В Python есть несколько эффективных способов извлечения всех ссылок с веб-страницы. Независимо от того, нужно ли вам собрать ссылки для анализа, создания базы данных или просто парсинга контента, использование библиотеки BeautifulSoup или requests является отличным выбором. В этой статье мы рассмотрим, как получить список ссылок с помощью этих инструментов, а также оптимизируем код для быстрой и точной работы с данными.
Первый шаг в получении списка ссылок – это загрузка HTML-кода страницы. Для этого достаточно использовать библиотеку requests, которая позволяет легко отправлять HTTP-запросы и получать ответы. Далее, с помощью BeautifulSoup, мы можем разобрать HTML-код и извлечь все элементы <a> с атрибутом href, который хранит ссылки.
Для обработки множества страниц и асинхронного выполнения запросов можно воспользоваться библиотеками aiohttp и asyncio. Эти инструменты позволяют ускорить процесс парсинга за счет параллельных запросов, что значительно повышает производительность при работе с большими объемами данных.
Получение ссылок с веб-страницы с помощью библиотеки BeautifulSoup
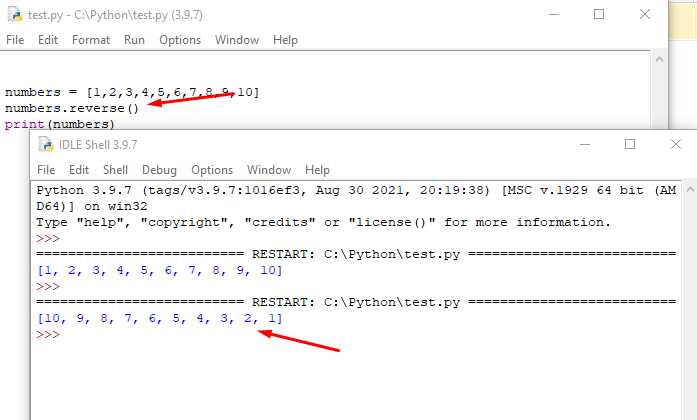
Для извлечения ссылок с веб-страницы в Python часто используют библиотеку BeautifulSoup, которая позволяет легко анализировать HTML-код и извлекать нужные данные. Чтобы начать, необходимо установить библиотеки BeautifulSoup4 и requests, если они еще не установлены:
pip install beautifulsoup4 requestsДалее, можно приступить к обработке HTML-страницы. В примере ниже мы используем requests для получения содержимого веб-страницы и BeautifulSoup для парсинга этого контента:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')Теперь, когда у нас есть объект soup, можно искать все теги <a>, которые содержат ссылки. Для этого используем метод find_all:
links = soup.find_all('a', href=True)Это вернет список всех ссылок на странице. Каждая ссылка будет представлена как объект типа Tag, и для получения самой ссылки нужно обратиться к атрибуту href:
for link in links:
print(link['href'])Если необходимо фильтровать ссылки по определенным критериям, например, искать только внешние ссылки или ссылки, содержащие определенное ключевое слово, можно использовать дополнительные условия:
external_links = [link['href'] for link in links if 'http' in link['href']]
print(external_links)Для обработки относительных ссылок, таких как /about, которые не содержат протокола и доменного имени, полезно использовать библиотеку urljoin из модуля urllib.parse:
from urllib.parse import urljoin
absolute_links = [urljoin(url, link['href']) for link in links]
print(absolute_links)Таким образом, с помощью BeautifulSoup можно не только извлечь все ссылки с веб-страницы, но и эффективно фильтровать их по различным критериям, обеспечивая гибкость в обработке данных.
Использование регулярных выражений для извлечения URL-адресов
Регулярные выражения в Python могут быть мощным инструментом для извлечения URL-адресов из текстов. С помощью модуля re можно эффективно находить все ссылки на веб-странице или в строке.
Типичный URL имеет определенную структуру, которую можно описать с помощью регулярного выражения. Важно учитывать, что URL может начинаться с разных схем, таких как http, https, ftp и другие, а также содержать различные домены и пути. Рассмотрим пример регулярного выражения для поиска URL-адресов:
import re
text = "Пример текста с ссылками: https://example.com, http://example.org, ftp://files.server.com"
pattern = r"https?://[a-zA-Z0-9.-]+(?:/[a-zA-Z0-9&%=+_-]*)?"
urls = re.findall(pattern, text)
print(urls)
В этом примере регулярное выражение r"https?://[a-zA-Z0-9.-]+(?:/[a-zA-Z0-9&%=+_-]*)?" соответствует следующим частям URL:
- https? – соответствует как http, так и https, где s? указывает на необязательность буквы «s».
- :// – разделитель схемы и домена.
