В Python списки представляют собой универсальные структуры данных, однако при выполнении численных вычислений они уступают по эффективности массивам библиотеки NumPy. Преобразование списка в массив позволяет значительно ускорить операции над большими объемами данных за счёт векторизации и специализированных реализаций на уровне C.
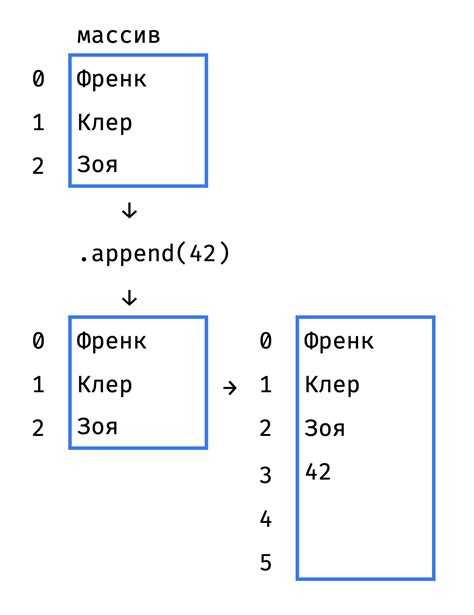
Для преобразования стандартного списка Python в массив NumPy используется функция numpy.array(). Например, вызов numpy.array([1, 2, 3]) создаёт одномерный массив целых чисел. При этом важно учитывать тип элементов: если список содержит смешанные типы, NumPy произведёт автоматическое приведение к одному типу, что может повлиять на точность и производительность.
Если работа требует массивов фиксированного типа (например, float32 или int16), тип следует указывать явно с помощью параметра dtype: numpy.array([1, 2, 3], dtype=’float32′). Это особенно важно при работе с большими объёмами данных или при подготовке входных данных для нейросетей, где типы строго контролируются.
Преобразование списков вложенной структуры позволяет создавать многомерные массивы. Например, список вида [[1, 2], [3, 4]] преобразуется в двумерный массив размером 2×2. Однако при несогласованной вложенности ([[1, 2], [3]]) NumPy создаст массив с типом object, что сведёт на нет все преимущества использования массивов.
Использование массивов вместо списков оправдано в задачах численного анализа, обработки изображений и работы с временными рядами. Выбор правильного подхода и понимание механизма преобразования критически важны для повышения производительности и надёжности кода.
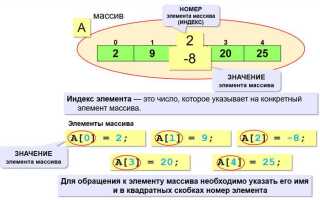
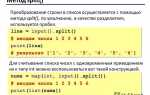
Как преобразовать список в массив с помощью модуля array
Модуль array из стандартной библиотеки Python предназначен для создания массивов с фиксированным типом данных. Для преобразования списка в массив необходимо указать тип элементов и сам список при создании массива.
Импортируйте модуль: import array. Укажите код типа, например, 'i' для целых чисел или 'f' для чисел с плавающей точкой. Пример: arr = array.array('i', [1, 2, 3, 4]). Передаваемый список должен содержать только элементы, совместимые с выбранным типом. В противном случае возникнет TypeError.
Массивы, созданные с помощью array, используют меньше памяти по сравнению со списками. Это особенно актуально при работе с большими объемами числовых данных. Однако массивы поддерживают ограниченное количество типов, указанных в документации к модулю.
Для конвертации списка строк или смешанных типов модуль array не подходит. В таких случаях используйте альтернативы, например, numpy.
Преобразование списка в массив NumPy для численных вычислений

Модуль numpy предоставляет структуру ndarray, оптимизированную для векторных операций и работы с многомерными данными. Преобразование стандартного списка Python в массив NumPy позволяет использовать матричную алгебру, трансформации, агрегации и функции линейной алгебры с высокой производительностью.
