Работа с текстовыми данными в Python часто включает задачу их разбора или парсинга. Преобразование строк в структуру, удобную для дальнейшей обработки, является неотъемлемой частью программирования. В Python для этих целей существуют различные методы и инструменты, каждый из которых подходит для конкретных задач.
Одним из самых популярных способов является использование регулярных выражений через модуль re. Этот инструмент позволяет эффективно находить, заменять и извлекать данные из строки по заданному шаблону. Регулярные выражения полезны, когда структура строки заранее неизвестна или требует поиска определённых шаблонов. В Python они поддерживаются в стандартной библиотеке, и освоение их синтаксиса значительно ускоряет процесс парсинга.
Если задача требует простого разделения строки на отдельные части, можно воспользоваться встроенными методами строк, такими как split() или partition(). Эти функции позволяют легко работать с разделителями, будь то пробелы, запятые или другие символы. Важно помнить, что split() делит строку по указанному разделителю, в то время как partition() предоставляет три компонента: строку до разделителя, сам разделитель и строку после него, что может быть полезно для точного разбора данных.
Для более сложных случаев, например, когда нужно распарсить строку в формат JSON или CSV, Python предоставляет библиотеки json и csv. Эти модули идеально подходят для обработки структурированных данных, которые часто встречаются в приложениях, работающих с внешними API или файлами. Преимущество этих библиотек заключается в том, что они берут на себя все особенности форматов, избавляя разработчика от необходимости вручную разбирать данные.
Для оптимизации процесса парсинга также можно использовать сторонние библиотеки, такие как pandas для работы с табличными данными или BeautifulSoup для парсинга HTML. Эти библиотеки предлагают более высокоуровневые абстракции, которые позволяют фокусироваться на решении задач, а не на низкоуровневых аспектах обработки строк.
Использование метода split() для разбиения строки по разделителю
Метод split() в Python позволяет разделить строку на несколько частей, используя заданный разделитель. Это один из наиболее часто используемых инструментов для обработки текстовых данных.
Основной синтаксис метода следующий:
str.split(separator, maxsplit)Здесь separator – это строка, по которой будет происходить разбиение, а maxsplit ограничивает количество разделений (если параметр не указан, разбиение происходит на все возможные части). Если разделитель не передан, метод использует пробелы по умолчанию.
Пример:
text = "apple,banana,orange"
result = text.split(',')
print(result) # ['apple', 'banana', 'orange']
Метод split() полезен, когда необходимо извлечь данные, разделённые конкретными символами, например, при обработке CSV-файлов или URL-адресов.
Особенности:
- Пробелы как разделитель: Если разделитель не указан, метод разделит строку по любым пробельным символам (включая табуляцию и переносы строк). Например,
"Hello world".split()вернёт['Hello', 'world']. - Пустые строки: Если в строке два одинаковых разделителя подряд, метод вставит пустую строку между элементами. Пример:
"apple,,banana".split(',')вернёт['apple', '', 'banana']. - Использование maxsplit: Этот параметр позволяет ограничить количество разделений. Например,
"apple,banana,orange".split(',', 1)вернёт['apple', 'banana,orange'].
Практическое применение:
Метод split() часто используется для обработки строк в логах, разбора текстовых файлов и при подготовке данных для анализа. Важно учитывать, что разделитель может быть строкой любой длины, а не только символом. Например, можно разделить строку по нескольким пробелам или табуляциям.
При работе с большим объёмом данных стоит внимательно следить за производительностью, так как частое использование split() может приводить к избыточным операциям, если строки содержат большое количество разделителей. В таких случаях полезно ограничить количество разбиений с помощью параметра maxsplit.
Применение регулярных выражений с модулем re

Модуль re предоставляет мощные инструменты для работы с регулярными выражениями в Python. Регулярные выражения позволяют искать, заменять или извлекать данные из строк с использованием шаблонов. Это значительно упрощает обработку строк, особенно при необходимости работать с повторяющимися или сложными структурами данных.
Для начала работы с регулярными выражениями необходимо импортировать модуль re. Основные операции с регулярными выражениями включают поиск с помощью re.search(), поиск всех вхождений через re.findall() и замену с использованием re.sub().
