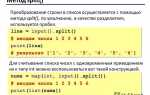
В Python задача подсчета количества символов в строке решается несколькими простыми методами. Наиболее часто используется встроенная функция len(), которая возвращает количество символов в строке, включая пробелы, символы новой строки и другие специальные знаки.
Для примера, если у вас есть строка, например «Привет, мир!», вызвав len(«Привет, мир!»), вы получите число 13, поскольку функция учитывает все символы, включая запятую и пробел.
Для более сложных случаев, например, если нужно посчитать только определенные символы (например, только буквы или цифры), можно использовать методы строк, такие как isalpha(), isdigit() или регулярные выражения с модулем re.
Особое внимание стоит уделить учету символов Unicode. Если строка содержит символы, которые занимают больше одного байта (например, эмодзи или редкие символы), метод len() все равно посчитает их как один символ, но для более глубокого анализа потребуется использование функций, которые учитывают длину строки в байтах, например, encode() с дальнейшим анализом байтов.
Использование функции len() для подсчета символов в строке
Функция len() в Python позволяет быстро и эффективно определить количество символов в строке. Она принимает строку как аргумент и возвращает целое число, равное количеству символов, включая пробелы, знаки препинания и специальные символы.
Пример использования:
text = "Пример строки"
length = len(text)
Особенность функции заключается в том, что она работает не только с обычными буквами, но и с любыми Unicode-символами. Например, если строка содержит эмодзи или символы других языков, len() учтет их как отдельные символы.
Функция len() является встроенной и не требует импорта дополнительных библиотек. Она оптимизирована для работы с большими объемами данных, что делает ее идеальным инструментом для подсчета длины строки в различных приложениях.
Важно помнить, что len() подсчитывает именно количество символов, а не количество байтов, которые они занимают в памяти. Это важно для работы с кодировками, где один символ может занимать больше одного байта, например, в UTF-8.
Функция len() также полезна при анализе строк в циклах, проверке ввода пользователем, а также для реализации различных алгоритмов, где важна длина строки, например, в задачах обработки текста или валидации данных.
Как посчитать количество символов в строках с пробелами и специальными символами
Для подсчета количества символов в строках с пробелами и специальными символами в Python можно использовать встроенную функцию len(). Эта функция учитывает все символы, включая пробелы, табуляции, переносы строк и другие специальные символы. Например:
text = "Привет, мир!"
length = len(text)
print(length) # Выведет 12
В примере выше строка "Привет, мир!" состоит из 12 символов, включая пробел и знак препинания. Функция len() не делает различий между буквами, пробелами и символами, она просто возвращает общее количество символов в строке.
Для работы с более сложными строками, содержащими специальные символы, такие как табуляции (\t), новые строки (\n) или юникодные символы, len() также будет учитывать их. Например, строка с несколькими пробелами и символами новой строки:
text = "Hello\tWorld\n"
length = len(text)
print(length) # Выведет 13
В данном случае \t (символ табуляции) и \n (символ новой строки) учитываются как отдельные символы. Таким образом, результат будет равен 13.
Если требуется подсчитать количество определённых символов, например, пробелов или специальных символов, можно использовать метод count() для строк. Это позволяет определить, сколько раз в строке встречается конкретный символ:
text = "a b c d e f"
space_count = text.count(' ') # Подсчитывает пробелы
print(space_count) # Выведет 5
Этот метод также работает с любыми другими символами, например, с символами новой строки или табуляции. Однако для более сложных случаев, например, когда требуется подсчитать количество определённых сочетаний символов, можно воспользоваться регулярными выражениями с модулем re.
Важно помнить, что подсчёт символов в строках зависит от кодировки, если строка состоит из символов, представленных несколькими байтами, как в случае с юникодом. В таких случаях каждый символ всё равно будет учтен, а не количество байтов. Например, юникодные символы, такие как эмодзи, также считаются одним символом, хотя могут занимать несколько байт в памяти.
Подсчет количества символов в строках с учетом Unicode
Для работы с текстом в Python чаще всего используется строковый тип данных str, который поддерживает Unicode. Важно понимать, что Unicode может включать символы, состоящие из нескольких байтов, например, эмодзи или редкие символы. Стандартная функция len() подсчитывает количество элементов в строке, но количество этих элементов может не соответствовать количеству визуально отображаемых символов, если используется многобайтовая кодировка.