Для преобразования достаточно передать список в функцию numpy.array():
import numpy as np
lst = [1, 2, 3, 4]
arr = np.array(lst)Если список содержит вложенные списки одинаковой длины, создаётся двумерный массив:
matrix = np.array([[1, 2], [3, 4]])Тип данных задаётся аргументом dtype, чтобы избежать автоматического приведения типов:
float_arr = np.array([1, 2, 3], dtype=np.float64)Преобразование ускоряет численные операции. Пример умножения на скаляр:
np.array([1, 2, 3]) * 10 # результат: array([10, 20, 30])В отличие от списков, NumPy-массивы позволяют использовать широкие возможности библиотеки:
- векторизация без циклов
- булевую индексацию и маскирование
- агрегирующие функции:
mean(),sum(),std() - функции линейной алгебры:
dot(),linalg.inv(),eig()
При передаче объекта с неоднородной структурой (например, вложенных списков разной длины) создаётся массив с типом object, что лишает преимуществ NumPy:
np.array([[1, 2], [3]]) # результат: array([list([1, 2]), list([3])], dtype=object)Для стабильной работы с числовыми вычислениями массив должен быть прямоугольным, типизированным и содержать числовые значения.
Как указать тип данных при создании массива из списка
Для создания массива с явным указанием типа данных используется функция numpy.array() с параметром dtype. Это позволяет контролировать объём памяти и поведение при арифметических операциях.
Например, чтобы преобразовать список целых чисел в массив 32-битных целых чисел, передайте dtype=numpy.int32:
import numpy as np
lst = [1, 2, 3]
arr = np.array(lst, dtype=np.int32)Для вещественных чисел: dtype=np.float64. Это обеспечит двойную точность вычислений:
arr = np.array([1.1, 2.2, 3.3], dtype=np.float64)При необходимости использования комплексных чисел – dtype=np.complex128. Это полезно в задачах, связанных с преобразованием Фурье и линейной алгеброй:
arr = np.array([1, 2], dtype=np.complex128)Для логических значений применяйте dtype=np.bool_. Такой массив экономно расходует память при работе с булевыми масками:
arr = np.array([True, False, True], dtype=np.bool_)Указание dtype критично при необходимости точного сопоставления с внешними бинарными форматами или при сериализации данных. Несоответствие типов может привести к потере точности или ошибкам выполнения.
Обработка вложенных списков при преобразовании в многомерные массивы
Для корректного преобразования вложенных списков в многомерные массивы с использованием библиотеки NumPy необходимо учитывать форму (shape) данных и их однородность.
- Перед преобразованием проверьте, что все вложенные списки имеют одинаковую длину. NumPy требует строго прямоугольную структуру.
- Используйте функцию
numpy.array()только с выровненными по длине подсписками, иначе массив будет создан с типомdtype=object, что лишает преимуществ работы с NumPy. - Для диагностики можно использовать генераторы списков:
all(len(row) == len(data[0]) for row in data)Это вернёт
Trueтолько при корректной вложенной структуре. - Если структура вложенных списков неоднородна, применяйте
numpy.padилиitertools.zip_longestдля выравнивания, но это увеличит объём памяти и требует заполнителя (например,np.nan). - Для многоуровневой вложенности (3D и более) убедитесь, что каждый уровень одинаков по размеру, иначе NumPy не создаст многомерный массив автоматически.
- Проверьте длину всех подсписков.
- Выравнивайте структуру при необходимости.
- Создайте массив:
array = numpy.array(data). - Проверьте форму:
array.shape.
Игнорирование этих правил приводит к некорректной интерпретации данных и ошибкам в расчетах, особенно при векторизации и использовании матричных операций.
Преобразование списка строк в массив байтов
Чтобы преобразовать строку в байты, необходимо учесть, что строки в Python хранятся в виде символов в кодировке Unicode, а байты представляют собой последовательность чисел от 0 до 255. Для этого используется метод encode(), который позволяет выбрать кодировку, например, UTF-8.
