Точная оценка количества слов в строке – частая задача при обработке текстов, особенно в анализе пользовательских данных, логов и ввода с клавиатуры.
Как определить границы слов в строке
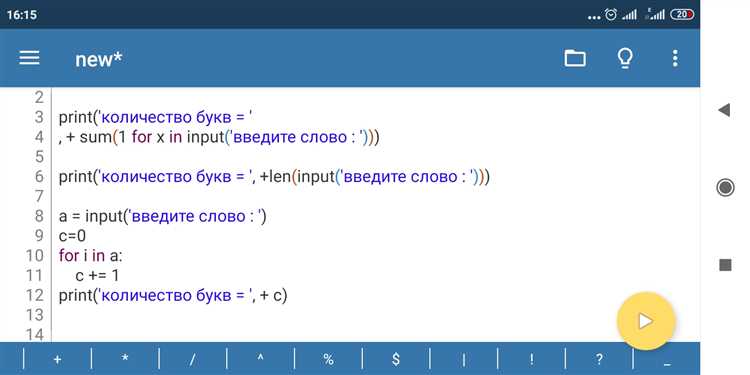
Для точного подсчёта слов в строке необходимо чётко определить, что считать границей слова. В Python границы слов чаще всего определяются с использованием регулярных выражений или встроенных методов обработки строк. Рассмотрим ключевые подходы:
- Пробел как разделитель: Метод
str.split()по умолчанию разбивает строку по любым пробельным символам (включая табуляции и переводы строк). Это базовый, но не всегда надёжный способ, так как он не учитывает знаки препинания. - Регулярные выражения: Модуль
reпозволяет точно задать шаблон слова. Наиболее универсальный вариант –re.findall(r'\b\w+\b', строка). Здесь:\b– граница слова, определяемая переходом от символа слова к несимволу и наоборот;\w+– последовательность букв, цифр и подчёркиваний.
Такой подход исключает знаки препинания и даёт более точный результат.
- Поддержка юникода: Для языков, отличных от английского, важно использовать флаг
re.UNICODEв регулярных выражениях. Например:re.findall(r'\b\w+\b', строка, flags=re.UNICODE). - Нестандартные символы-разделители: В текстах могут встречаться нестандартные символы (например, тире, точки с запятой). Для их учёта используйте выражения вида:
re.split(r'[^\w]+', строка). - Обработка с учётом контекста: В некоторых случаях слова могут включать дефисы или апострофы (например, «пятиэтажный», «don’t»). Тогда стоит использовать более сложные шаблоны:
re.findall(r"\b[\w'-]+\b", строка).
Выбор подхода зависит от целей анализа текста. Для формального подсчёта слов в большинстве случаев достаточно регулярного выражения с границами слова. Для лингвистической точности потребуется кастомизация шаблонов и дополнительная предобработка текста.
Использование метода split() без параметров
Метод split() без аргументов разделяет строку по любым пробельным символам: пробелам, табуляциям, переводам строк. Последовательности пробелов не создают пустых элементов в результате. Это делает метод оптимальным для подсчёта слов в тексте, где структура пробелов может быть непредсказуемой.
Пример:
text = " Это пример\nстроки\tс разными пробелами "
words = text.split()
print(len(words)) # Результат: 6Особенности:
split()удаляет начальные и конечные пробелы.- Все виды пробелов интерпретируются одинаково.
- Пустые строки возвращают пустой список, что упрощает проверку:
empty = " "
print(len(empty.split())) # Результат: 0Рекомендации:
- Используйте
split()без параметров, если входной текст не требует точного контроля над разделителями. - Для статистики по словам в неструктурированном тексте метод предпочтительнее любых регулярных выражений.
- При работе с пользовательским вводом
split()обеспечивает устойчивость к лишним пробелам.
Обработка множественных пробелов и пустых строк

Множественные пробелы внутри строки создают проблему при подсчёте слов с использованием метода split(). По умолчанию str.split() без аргументов разбивает строку по любым пробельным символам и автоматически игнорирует их дублирование, что делает его предпочтительным для таких случаев.
Например, строка " Пример строки с пробелами " будет корректно преобразована в список ['Пример', 'строки', 'с', 'пробелами']. Достаточно вызвать len(text.split()), чтобы получить точное количество слов.
Если используется split(' ') с явно указанным пробелом, то множественные пробелы не игнорируются и в список попадут пустые строки. Это приводит к неверному результату, поскольку "слово слово".split(' ') вернёт ['слово', '', 'слово'].
Для проверки на пустую строку до подсчёта необходимо использовать strip(): if not text.strip():. Это гарантирует, что строки, содержащие только пробелы, не будут учитываться.
Рекомендуемая последовательность: сначала обрезать строку с помощью strip(), затем вызвать split() без аргументов, и только потом подсчитывать количество слов через len(). Такой подход устойчив к лишним пробелам и корректно работает даже с пустыми строками.
Подсчёт слов с учётом знаков препинания
Знаки препинания могут исказить результат подсчёта слов, если не удалить их перед разбиением строки. Например, в строке "Привет, мир!" слова «Привет» и «мир» разделены запятой и восклицательным знаком. Если использовать метод split() без предварительной обработки, результатом будут слова с примыкающими символами: "Привет," и "мир!", что недопустимо при точном подсчёте.
Для корректного подсчёта необходимо удалить все символы, не относящиеся к буквам и пробелам. Это можно сделать с помощью регулярных выражений:
import re
text = "Привет, мир! Как дела?"
clean_text = re.sub(r'[^\w\s]', '', text)
words = clean_text.split()
print(len(words)) # Результат: 4
Регулярное выражение [^\w\s] удаляет все символы, кроме букв, цифр и пробелов. Это позволяет исключить точки, запятые, восклицательные знаки и прочие знаки препинания.