- [a-zA-Z0-9.-]+ – соответствует домену, который может содержать буквы, цифры, точки и дефисы.
- (?:/[a-zA-Z0-9&%=+_-]*)? – необязательная часть, которая соответствует пути или параметрам URL, состоящим из букв, цифр и некоторых специальных символов.
Для извлечения ссылок из HTML-кода можно использовать подобное регулярное выражение, но для большей точности важно учитывать, что HTML-разметка может содержать различные атрибуты ссылок, такие как href. Для этого можно адаптировать регулярное выражение, чтобы искать только URL в тегах <a>:
pattern = r'href=["\'](https?://[a-zA-Z0-9.-]+(?:/[a-zA-Z0-9&%=+_-]*)?)["\']'
urls = re.findall(pattern, text)
В этом случае регулярное выражение будет искать значения атрибута href внутри тегов <a>, игнорируя другие возможные атрибуты или вложенные элементы.
При использовании регулярных выражений важно учитывать, что они не всегда идеально подходят для извлечения URL-адресов из сложных HTML-документов. В таких случаях предпочтительнее использовать специализированные библиотеки, такие как BeautifulSoup или lxml, которые способны корректно парсить HTML и извлекать ссылки. Тем не менее, для простых случаев регулярные выражения – это быстрый и эффективный инструмент.
Автоматизация сбора ссылок с нескольких страниц с помощью Selenium
Для начала необходимо установить Selenium и драйвер для браузера. Наиболее популярными драйверами являются ChromeDriver и GeckoDriver. Чтобы установить Selenium, выполните команду:
pip install seleniumДалее необходимо скачать подходящий драйвер для браузера и указать его путь в коде. Пример для ChromeDriver:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
После настройки драйвера можно приступить к сбору ссылок с нескольких страниц. Для этого удобно использовать цикл, который будет переходить по страницам и собирать ссылки на каждой из них.
Пример кода для сбора ссылок с нескольких страниц:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# Настройка драйвера
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
# Начальная страница
url = "https://example.com/page1"
driver.get(url)
# Список для хранения ссылок
links = []
# Количество страниц, которые нужно обработать
pages_to_scrape = 5
# Автоматизация перехода по страницам
for page in range(pages_to_scrape):
# Собираем все ссылки на текущей странице
elements = driver.find_elements(By.TAG_NAME, 'a')
for element in elements:
href = element.get_attribute('href')
if href:
links.append(href)
# Переход к следующей странице
next_button = driver.find_element(By.XPATH, '//a[@rel="next"]')
next_button.click()
# Ожидаем, пока загрузится следующая страница
time.sleep(3)
# Закрытие браузера
driver.quit()
for link in links:
print(link)
В этом примере мы проходим по страницам, начиная с первой, и собираем все ссылки, которые находятся в тегах <a>. Далее мы используем метод find_elements для нахождения всех ссылок на странице, извлекаем атрибут href и добавляем его в список. После сбора ссылок с текущей страницы выполняется переход к следующей с помощью кнопки «Next», которая в данном примере находится по XPath //a[@rel="next"].
Важно: при работе с Selenium нужно учитывать динамическую загрузку контента, что может потребовать использования явных или неявных ожиданий. Явные ожидания позволяют дождаться загрузки элементов, чтобы избежать ошибок при попытке взаимодействия с ними до полной загрузки.
Пример с явным ожиданием:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Ожидание загрузки кнопки "Next"
next_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//a[@rel="next"]'))
)
next_button.click()
Этот код гарантирует, что программа подождет 10 секунд, пока кнопка «Next» не станет доступной для клика.
С помощью Selenium можно эффективно собирать ссылки с различных страниц, управлять динамическим контентом и обрабатывать сайты, которые требуют взаимодействия с элементами JavaScript. Тем не менее, необходимо соблюдать осторожность, чтобы не перегрузить сервер запросами и не нарушать правила использования веб-ресурсов.
Как извлечь ссылки из HTML-файла без подключения к сети
Для работы с локальными HTML-файлами используем Python-библиотеку BeautifulSoup, которая позволяет парсить и анализировать HTML-документы. Предварительно установим библиотеку:
pip install beautifulsoup4Далее создадим скрипт для извлечения всех ссылок:
from bs4 import BeautifulSoup
# Открытие локального HTML-файла
with open("your_file.html", "r", encoding="utf-8") as file:
soup = BeautifulSoup(file, "html.parser")
# Поиск всех тегов и извлечение атрибутов href
links = [a['href'] for a in soup.find_all('a', href=True)]
for link in links:
print(link)
В этом коде:
- Открываем локальный файл с помощью функции
open()и передаем его содержимое в BeautifulSoup для парсинга. - Метод
find_all()находит все теги<a>, а параметрhref=Trueгарантирует, что будут извлечены только те теги<a>, которые содержат атрибутhref.
