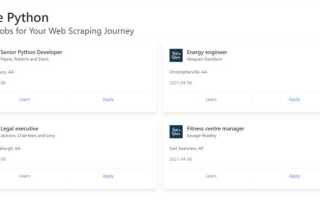
Парсинг HTML с помощью Python – это один из самых эффективных способов извлечения информации с веб-страниц. Библиотеки, такие как BeautifulSoup и lxml, предоставляют мощные инструменты для анализа структуры HTML-документа и выборки нужных данных. Это особенно полезно при работе с большими объемами информации или при необходимости автоматизировать сбор данных с различных сайтов.
Одной из популярных библиотек для парсинга является BeautifulSoup, которая позволяет легко работать с HTML и XML. Она позволяет трансформировать HTML-документ в удобную для манипуляции структуру, поддерживая методы поиска элементов по тегам, классам и идентификаторам. В отличие от стандартного Python-модуля html.parser, BeautifulSoup обеспечивает более высокую гибкость и устойчивость к ошибкам в HTML.
Для более быстрой обработки больших документов можно использовать lxml. Это одна из самых быстрых библиотек для парсинга, которая поддерживает как HTML, так и XML. lxml оптимизирован для работы с большими файлами и способен эффективно работать с деревьями элементов, что делает его идеальным для сложных и многослойных документов. Однако стоит учитывать, что для работы с lxml потребуется дополнительная установка, так как эта библиотека не входит в стандартную поставку Python.
Процесс парсинга включает несколько этапов: загрузка HTML-документа, анализ его структуры и извлечение нужных данных. При этом важно учитывать особенности структуры HTML, такие как вложенные теги или динамически загружаемые элементы. Чтобы гарантировать правильную обработку всех данных, рекомендуется использовать методы поиска по CSS-селекторам или XPath, которые дают точное и эффективное извлечение элементов.
Важно также помнить об этических аспектах веб-скрапинга. Прежде чем приступить к сбору данных с сайта, всегда проверяйте его robots.txt и ознакомьтесь с условиями использования данных. Неконтролируемое парсинг может нарушать права владельцев контента, поэтому всегда важно соблюдать баланс между автоматизацией и законностью.
Как установить и настроить библиотеки для парсинга HTML
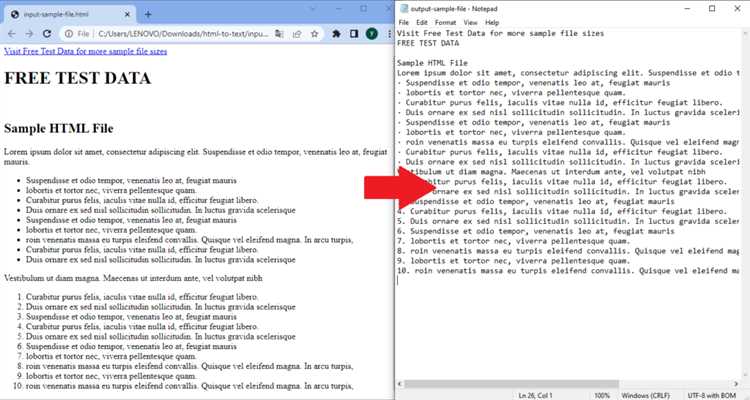
Для эффективного парсинга HTML в Python рекомендуется использовать библиотеки BeautifulSoup и lxml. Эти инструменты позволяют легко извлекать данные из HTML-документов и работать с их структурой.
BeautifulSoup – это библиотека, предназначенная для удобного парсинга HTML и XML документов. Она работает с разными парсерами, такими как html.parser (встроенный в Python) и lxml.
Чтобы установить BeautifulSoup, выполните команду:
pip install beautifulsoup4
Для работы с BeautifulSoup потребуется также установить библиотеку lxml или html5lib, если вы планируете использовать эти парсеры. Они обеспечивают более быстрый и гибкий парсинг по сравнению с встроенным html.parser.