Пример преобразования одной строки в массив байтов:
s = "Пример"
byte_array = s.encode('utf-8')
print(byte_array)
Теперь рассмотрим, как можно преобразовать список строк в массив байтов. Важно помнить, что для каждого элемента списка будет выполнено преобразование строки в байты.
Основной способ – это применение генераторов или списковых выражений для преобразования всех строк списка в байты:
strings = ["Привет", "мир", "Python"]
byte_array = [s.encode('utf-8') for s in strings]
print(byte_array)
В данном случае список strings будет преобразован в список байтов, где каждый элемент представляет собой байтовое представление строки.
Если нужно получить единую последовательность байтов из нескольких строк, можно использовать метод join() для объединения всех строк в одну перед их кодированием:
strings = ["Привет", "мир", "Python"]
combined_string = ''.join(strings)
byte_array = combined_string.encode('utf-8')
print(byte_array)
В результате получится один массив байтов, включающий все строки списка.
Для работы с различными кодировками, такими как ASCII или UTF-16, достаточно изменить аргумент в методе encode(). Например, для кодировки ASCII:
s = "Hello"
byte_array = s.encode('ascii')
print(byte_array)
Особое внимание стоит уделить кодировкам, поддерживающим многобайтовые символы, например, UTF-8, где для каждого символа может быть использовано от 1 до 4 байтов. Если строки содержат символы, не поддерживаемые выбранной кодировкой, будет выброшено исключение, которое необходимо обрабатывать.
В случае работы с большими объемами данных может быть полезно использовать буферизацию, например, через io.BytesIO, чтобы избежать переполнения памяти и ускорить процесс обработки данных.
Таким образом, преобразование списка строк в массив байтов – это простая задача, которая решается через стандартные функции Python, но требует внимания к выбору кодировки и обработке ошибок при преобразовании. Для удобства работы с большими списками можно использовать генераторы или другие структуры данных для эффективной обработки информации.
Как избежать ошибок при преобразовании неоднородных списков
При преобразовании неоднородных списков в массивы с использованием библиотеки NumPy важно учитывать типы данных в списке. Если элементы списка имеют разные типы (например, числа и строки), это может привести к неожиданным результатам, так как NumPy по умолчанию приводит все элементы к одному типу, обычно к строкам.
Чтобы избежать ошибок при таком преобразовании, сначала нужно проверить типы всех элементов в списке. Для этого можно использовать функцию type() для каждого элемента. Если типы элементов в списке различаются, стоит преобразовать их в единый тип вручную, например, с помощью функции map() или явного приведения типов.
Другим подходом является предварительная фильтрация элементов списка, чтобы исключить несовместимые типы. Например, можно использовать list comprehension для отбора только числовых значений или строковых значений в зависимости от цели преобразования. В случае с числами, фильтрация может быть выполнена с помощью функции isinstance(), проверяя, являются ли элементы числами перед преобразованием.
Еще одной потенциальной проблемой является наличие None или других «пустых» значений в списке. Это может вызвать ошибки при попытке привести такие значения к числовым типам. Для решения этой проблемы перед преобразованием списка в массив необходимо заменить или удалить такие элементы.
Если необходимо работать с неоднородными списками, где элементы могут быть как числами, так и строками, следует заранее определить, какой тип данных требуется для дальнейшей работы, и привести все элементы к этому типу. Например, если нужно создать массив с целыми числами, можно использовать int() для всех элементов, которые могут быть преобразованы в целые числа, или отфильтровать те, которые не могут быть приведены к нужному типу.
Также стоит помнить, что NumPy может не всегда корректно обрабатывать сложные структуры данных, такие как вложенные списки с различными типами. В таких случаях целесообразно сначала выровнять структуру данных или использовать более специализированные подходы, например, сериализацию данных или использование других библиотек для работы с массивами.