Если необходимо извлечь только абсолютные ссылки, можно дополнительно проверить, начинается ли значение атрибута href с «http» или «https». Это поможет отфильтровать только внешние ссылки:
absolute_links = [link for link in links if link.startswith("http")]
Если нужно извлечь ссылки с определенных частей HTML-документа, например, из таблиц или div-элементов, можно использовать дополнительные параметры метода find_all(), такие как class_ или id, для более точной выборки.
После извлечения всех ссылок, можно сохранить их в текстовый файл для дальнейшего использования или анализа. Для этого достаточно добавить следующий код:
with open("links.txt", "w", encoding="utf-8") as output_file:
for link in links:
output_file.write(link + "\n")
Таким образом, извлечение ссылок из локального HTML-файла с помощью Python не требует подключения к сети и может быть выполнено быстро и эффективно с помощью библиотеки BeautifulSoup.
Парсинг ссылок с использованием библиотеки Requests и lxml
Для парсинга ссылок с веб-страниц можно эффективно использовать библиотеки Requests и lxml. Requests помогает получить HTML-контент, а lxml – извлечь из него нужные данные, включая ссылки.
Основные этапы работы:
- Получение HTML-страницы с помощью Requests.
- Обработка контента с использованием lxml для извлечения всех ссылок.
Пример кода:
import requests
from lxml import html
url = 'https://example.com'
response = requests.get(url)
tree = html.fromstring(response.content)
links = tree.xpath('//a/@href')
В данном примере:
- Мы отправляем GET-запрос с помощью
requests.get(url)для получения HTML-контента страницы. - Получаем дерево элементов с использованием
html.fromstring(response.content), что позволяет работать с HTML как с объектной моделью. - Извлекаем все ссылки с помощью выражения XPath
tree.xpath('//a/@href'), где//aнаходит все теги , а@hrefвыбирает атрибутhref.
Результат – это список ссылок на странице. Если вам нужно фильтровать только абсолютные URL-адреса, можно использовать библиотеку urllib.parse.
Пример фильтрации абсолютных ссылок:
from urllib.parse import urljoin
absolute_links = [urljoin(url, link) for link in links if link.startswith('http')]
В этом примере urljoin(url, link) автоматически превращает относительные ссылки в абсолютные, добавляя к ним основной URL.
Также стоит учитывать возможные ошибки при запросах, такие как тайм-ауты или неправильные коды ответа. Для этого можно добавить обработку исключений:
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Ошибка при запросе: {e}")
Таким образом, используя Requests для получения данных и lxml для парсинга, можно быстро извлечь все ссылки с веб-страницы и обрабатывать их в соответствии с нуждами проекта.
Извлечение ссылок из динамических сайтов с использованием API
Динамические сайты часто генерируют контент с помощью JavaScript, что делает стандартный парсинг HTML-кода недостаточно эффективным. В таких случаях для извлечения ссылок можно использовать API сайта, если оно доступно. Этот подход позволяет получать данные напрямую, минуя сложность обработки динамического контента.
Прежде чем начать, необходимо понять, как работает API на целевом сайте. Часто API предоставляет данные в формате JSON или XML, включая все необходимые ссылки и другую информацию. Чтобы найти правильные эндпоинты, можно использовать инструменты разработчика в браузере, такие как вкладка «Network» в Google Chrome или Firefox.
Шаги для извлечения ссылок:
-
Определение эндпоинта API: Используйте вкладку «Network» для мониторинга запросов, отправляемых сайтом. Ищите запросы, которые возвращают данные, связанные с контентом страницы (например, запросы к REST API).
-
Анализ структуры данных: Получив ответ от API, изучите его структуру. Обычно ссылки находятся в полях типа «href», «url» или могут быть частью других объектов, например, «data» или «links».
-
Отправка запросов через Python: Для работы с API используйте библиотеку requests. Пример запроса:
import requests response = requests.get('https://example.com/api/endpoint') data = response.json() Извлечение ссылок links = [item['url'] for item in data['items'] if 'url' in item] -
Обработка полученных данных: После того как ссылки извлечены, можно фильтровать и сохранять их в нужном формате. Например, для уникальных ссылок используйте Python-метод set() для исключения повторений.
Если API требует аутентификацию, используйте соответствующие методы для передачи токенов или ключей доступа. В этом случае также может понадобиться добавить заголовки в запрос, например:
headers = {'Authorization': 'Bearer YOUR_API_KEY'}
response = requests.get('https://example.com/api/endpoint', headers=headers)
Применяя этот метод, можно эффективно извлекать ссылки из динамических сайтов, избегая необходимости парсить JavaScript-код.