Для установки lxml, используйте команду:
pip install lxml
Для установки html5lib, используйте команду:
pip install html5lib
Кроме того, библиотека requests полезна для загрузки HTML-страниц, так как она обеспечивает удобный интерфейс для работы с HTTP-запросами. Установить requests можно так:
pip install requests
После установки библиотек, настройте код для парсинга HTML-документа. Пример использования BeautifulSoup с парсером lxml:
from bs4 import BeautifulSoup import requests url = "https://example.com" response = requests.get(url) soup = BeautifulSoup(response.content, "lxml") print(soup.prettify())
Этот код загружает HTML-страницу по указанному URL и парсит её содержимое с помощью BeautifulSoup и lxml.
Чтобы добиться максимальной производительности, важно всегда использовать наиболее подходящий парсер. lxml быстрее и эффективнее для больших документов, но если важна совместимость и простота, html.parser может быть хорошим выбором.
Как использовать BeautifulSoup для извлечения данных из HTML
Для парсинга документа с помощью BeautifulSoup, первым шагом является создание объекта BeautifulSoup, передав ему HTML-код. Например, можно использовать модуль requests для загрузки страницы и затем передать её в BeautifulSoup:
import requests
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'html.parser')
После создания объекта soup можно извлекать элементы с помощью различных методов библиотеки.
Для извлечения элементов по тегам используется метод find(). Например, чтобы получить первый заголовок h1, следует написать:
h1 = soup.find('h1')
print(h1.text)
Если нужно извлечь все элементы определённого типа, применяется метод find_all(). Например, для получения всех ссылок a на странице:
links = soup.find_all('a')
for link in links:
print(link.get('href'))
Иногда полезно фильтровать элементы по атрибутам. Для этого передайте в метод find() или find_all() дополнительные параметры. Например, чтобы найти все a с атрибутом class='nav-link':
links = soup.find_all('a', class_='nav-link')
for link in links:
print(link.get('href'))
Для извлечения текста внутри элемента используется атрибут .text, как показано в примере с тегом h1 выше. Если нужно получить текст из нескольких вложенных элементов, можно воспользоваться методом get_text():
text = soup.get_text()
print(text)
Кроме того, можно использовать CSS-селекторы через метод select(). Этот метод позволяет выбирать элементы по классам, ID и другим атрибутам, аналогично работе с CSS в браузере:
paragraphs = soup.select('p.intro')
for paragraph in paragraphs:
print(paragraph.text)
Важно помнить, что BeautifulSoup автоматически исправляет ошибки в HTML и пытается интерпретировать даже некорректно написанные страницы. Однако для работы с большими объёмами данных или страницами с плохой структурой стоит использовать дополнительные настройки парсинга или другие инструменты, такие как lxml, который можно подключить в качестве парсера:
soup = BeautifulSoup(response.text, 'lxml')
Таким образом, BeautifulSoup предоставляет мощный и гибкий инструментарий для извлечения данных из HTML-документов с минимальными усилиями.
Как извлечь текст и ссылки из HTML-страницы
Для извлечения текста и ссылок из HTML-страницы часто используется библиотека BeautifulSoup, которая позволяет эффективно работать с HTML-разметкой. В данном разделе рассмотрим, как извлечь текстовые данные и ссылки с помощью Python.
Для начала установим необходимые библиотеки:
pip install requests beautifulsoup4Сначала загружаем HTML-контент страницы с помощью библиотеки requests:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
html_content = response.textТеперь, чтобы извлечь весь текст с HTML-страницы, используем метод get_text() из BeautifulSoup. Он удаляет все HTML-теги, оставляя только текстовое содержание:
soup = BeautifulSoup(html_content, 'html.parser')
text = soup.get_text()
print(text)Для получения только ссылок используем метод find_all('a'), который извлекает все теги , содержащие ссылки. Далее, чтобы получить саму ссылку, обращаемся к атрибуту href каждого тега:
links = soup.find_all('a')
for link in links:
href = link.get('href')
if href:
print(href)При работе с ссылками полезно проверять, что атрибут href действительно существует, поскольку некоторые теги могут не содержать ссылки.