Пример поиска первого вхождения строки:
import re
pattern = r'\d+' # Шаблон для поиска числа
text = 'У меня есть 15 яблок и 30 бананов'
match = re.search(pattern, text)
if match:
Функция re.search() возвращает первый найденный результат, который соответствует шаблону. Важно использовать метод group(), чтобы получить саму строку, совпавшую с регулярным выражением.
Поиск всех вхождений:
matches = re.findall(r'\d+', text)
Для получения всех вхождений строки, подходящих под регулярное выражение, используется re.findall(). Эта функция возвращает список всех совпадений.
Замена в строке:
new_text = re.sub(r'\d+', 'X', text)
Метод re.sub() заменяет все совпадения в строке на указанный текст. Этот метод полезен для очистки или изменения строк, которые содержат динамические данные.
Использование флагов:
Модуль re поддерживает флаги, которые позволяют модифицировать поведение регулярных выражений. Например, флаг re.IGNORECASE игнорирует регистр символов:
pattern = r'яблок'
text = 'У меня есть Яблоки и бананы'
match = re.search(pattern, text, re.IGNORECASE)
if match:
Использование групп и подстановок:
Группы в регулярных выражениях позволяют выделить части шаблона. В Python можно извлечь значения с помощью круглых скобок в регулярном выражении. Пример:
pattern = r'(\d+)\s+яблок'
text = 'У меня есть 15 яблок и 30 бананов'
match = re.search(pattern, text)
if match:
Здесь (\d+) представляет группу, и group(1) извлекает значение этой группы.
Рекомендации:
- Используйте
re.match()для проверки начала строки на соответствие шаблону. - Будьте осторожны с производительностью при работе с большими строками или множественными операциями замены.
- Тестируйте регулярные выражения с помощью онлайн-редакторов, чтобы избегать ошибок в сложных шаблонах.
Парсинг строк с помощью метода find() и findall()
Методы find() и findall() в Python широко используются для поиска подстрок внутри строк. Несмотря на схожесть их названий, эти методы имеют ключевые отличия в применении и функционале.
find() применяется для нахождения первого вхождения подстроки в строку. Этот метод возвращает индекс первого символа найденной подстроки или -1, если подстрока не найдена.
text = "Пример строки с данными."
index = text.find("строки")
print(index) # Выведет: 7
В случае, если подстрока отсутствует в строке, find() возвращает -1:
index = text.find("нет")
print(index) # Выведет: -1
findall() является частью модуля re и используется для нахождения всех вхождений подстроки, соответствующих регулярному выражению. В отличие от find(), findall() возвращает список всех совпадений, а не только первое.
import re
text = "apple, banana, apple, cherry"
matches = re.findall("apple", text)
print(matches) # Выведет: ['apple', 'apple']
При использовании findall() с регулярными выражениями можно задать более сложные условия поиска, такие как поиск чисел, слов с определенными символами или паттернами:
matches = re.findall(r"\d+", "Номера: 123, 456, 789")
print(matches) # Выведет: ['123', '456', '789']
Для более сложных случаев findall() позволяет использовать группы в регулярных выражениях. Это полезно для извлечения различных частей строки, например, имен и фамилий из текста:
text = "Иван Иванов, Сергей Сергеев"
matches = re.findall(r"(\w+) (\w+)", text)
print(matches) # Выведет: [('Иван', 'Иванов'), ('Сергей', 'Сергеев')]
Таким образом, find() идеален для быстрого поиска одного вхождения подстроки, в то время как findall() предоставляет гораздо большую гибкость для работы с множественными совпадениями, особенно когда используются регулярные выражения.