Когда мы говорим о "символах", обычно имеется в виду количество видимых символов, а не количество байтов в строке. Чтобы корректно посчитать количество символов в строках с учетом Unicode, следует использовать метод len(), который работает с кодовыми точками Unicode, то есть он подсчитывает количество элементов в строке как символов.
Тем не менее, строка может содержать символы, состоящие из нескольких кодовых точек. Примером может быть комбинированные символы, такие как буква с акцентом, которая представлена двумя кодовыми точками: одна для буквы и другая для акцента. В таких случаях len() может возвращать большее значение, чем фактическое количество отображаемых символов.
Для более точного подсчета символов, учитывая многобайтовые и составные символы, можно использовать библиотеку unicodedata, которая позволяет нормализовать строку и учесть все составные символы как один.
Пример кода для подсчета реального числа символов:
import unicodedata
def count_visible_chars(text):
normalized_text = unicodedata.normalize('NFC', text)
return len(normalized_text)
text = "e\u0301" # 'e' с акцентом
print(count_visible_chars(text)) # Вернет 1, а не 2
В этом примере комбинированный символ 'e' с акцентом будет нормализован и будет подсчитан как один символ, хотя на уровне байтов это два разных элемента.
Если нужно узнать количество байтов, занимаемых строкой, следует использовать метод encode(), который преобразует строку в байты в указанной кодировке (например, UTF-8), после чего можно использовать len() для подсчета байтов.
text = "привет"
encoded_text = text.encode('utf-8')
print(len(encoded_text)) # Вернет количество байтов, необходимых для кодировки строки в UTF-8
Таким образом, выбор метода подсчета зависит от того, что именно вы хотите посчитать: визуальные символы или количество байтов, которые они занимают в памяти.
Как узнать количество символов в строках с многострочными текстами
Для работы с многострочными текстами в Python существует несколько эффективных методов подсчета символов. Основная задача – корректно обработать переносы строк и считать каждый символ, включая пробелы и знаки новой строки.
Если строка содержит несколько строк текста, их можно объединить в одну строку с помощью метода join() или использовать встроенную функцию len() напрямую на многострочной строке.
Пример с использованием обычной строки с несколькими строками:
text = """Первая строка.
Вторая строка.
Третья строка."""
В данном примере функция len() посчитает все символы, включая символы новой строки (их длина составляет 1 символ). Важно помнить, что символ новой строки может быть разным в зависимости от операционной системы – на Unix/Linux это будет \n, на Windows – \r\n.
Если необходимо учитывать только видимые символы (игнорируя переносы строк), то можно использовать метод replace() для удаления символов новой строки:
text = """Первая строка.
Вторая строка.
Третья строка."""
text_without_newline = text.replace("\n", "") # Удаление символов новой строки
Для работы с большими текстами, где важно учитывать или исключать определенные символы, можно использовать регулярные выражения с модулем re. Например, для подсчета всех букв и цифр:
import re
text = """Пример текста 123.
Еще один пример 456."""
filtered_text = re.sub(r'[^a-zA-Z0-9]', '', text) # Удаляет все, кроме букв и цифр
Этот метод позволяет точно контролировать, какие символы участвуют в подсчете, и избегать ненужных символов, таких как пробелы или знаки препинания.
Для многострочных текстов, которые поступают из файлов или ввода пользователя, важно всегда проверять, как символы новой строки обрабатываются в вашей среде, и при необходимости адаптировать код для разных операционных систем.
Как использовать метод.count() для подсчета вхождений символов в строке
Метод count() позволяет подсчитать, сколько раз конкретный символ или подстрока встречаются в строке. Это один из простых и эффективных способов получить информацию о частоте появления элементов в строках.
Основной синтаксис метода выглядит так: str.count(substring, start=0, end=len(str)). Здесь substring – это символ или подстрока, которую мы ищем, start и end – необязательные параметры, определяющие диапазон поиска в строке. Если они не указаны, поиск осуществляется по всей строке.
Пример использования:
text = "hello world"
count = text.count("o")
print(count) # Выведет: 2
В данном примере метод подсчитывает количество символов "o" в строке "hello world", результатом будет число 2.
Метод count() также может работать с подстроками. Например:
text = "abracadabra"
count = text.count("abra")
print(count) # Выведет: 2
Это позволяет искать не только одиночные символы, но и последовательности символов в строке.