Если нужно извлечь ссылки, которые ведут на внешние ресурсы (например, начинаются с «http»), можно отфильтровать их с помощью простой проверки:
external_links = [link.get('href') for link in links if link.get('href') and link.get('href').startswith('http')]
print(external_links)Для более точного парсинга, если на странице есть специфические блоки с нужным содержанием (например, только статьи или разделы с ссылками), можно использовать метод find_all с фильтрацией по классам или id:
articles = soup.find_all('div', class_='article')
for article in articles:
print(article.get_text())Таким образом, для извлечения текста и ссылок из HTML-страницы важно четко понимать структуру документа и использовать соответствующие методы для поиска нужных данных.
Как работать с аттрибутами HTML-элементов
При парсинге HTML с помощью Python, доступ к аттрибутам элементов можно получить с использованием библиотеки BeautifulSoup. Аттрибуты HTML-элементов хранятся в виде словаря, и для работы с ними нужно использовать несколько базовых методов.
Чтобы извлечь аттрибут элемента, можно использовать метод get. Например, если нужно получить значение аттрибута href у тега a, это можно сделать так:
a_tag = soup.find('a')
href_value = a_tag.get('href')
Метод get вернет значение аттрибута или None, если аттрибут не существует. Это удобно, чтобы избежать ошибок при отсутствии аттрибута.
Для изменения аттрибута элемента используется запись вида: element['attribute'] = new_value. Например, если нужно изменить ссылку на другую, можно сделать так:
a_tag['href'] = 'https://newlink.com'
Если необходимо получить все аттрибуты элемента, можно обратиться к attrs. Этот аттрибут возвращает словарь, в котором ключами являются имена аттрибутов, а значениями – их содержимое:
a_tag_attrs = a_tag.attrs
Чтобы найти элементы с определенным аттрибутом, используйте метод find_all с аргументом attrs. Например, для поиска всех ссылок с аттрибутом class, равным «external», можно сделать так:
external_links = soup.find_all('a', class_='external')
Если аттрибут может содержать несколько значений (например, в случае class или style), можно использовать регулярные выражения для более точного поиска. Для этого используется модуль re, который позволяет искать элементы с частичным совпадением значений аттрибутов:
import re
class_links = soup.find_all('a', class_=re.compile('^external'))
Стоит помнить, что аттрибуты могут быть необязательными или иметь дефолтные значения. При парсинге таких элементов важно учитывать возможное отсутствие аттрибутов, чтобы избежать ошибок в коде. Лучшей практикой является использование метода get с проверкой на None перед дальнейшими действиями с аттрибутами.
Как обрабатывать данные из таблиц и списков HTML
Для извлечения данных из HTML-таблиц и списков чаще всего используют библиотеку BeautifulSoup. С помощью неё можно легко парсить содержимое тегов <table>, <tr>, <td>, <ul>, <ol>, <li>. Рассмотрим, как обрабатывать эти элементы с помощью Python.
Таблицы HTML
Таблицы HTML обычно состоят из строк (<tr>) и ячеек (<td>). Чтобы получить доступ к данным в таблице, сначала извлекаем саму таблицу, а затем обрабатываем строки и ячейки.
Пример кода для извлечения данных из таблицы:
from bs4 import BeautifulSoup
html = '''
Имя Возраст Иван 25 Мария 30
'''
soup = BeautifulSoup(html, 'html.parser')
table = soup.find('table')
rows = table.find_all('tr')
for row in rows[1:]: # Пропускаем заголовок
cols = row.find_all('td')
name = cols[0].text
age = cols[1].text
print(f'Имя: {name}, Возраст: {age}')
Списки HTML
Списки могут быть ненумерованными (<ul>) или нумерованными (<ol>). Элементы списка обозначаются тегами <li>. Чтобы извлечь все элементы списка, нужно сначала найти контейнер списка, а затем все элементы внутри него.