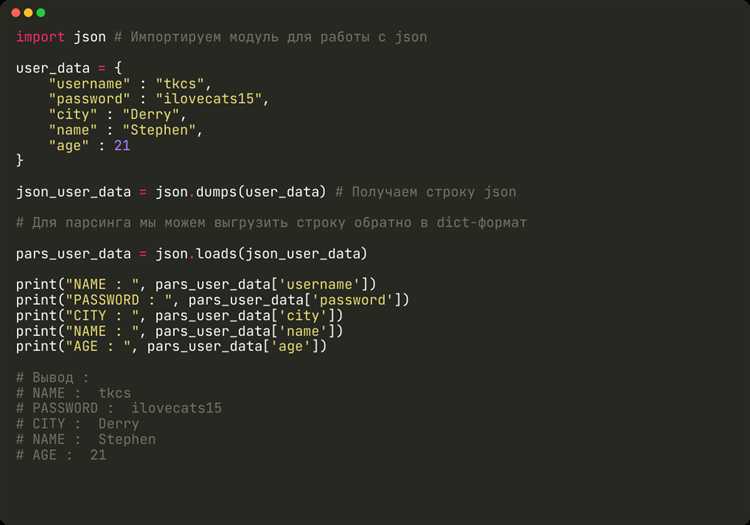
Извлечение данных из строки с использованием срезов

start– индекс начала среза (включительно),end– индекс конца среза (не включительно),step– шаг, определяющий частоту выборки символов.
Используя срезы, можно гибко работать с подстроками, например, извлекать данные по определённым индексам или манипулировать порядком символов. Например, чтобы извлечь первые 5 символов строки, можно использовать срез: строка[:5].
Также срезы позволяют извлекать подстроки с конца строки. Для этого достаточно использовать отрицательные индексы. Например, строка[-3:] вернёт последние три символа строки.
Шаг среза step используется для выборки каждого n-го элемента. Например, строка[::2] извлечёт каждый второй символ строки, начиная с первого.
Иногда срезы применяют для более сложных манипуляций. Например, извлечь все символы строки, начиная с третьего и заканчивая предпоследним, можно так: строка[2:-1].
Срезы удобны для извлечения данных из строк с известной структурой или в ситуациях, когда необходимо обрабатывать данные по частям.
Обработка строк с различными кодировками в Python
В Python строки по умолчанию представлены в формате Unicode, что позволяет работать с текстами на разных языках. Однако при взаимодействии с внешними источниками данных, такими как файлы или веб-сервисы, часто возникает необходимость работы с различными кодировками, такими как UTF-8, Latin-1, Windows-1251 и другие. Для правильной обработки строк в разных кодировках важно понимать, как конвертировать и декодировать данные.
Для декодирования строки из байтов в текст используется метод decode(). Пример использования: если у вас есть строка в байтовом представлении, закодированная в UTF-8, ее можно преобразовать в строку Python следующим образом:
bytes_data = b'\xd0\xb2\xd0\xbe\xd1\x81\xd1\x82\xd0\xbe\xd1\x87\xd0\xbd\xd1\x8b\xd0\xb9'
decoded_string = bytes_data.decode('utf-8')
print(decoded_string)В случае, если кодировка неизвестна, Python может попытаться автоматически определить её с помощью библиотеки chardet или cchardet. Эти инструменты могут помочь при работе с неизвестными источниками данных:
import chardet
raw_data = b'\xd0\xb2\xd0\xbe\xd1\x81\xd1\x82\xd0\xbe\xd1\x87\xd0\xbd\xd1\x8b\xd0\xb9'
result = chardet.detect(raw_data)
encoding = result['encoding']
decoded_string = raw_data.decode(encoding)
print(decoded_string)В случае работы с кодировками, которые не поддерживаются по умолчанию (например, Windows-1251 или ISO-8859-5), следует явно указывать кодировку при декодировании или кодировании строки. Например, для работы с Windows-1251:
bytes_data = b'\xcf\xf0\xf3\xe1\xeb\xe5'
decoded_string = bytes_data.decode('windows-1251')
print(decoded_string)Если при декодировании строки возникает ошибка (например, UnicodeDecodeError), можно указать параметр errors, который будет контролировать поведение при ошибках. Например, можно использовать опцию 'ignore', чтобы игнорировать некорректные символы:
bytes_data = b'\xd0\xb2\xd0\xbe\xd1\x81\xd1\x82\xd0\xbe\xd1\x87\xd0\xbd\xd1\x8b\xd0\xb9\x80'
decoded_string = bytes_data.decode('utf-8', errors='ignore')
print(decoded_string)Для кодирования строки обратно в байты используется метод encode(). Например, если необходимо закодировать строку в UTF-8, используйте:
encoded_string = decoded_string.encode('utf-8')
print(encoded_string)При работе с файлами важно корректно указать кодировку при открытии файла. Для чтения файла с заданной кодировкой используйте параметр encoding в функции open(). Например, для чтения файла с кодировкой UTF-8:
with open('file.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)Если кодировка файла неизвестна, можно использовать модуль chardet для определения кодировки и последующего правильного открытия файла. Однако, несмотря на наличие автоматических инструментов, всегда лучше явно указывать кодировку, если она известна, чтобы избежать ошибок при обработке.
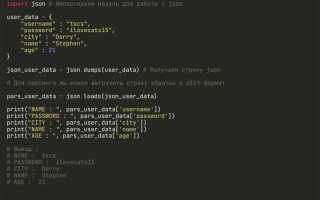
Парсинг строк JSON с использованием модуля json
Пример базового использования:
import json
json_string = '{"name": "Alice", "age": 30, "city": "Moscow"}'
data = json.loads(json_string)
print(data)
Функция json.loads() принимает строку в формате JSON и преобразует её в соответствующий объект Python. В данном случае, это будет словарь (dict), где ключи и значения соответствуют данным из JSON-строки.
Важно, что если строка не является валидным JSON, будет выброшено исключение json.JSONDecodeError. Для обработки таких ошибок можно использовать конструкцию try-except:
try:
data = json.loads(json_string)
except json.JSONDecodeError as e:
print(f"Ошибка парсинга JSON: {e}")
Также можно использовать параметр object_hook, чтобы настроить преобразование JSON в пользовательские объекты. Например, можно конвертировать строки в даты:
from datetime import datetime
def date_hook(dct):
for key, value in dct.items():
if isinstance(value, str) and len(value) == 10 and value[4] == '-' and value[7] == '-':
try:
dct[key] = datetime.strptime(value, '%Y-%m-%d')
except ValueError:
pass
return dct
json_string = '{"date": "2025-05-07"}'
data = json.loads(json_string, object_hook=date_hook)
print(data)
Когда JSON-строка содержит сложные вложенные структуры, например, массивы или вложенные объекты, json.loads() автоматически преобразует их в соответствующие структуры данных Python (списки, словари). Это упрощает работу с данными в дальнейшем.
Для того, чтобы убедиться в корректности JSON-строки перед её парсингом, можно использовать функцию json.JSONDecoder().decode(), которая предоставляет более подробные ошибки при парсинге:
decoder = json.JSONDecoder()
try:
data = decoder.decode(json_string)
except json.JSONDecodeError as e:
print(f"Ошибка при декодировании: {e}")
Подобная детализация ошибок может быть полезна при работе с большими и сложными JSON-данными.
Как извлечь значения из строки в формате CSV
Для извлечения значений из строки в формате CSV в Python используется встроенный модуль csv, который позволяет легко работать с текстовыми данными, разделёнными запятыми.
Для начала создадим строку в формате CSV, которая может представлять собой данные, разделённые запятыми:
"Иван,25,Москва,Разработчик"
Чтобы извлечь данные из этой строки, можно использовать следующий подход:
- Импортируем модуль
csv.
- Используем функцию
csv.reader или csv.split(), если работаем с обычной строкой.
Пример кода для извлечения данных:
import csv
from io import StringIO
# Строка CSV
data = "Иван,25,Москва,Разработчик"
# Преобразуем строку в объект, с которым можно работать
f = StringIO(data)
# Используем csv.reader для извлечения данных
reader = csv.reader(f, delimiter=',')
for row in reader:
print(row)
В результате выполнения этого кода, вы получите:
['Иван', '25', 'Москва', 'Разработчик']
Кроме того, можно использовать метод split() для извлечения значений, если не хотите использовать дополнительные библиотеки:
data = "Иван,25,Москва,Разработчик"
values = data.split(',')
print(values)
Этот подход выдаст тот же результат:
['Иван', '25', 'Москва', 'Разработчик']
Для извлечения значений с учётом возможных кавычек и экранированных символов, можно использовать настройки модуля csv, например, указать параметр quotechar.