Чтобы подсчитать вхождения символа в определенном диапазоне строки, можно использовать параметры start и end. Например:
text = "hello world"
count = text.count("o", 5)
print(count) # Выведет: 1
В этом примере метод ищет вхождения символа "o" только начиная с позиции 5 (включительно), что исключает первый символ "o" в строке.
Метод count() чувствителен к регистру. Это означает, что символы с разным регистром считаются разными. Например:
text = "Hello World"
count = text.count("h")
print(count) # Выведет: 0
Если необходимо выполнить поиск без учета регистра, можно привести строку и подстроку к одному регистру с помощью методов lower() или upper():
text = "Hello World"
count = text.lower().count("h")
print(count) # Выведет: 1
Использование count() эффективно при решении задач, где нужно быстро узнать, сколько раз встречается символ или подстрока в строке, с возможностью задания диапазона поиска и учета регистра.
Что делать, если строка содержит пустые символы или пробелы в начале и в конце
Когда строка в Python содержит пробелы или другие пустые символы в начале и в конце, это может повлиять на точность обработки данных. Для таких случаев предусмотрены несколько методов, позволяющих эффективно удалять лишние пробелы.
- Метод
strip() – основной инструмент для удаления пробелов с начала и конца строки. Этот метод возвращает новую строку, в которой убраны все пробелы (или другие указанные символы) с обеих сторон.
Пример:
text = " Пример строки "
clean_text = text.strip()
print(clean_text) # Выведет: Пример строки
- Метод
lstrip() – удаляет пробелы только с левой (начальной) стороны строки.
Пример:
text = " Пример строки "
clean_text = text.lstrip()
print(clean_text) # Выведет: Пример строки
- Метод
rstrip() – удаляет пробелы только с правой (конечной) стороны строки.
Пример:
text = " Пример строки "
clean_text = text.rstrip()
print(clean_text) # Выведет: Пример строки
Эти методы могут быть полезны в обработке данных, когда важно избавиться от лишних символов, не влияя на содержимое строки. Например, при обработке пользовательского ввода или работы с файлами, содержащими строки с пробелами в начале и в конце.
Если в строке нужно удалить конкретные символы (не только пробелы), можно передать их в качестве аргумента методу strip(), lstrip() или rstrip(). Например:
text = "**Пример строки**"
clean_text = text.strip('*')
print(clean_text) # Выведет: Пример строки
Таким образом, методы strip(), lstrip() и rstrip() – это простые и эффективные инструменты для удаления пустых символов и пробелов с краёв строк в Python.
Как посчитать количество символов в строках, полученных из файлов или ввода пользователя
Чтобы посчитать количество символов в строках, полученных из файлов или ввода пользователя в Python, можно использовать различные подходы. Основной инструмент для этого – функция len(), которая возвращает длину строки в символах. Для работы с файлом нужно сначала прочитать его содержимое, а затем применить len() к каждой строке или к полному содержимому файла.
Для ввода пользователя можно использовать функцию input(), которая получает строку текста, введенную пользователем. Чтобы узнать количество символов в этой строке, достаточно передать результат input() в функцию len().
Пример работы с пользовательским вводом:
user_input = input("Введите строку: ")
print("Количество символов:", len(user_input))
Если необходимо посчитать количество символов в строках, полученных из файла, можно воспользоваться следующим алгоритмом:
with open("file.txt", "r") as file:
content = file.read()
print("Общее количество символов в файле:", len(content))
Для посчета символов в каждой строке файла, можно обработать его построчно:
with open("file.txt", "r") as file:
for line in file:
print("Количество символов в строке:", len(line))
Этот метод полезен, если нужно анализировать количество символов в отдельных строках, а не в полном содержимом файла.
При работе с файлами стоит помнить, что метод read() считывает весь файл целиком в память, что может быть неэффективно при больших размерах файлов. В таких случаях лучше использовать построчное чтение с методом readline() или цикл с for.
В случае, если необходимо учесть только видимые символы (без учета пробелов и специальных символов, таких как переносы строк), можно использовать метод str.strip(), чтобы удалить лишние пробелы и символы новой строки:
cleaned_input = user_input.strip()
print("Количество символов (без пробелов):", len(cleaned_input))
Для более сложных анализов, таких как подсчет символов с учетом регистра или игнорированием определенных символов, можно воспользоваться регулярными выражениями через модуль re.
Вопрос-ответ: