать метод splitlines(), который разделяет строку на список строк, игнорируя символы перевода строки. Затем можно просто подсчитать количество элементов в списке.
text = "Первая строка\nВторая строка\nТретья строка"
lines = text.splitlines()
print(len(lines))
Этот код возвращает количество строк в тексте, без учета символов перевода строки, которые теперь воспринимаются как разделители строк.
Важно помнить, что в строках, полученных из внешних источников (например, из файлов или веб-страниц), символы перевода строки могут различаться. В Windows используется пара символов \r\n, в то время как в Unix-подобных системах – только \n. Для корректного подсчета длины строки важно привести строку к единому виду, например, заменив все символы \r\n на \n.
text = text.replace('\r\n', '\n')
print(len(text))
Таким образом, Python предоставляет гибкие инструменты для точного подсчета длины строк с учетом переводов строк и других специальных символов.
Использование регулярных выражений для подсчета символов в строках

Регулярные выражения (regex) в Python предоставляют мощный инструмент для работы с текстами. Для подсчета символов в строках регулярные выражения позволяют эффективно искать определенные паттерны и учитывать только нужные элементы. Использование модуля re позволяет гибко настроить поиск символов, исключая из подсчета пробелы, специальные символы или другие элементы.
Для простого подсчета всех символов в строке можно использовать регулярное выражение, которое ищет все символы, соответствующие определенному паттерну. Например, чтобы посчитать все буквы и цифры в строке, можно использовать следующий код:
import re
text = "Пример 123, тест!"
count = len(re.findall(r'\w', text))
print(count)Здесь \w соответствует любому буквенно-цифровому символу (буквы и цифры), а re.findall() возвращает все совпадения, которые затем можно посчитать с помощью len().
Если нужно исключить пробелы и знаки препинания, можно использовать более точные регулярные выражения. Например, для подсчета только букв в строке:
count = len(re.findall(r'[а-яА-Яa-zA-Z]', text))
print(count)В данном случае регулярное выражение [а-яА-Яa-zA-Z] охватывает все буквы русского и латинского алфавитов. Для учета других символов, например, цифр, можно дополнительно расширить паттерн.
Чтобы подсчитать все символы, исключая пробелы, следует использовать выражение, которое ищет любой символ, кроме пробела:
count = len(re.findall(r'\S', text))
print(count)Здесь \S соответствует любому символу, кроме пробела. Это полезно для подсчета всех символов в строках, где важно исключить пробелы, но учесть все другие символы, включая знаки препинания.
Регулярные выражения предоставляют гибкость, но важно учитывать производительность. Для строк больших размеров использование re.findall() может быть менее эффективным, чем более прямолинейные методы, такие как str.count() или итерация по строке. В случае необходимости подсчета конкретных типов символов регулярные выражения остаются мощным инструментом для оптимизации и точности.