Пример кода для обработки списка:
html = '''
- Яблоки
- Бананы
- Груши
'''
soup = BeautifulSoup(html, 'html.parser')
ul = soup.find('ul')
items = ul.find_all('li')
for item in items:
print(item.text)
Обработка сложных таблиц и списков
Если таблица или список имеют вложенные элементы или дополнительные атрибуты, например, class, можно использовать дополнительные фильтры поиска в BeautifulSoup. Например, чтобы получить только те строки таблицы, в которых указаны определённые значения, можно использовать метод find_all() с параметрами поиска по атрибутам:
table = soup.find('table', class_='data')
rows = table.find_all('tr', class_='highlight')
При работе с большими данными стоит учитывать оптимизацию парсинга, чтобы избежать излишней загрузки памяти или длительного времени выполнения. Лучше ограничивать область поиска, используя фильтрацию по тегам и атрибутам.
Как автоматизировать парсинг данных с помощью Python
Автоматизация парсинга данных с помощью Python позволяет эффективно извлекать информацию с веб-страниц без необходимости вручную искать нужные данные. В этом процессе важную роль играют библиотеки, такие как BeautifulSoup, Requests и Selenium, которые позволяют создавать скрипты для регулярного и автоматизированного парсинга данных.
Для начала необходимо определиться с библиотеками, которые будут использоваться для парсинга:
- Requests – для отправки HTTP-запросов и получения HTML-страниц.
- BeautifulSoup – для удобного извлечения данных из HTML-кода.
- Selenium – если необходимо взаимодействовать с динамическим контентом, который загружается с помощью JavaScript.
Пример простого автоматизированного парсинга с использованием библиотеки Requests и BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Извлечение всех ссылок на странице
links = soup.find_all('a')
for link in links:
print(link.get('href'))
Важным моментом является настройка автоматической обработки ошибок, например, если страница не доступна или структура HTML-кода изменилась. Это можно сделать с помощью конструкций try-except и проверки статуса ответа:
try:
response = requests.get(url)
response.raise_for_status() # Проверка на успешный ответ (код 200)
except requests.exceptions.RequestException as e:
print(f'Ошибка при запросе: {e}')
else:
soup = BeautifulSoup(response.text, 'html.parser')
# Дальнейший парсинг...
Если необходимо парсить динамический контент, который генерируется JavaScript, можно использовать Selenium. Она позволяет взаимодействовать с браузером, эмулировать действия пользователя и извлекать данные из динамических страниц:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://example.com')
# Ожидание загрузки контента
driver.implicitly_wait(5)
# Извлечение данных
element = driver.find_element(By.CLASS_NAME, 'some-class')
print(element.text)
driver.quit()
Для автоматизации процесса парсинга на регулярной основе, например, для сбора данных каждый день, можно использовать планировщики задач, такие как cron на Linux или Task Scheduler на Windows. Также можно интегрировать парсинг в более сложные системы с использованием библиотек для работы с базами данных (например, SQLite или MySQL), что позволит сохранять данные в структурированном виде для дальнейшего анализа.
Для управления многими задачами парсинга удобно использовать Celery, который позволяет асинхронно выполнять парсинг в фоновом режиме, распределяя нагрузку между несколькими воркерами.
Основные рекомендации при автоматизации парсинга:
- Планируйте регулярные обновления данных с учетом ограничений сайта (например, частота запросов).
- Не забывайте про соблюдение правил robots.txt, чтобы избежать блокировки со стороны веб-ресурса.
- Для больших объемов данных используйте многозадачность или параллельную обработку, например, с библиотеками multiprocessing или concurrent.futures.
Автоматизированный парсинг с Python позволяет существенно упростить сбор данных, снизить трудозатраты и повысить точность извлечения информации. Главное – обеспечить стабильность работы системы и соблюдение всех юридических аспектов при сборе данных с веб-сайтов.