import csv
from io import StringIO
data = '"Иван",25,"Москва","Разработчик"'
f = StringIO(data)
reader = csv.reader(f, delimiter=',', quotechar='"')
for row in reader:
print(row)
Результат будет следующим:
['Иван', '25', 'Москва', 'Разработчик']
Таким образом, для извлечения значений из строки CSV используйте модуль csv или метод split(), в зависимости от требований к обработке данных. Важно учитывать особенности формата, такие как кавычки и экранирование символов, для корректного извлечения информации.
Чтение и обработка строк из текстовых файлов в Python
Чтение и обработка строк из текстовых файлов в Python – одна из часто используемых операций при работе с данными. Основные методы, предоставляемые Python для работы с файлами, позволяют эффективно извлекать и обрабатывать текстовые данные.
Для открытия файла в Python используется функция open(), которая возвращает файловый объект. Пример открытия файла на чтение:
file = open('example.txt', 'r')
После открытия файла данные можно извлекать с помощью нескольких методов:
read() – считывает весь файл целиком в одну строку.readline() – считывает одну строку за раз.readlines() – считывает все строки файла в виде списка.
После завершения работы с файлом его необходимо закрыть с помощью метода close(). Однако лучший подход – использование конструкции with, которая автоматически закрывает файл после завершения работы:
with open('example.txt', 'r') as file:
content = file.read()
При чтении строк важно учитывать, что каждая строка содержит символ новой строки в конце. Для его удаления можно использовать метод strip():
line = line.strip()
Если необходимо обработать строки файла по очереди, удобнее использовать метод readline() или перебирать файл построчно:
with open('example.txt', 'r') as file:
for line in file:
line = line.strip() # Убираем символ новой строки
# обработка строки
Для работы с большими файлами, когда загрузка всего содержимого в память может быть неэффективной, стоит читать файл частями, например, с помощью метода readline() или по блокам фиксированного размера с read(size):
with open('large_file.txt', 'r') as file:
chunk = file.read(1024) # Чтение 1KB данных за раз
while chunk:
# обработка данных
chunk = file.read(1024)
Для парсинга данных из текстового файла часто используется регулярное выражение (модуль re). Пример использования регулярного выражения для извлечения чисел из строк файла:
import re
with open('data.txt', 'r') as file:
for line in file:
numbers = re.findall(r'\d+', line) # Извлечение всех чисел
# обработка чисел
При необходимости записывать данные в файл, используется метод write(), который записывает строку в файл:
with open('output.txt', 'w') as file:
file.write('Hello, world!')
Если важно записывать данные построчно, можно воспользоваться циклом:
with open('output.txt', 'w') as file:
for line in lines_to_write:
file.write(line + '\n')
Для обработки больших объемов данных рекомендуется использовать более сложные методы работы с файлами, такие как буферизация с помощью модуля io или многозадачность.
Вопрос-ответ:
Как распарсить строку в Python?
Для распарсивания строки в Python можно использовать несколько подходов в зависимости от структуры строки. Например, если строка имеет определенный формат, можно использовать метод `split()`, чтобы разделить строку по разделителю. Если нужно извлечь данные по шаблону, то стоит использовать регулярные выражения с модулем `re`.
Что такое регулярные выражения в Python и как их использовать для парсинга строки?
Регулярные выражения — это мощный инструмент для поиска и извлечения данных из строк. В Python они поддерживаются модулем `re`. Для поиска шаблона в строке используется функция `re.search()`, для замены — `re.sub()`, а для извлечения всех совпадений — `re.findall()`. Например, чтобы извлечь все числа из строки, можно использовать регулярное выражение вида `\d+`.
Какие функции можно использовать для парсинга строк в Python без использования регулярных выражений?
Для парсинга строк без регулярных выражений можно использовать методы стандартной библиотеки Python. Например, метод `split()` делит строку на части по заданному разделителю. Также полезен метод `strip()`, который удаляет пробелы в начале и конце строки. Для поиска подстроки внутри строки можно использовать метод `find()` или `index()`.