Для поддержки кириллицы рекомендуется использовать флаг re.UNICODE или добавить диапазон букв явно:
clean_text = re.sub(r'[^\w\s]', '', text, flags=re.UNICODE)
Альтернативно, для строгой фильтрации только русских букв:
clean_text = re.sub(r'[^А-Яа-яЁё\s]', '', text)
После удаления знаков препинания результат подсчёта становится точным и не зависит от расстановки символов в тексте.
Использование регулярных выражений для подсчёта слов
Регулярные выражения позволяют точно определить границы слов даже в строках со смешанным содержимым. Базовый шаблон для подсчёта слов – \b\w+\b. Он находит последовательности символов, ограниченные словесными границами, включая буквы, цифры и подчёркивания.
Для более надёжной работы с текстами на русском языке желательно использовать флаг re.UNICODE. Это обеспечит корректную обработку кириллических символов:
import re
text = "Пример строки с 7 словами и числами 123"
words = re.findall(r'\b\w+\b', text, re.UNICODE)
print(len(words))Если необходимо исключить числа и оставить только слова, стоит использовать шаблон \b[^\W\d_]+\b. Он отфильтрует цифровые группы и символы, не относящиеся к словам:
words = re.findall(r'\b[^\W\d_]+\b', text, re.UNICODE)Для текстов, содержащих дефисы или апострофы (например, “мать-и-мачеха”, “rock’n’roll”), шаблон потребуется адаптировать:
pattern = r"\b[^\W\d_]+(?:[-'][^\W\d_]+)*\b"
words = re.findall(pattern, text, re.UNICODE)В этом шаблоне учитываются составные слова, где дефис или апостроф не разделяют слово, а входят в его состав.
Для максимальной точности желательно предварительно нормализовать строку: привести к нижнему регистру, удалить лишние пробелы и специальные символы, не относящиеся к лексемам.
Сравнение различных подходов на практике
При подсчете слов в строке на Python существует несколько популярных методов, каждый из которых имеет свои преимущества и недостатки в зависимости от контекста использования.
1. Использование метода split(): Это один из самых простых и быстрых способов для разделения строки на слова. Метод split() автоматически разделяет строку по пробелам, игнорируя лишние пробелы. Он эффективен для строк, где нет сложных разделителей (например, пунктуации) и где нужно просто подсчитать количество слов.
2. Использование регулярных выражений (модуль re): Когда строка содержит различные разделители (запятые, точки, дефисы и т.д.), метод split() может не подойти. В таких случаях регулярные выражения позволяют гибко настроить разделение строки, используя выражения для учета всех возможных разделителей. Это решение дает больше точности, но при этом может быть менее производительным для небольших объемов данных из-за сложности паттернов.
3. Итерация через символы строки: Этот подход позволяет вручную проверять каждый символ строки, что может быть полезно в специфических задачах, например, если нужно учитывать определенные правила для разделителей. Однако этот метод требует больше кода и, как правило, уступает по производительности и читаемости встроенным функциям.
4. Использование библиотеки collections.Counter: Если задача не просто подсчитать количество слов, а также выяснить частоту их появления, Counter из библиотеки collections может быть полезен. Сначала строка разбивается на слова, затем Counter подсчитывает частоту каждого слова. Этот метод особенно полезен для анализа больших объемов данных, где важно не только количество, но и распределение слов.
5. Использование генераторов: Если строка обрабатывается в рамках более сложных вычислений, генераторы в Python могут значительно улучшить производительность, минимизируя использование памяти. Вместо хранения всех слов в памяти можно использовать генератор для обработки элементов по одному, что полезно при работе с большими текстами.
Каждый из подходов подходит для разных сценариев. Метод split() является хорошим выбором для базовых задач с небольшими строками. Для сложных случаев с различными разделителями или большими объемами данных стоит рассмотреть регулярные выражения или более сложные подходы с использованием генераторов и Counter.
Вопрос-ответ:
Как подсчитать количество слов в строке на Python?
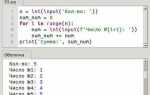
Для подсчета слов в строке на Python можно воспользоваться методом `split()`. Этот метод разделяет строку на слова по пробелам (или другим разделителям), возвращая список слов. Затем можно посчитать длину этого списка с помощью функции `len()`. Пример кода:
Можно ли подсчитать количество слов в строке, игнорируя знаки препинания?
Да, для этого можно использовать регулярные выражения. Сначала нужно удалить знаки препинания с помощью модуля `re`, а затем разделить строку на слова. Пример кода, который очищает строку от знаков препинания и подсчитывает количество слов:
Как можно подсчитать количество слов в строке без использования метода split()?
Если по какой-то причине нельзя использовать метод `split()`, можно подсчитать количество слов вручную. Для этого нужно пройти по строке, отслеживая пробелы, которые разделяют слова. Когда встречается пробел или конец строки, увеличиваем счетчик. Это также будет работать, если слова разделены несколькими пробелами. Вот пример:
Как подсчитать количество уникальных слов в строке?
Для подсчета уникальных слов можно использовать структуру данных `set`, которая автоматически удаляет дубли. Сначала нужно преобразовать строку в список слов, а затем преобразовать этот список в множество. Получившееся множество будет содержать только уникальные слова. Пример кода:
Как учитывать слова в строке, разделенные не только пробелами?
Если слова могут быть разделены различными символами (например, запятыми, точками или другими знаками препинания), лучше использовать регулярные выражения. Модуль `re` позволяет найти все слова в строке, игнорируя различные разделители. Вот пример кода, который находит все слова в строке и подсчитывает их количество: