Шифр Цезаря – один из самых старых и известных методов симметричного шифрования, который был использован ещё в Древнем Риме. Его принцип прост: каждая буква исходного текста сдвигается на фиксированное количество позиций в алфавите. Однако, несмотря на свою историческую значимость, шифр легко поддается анализу, особенно при наличии автоматизированных инструментов, таких как Python.
Процесс расшифровки шифра Цезаря сводится к нахождению правильного сдвига, который был использован при шифровании. В случае, если сдвиг неизвестен, существует несколько методов его обнаружения, включая частотный анализ или просто перебор возможных сдвигов. Использование Python позволяет автоматизировать этот процесс и быстро расшифровать сообщение без значительных усилий.
Основная цель данной статьи – показать, как с помощью Python можно эффективно расшифровать текст, зашифрованный с использованием шифра Цезаря. Мы рассмотрим как реализовать алгоритм расшифровки с применением стандартных библиотек, таких как string, и воспользуемся различными подходами для нахождения сдвига. В конце мы предложим решение, которое автоматически определяет сдвиг и расшифровывает текст без необходимости вручную указывать параметры.
Определение сдвига в шифре Цезаря для расшифровки
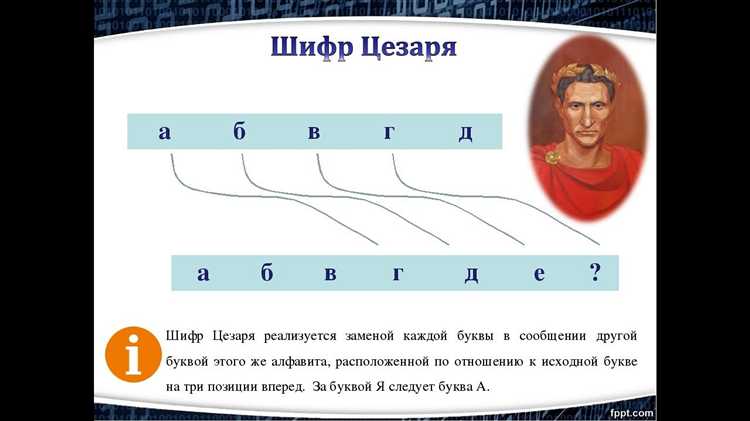
Для расшифровки текста, зашифрованного с помощью шифра Цезаря, необходимо правильно определить сдвиг, использованный при шифровании. В отличие от современных методов шифрования, шифр Цезаря использует простой сдвиг букв в алфавите, и задача состоит в нахождении этого сдвига.
Простейший способ определения сдвига – это анализ частоты появления букв. В русском языке буквы «о», «е», «а», «и» встречаются значительно чаще других, и их можно искать в зашифрованном сообщении. Если одна из этих букв зашифрована в менее частую, например, «г», то сдвиг можно вычислить как разницу позиций этих букв в алфавите.
Можно также воспользоваться методом «перебора». Он заключается в том, что для всех возможных сдвигов (от 1 до 32 для русского алфавита) создаются расшифрованные версии текста, и анализируется, при каком сдвиге получается осмысленный текст. Этот метод эффективен для коротких сообщений или в случае, если известны некоторые слова в тексте.
Например, для строки «Тестовое сообщение» и сдвига 3, получим «Рбпсрпв лррптжие». Перебор всех сдвигов от 1 до 32 поможет найти корректный вариант.
Создание функции для расшифровки текста с заданным сдвигом

Для расшифровки текста, зашифрованного с использованием шифра Цезаря, требуется применить обратный сдвиг. Суть алгоритма заключается в том, чтобы для каждого символа текста сдвигать его в обратную сторону на определённое количество позиций по алфавиту. В этой части рассмотрим, как создать функцию на Python, которая выполняет расшифровку текста с заданным сдвигом.
Ниже представлена функция для расшифровки текста с учётом сдвига. Она принимает два параметра: текст и сдвиг, который нужно применить.
def caesar_decipher(text, shift): decrypted_text = "" for char in text: if char.isalpha(): shift_base = 65 if char.isupper() else 97 new_char = chr((ord(char) - shift_base - shift) % 26 + shift_base) decrypted_text += new_char else: decrypted_text += char return decrypted_text
Функция работает следующим образом:
- Проходим по каждому символу строки: Проверяется, является ли символ буквой, используя метод
isalpha(). - Обработка заглавных и строчных букв: Для каждой буквы определяется базовый сдвиг (65 для заглавных и 97 для строчных), чтобы правильно обработать символы в диапазоне ASCII.
- Вычисление нового символа: Для каждой буквы вычисляется новый символ после применения сдвига. Операция
(ord(char) - shift_base - shift) % 26обеспечивает корректный переход по кругу алфавита. - Сохранение результата: Заменённый символ добавляется в строку, которая в конечном итоге возвращается как результат.
Пример использования функции:
ciphertext = "Uifsf jt b tfdsfu dpef!" shift = 1 plaintext = caesar_decipher(ciphertext, shift) print(plaintext) # Выведет: There is a secret code!
Эта функция эффективно расшифровывает текст, используя указанный сдвиг. Обратите внимание, что она сохраняет все неалфавитные символы (пробелы, знаки препинания) без изменений.
Для повышения безопасности шифрования можно использовать более сложные алгоритмы, однако шифр Цезаря остаётся хорошим примером для освоения основ криптографии.
Обработка символов, не входящих в алфавит, при расшифровке
При расшифровке шифра Цезаря важно учитывать, что в исходном тексте могут встречаться символы, не относящиеся к алфавиту, например, пробелы, знаки препинания или цифры. Для правильной работы алгоритма необходимо решить, как поступить с такими символами.
Один из подходов – оставить эти символы без изменений. Шифрование и расшифровка будет происходить только для букв, а все остальные символы останутся как есть. Такой подход сохраняет структуру исходного текста и облегчает восприятие результата.
Рассмотрим пример. Пусть у нас есть строка: «Привет, мир!». Если мы применим шифр Цезаря с ключом 3, то буквы будут заменены на буквы с учётом смещения, а запятая и восклицательный знак останутся без изменений:
Шлифе, пкг!
Другой подход – игнорировать все символы, не входящие в алфавит. Это приводит к изменению исходного текста, но позволяет сфокусироваться только на шифровке букв. Такой подход может быть полезен в определённых сценариях, например, если текст состоит исключительно из символов, относящихся к алфавиту, и важно, чтобы результат был точно вычисляемым.
Также следует учитывать различия в кодировках. Если шифр Цезаря реализуется с использованием стандартного латинского алфавита, то любые символы, не входящие в этот алфавит, могут быть отброшены. Например, при шифровании текста на кириллице важно удостовериться, что обрабатываются только буквы кириллицы, а все остальные символы либо остаются нетронутыми, либо игнорируются в процессе расшифровки.
Таким образом, выбор метода обработки неалфавитных символов зависит от целей программы и особенностей текста, который подвергается шифрованию или расшифровке.
Как автоматизировать подбор сдвига с помощью перебора

Чтобы автоматизировать этот процесс, можно использовать несколько подходов, например, основанных на частотном анализе или на простом анализе читаемости текста.
Шаги для автоматизации перебора сдвига:
- Шаг 1: Реализация функции для расшифровки шифра Цезаря. Эта функция будет принимать зашифрованный текст и сдвиг, а затем возвращать расшифрованный текст.
- Шаг 2: Перебор всех возможных сдвигов. Для шифра Цезаря возможен сдвиг от 1 до 25 (сдвиг 0 не изменяет текст). В цикле перебираются все значения сдвига.
- Шаг 3: Оценка расшифрованного текста. Нужно оценить, насколько правильно расшифрованный текст. Например, можно использовать метод, который проверяет количество «сложных» слов или вероятность появления часто встречающихся букв в русском языке (таких как «о», «е», «а»).
Пример кода:

Вот пример простого скрипта для перебора сдвига и получения расшифрованного текста:
def caesar_decrypt(text, shift):
result = ""
for char in text:
if char.isalpha():
shift_base = 65 if char.isupper() else 97
result += chr((ord(char) - shift_base - shift) % 26 + shift_base)
else:
result += char
return result
def auto_decrypt(ciphertext):
for shift in range(1, 26):
decrypted_text = caesar_decrypt(ciphertext, shift)
print(f"Сдвиг {shift}: {decrypted_text}")
Этот код будет перебирать сдвиги от 1 до 25 и показывать расшифрованный текст для каждого сдвига. Далее, можно добавить дополнительные алгоритмы для автоматической оценки качества расшифрованного текста.
Подходы к оценке текста:
- Частотный анализ: Сравнение частот букв в расшифрованном тексте с типичными частотами букв в русском языке. Например, буквы «о», «е», «а» встречаются намного чаще других.
- Оценка по словарю: Проверка наличия реальных слов в расшифрованном тексте. Чем больше слов совпадает с реальным словарем, тем выше вероятность, что сдвиг подобран правильно.
- Оценка читаемости: Можно использовать коэффициент читаемости, чтобы понять, насколько текст легко воспринимается.
Используя эти методы, можно не только перебрать все сдвиги, но и выбрать наиболее подходящий вариант, автоматизируя процесс расшифровки шифра Цезаря с помощью перебора.
Использование библиотеки Python для работы с текстами
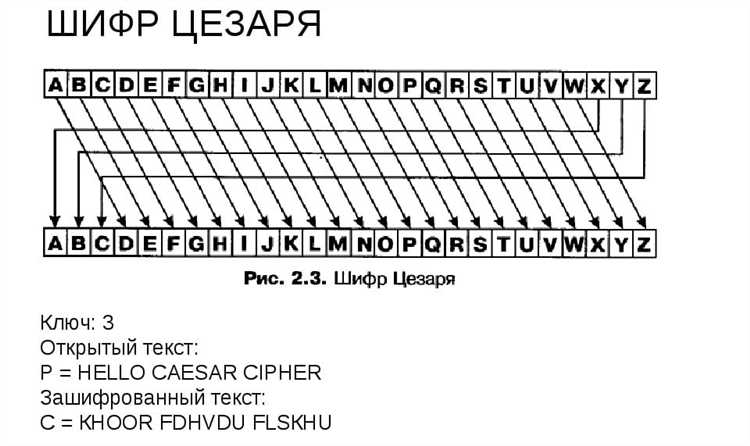
Для шифрования и дешифрования текста, например, с использованием шифра Цезаря, полезной будет библиотека string для работы с алфавитом. Однако, если задача включает более сложную обработку текста, то стоит обратить внимание на такие библиотеки, как re для регулярных выражений, которая помогает находить, изменять или извлекать фрагменты текста, соответствующие определенным шаблонам.
Кроме того, для работы с текстами на более высоком уровне, например, при реализации алгоритмов шифрования, полезна библиотека collections, которая предоставляет такие структуры данных, как Counter, позволяющая подсчитать частоту появления символов в строке, что может быть полезно для криптографического анализа.
Для обработки текста, включающего различные языки или требующего работы с кодировками, стоит обратить внимание на библиотеку chardet, которая автоматически определяет кодировку текста. Это особенно полезно при работе с текстами из разных источников, где кодировка может варьироваться.
Наконец, для визуализации результатов обработки текста, например, частоты символов, можно использовать библиотеки matplotlib или seaborn, которые позволяют строить графики и диаграммы. Это помогает наглядно представить статистику для анализа и дальнейшего улучшения алгоритмов обработки текста.
Рассмотрим текст «Гяйс фш фдшъ», зашифрованный с помощью шифра Цезаря с неким сдвигом. Для того, чтобы расшифровать его, можно пройти по всем возможным сдвигам от 1 до 33 и посмотреть, какой из них дает осмысленный текст.
Пример кода на Python:
def caesar_decrypt(text, shift):
decrypted_text = ""
for char in text:
if char.isalpha():
shift_base = 1040 if char.isupper() else 1072
decrypted_char = chr((ord(char) - shift_base - shift) % 32 + shift_base)
decrypted_text += decrypted_char
else:
decrypted_text += char
return decrypted_text
cipher_text = "Гяйс фш фдшъ"
for shift in range(1, 34):
print(f"Сдвиг {shift}: {caesar_decrypt(cipher_text, shift)}")
Вопрос-ответ:
Что такое шифр Цезаря и как он работает?
Шифр Цезаря — это один из самых простых и старых методов шифрования текста, который использует сдвиг букв в алфавите на определённое количество позиций. Например, если выбран сдвиг на 3, то буква «А» станет «Г», «Б» — «Д» и так далее. Этот метод легко расшифровывается, если известен сдвиг, но его можно взломать с помощью простых алгоритмов, перебирая все возможные сдвиги.
Как узнать правильный сдвиг для расшифровки, если его не знают?
Если сдвиг неизвестен, то можно попробовать перебрать все возможные варианты, так как их всего 26 (для английского алфавита). В большинстве случаев это можно сделать с помощью Python, используя цикл, который применяет все сдвиги от 1 до 25. В случае с текстом на русском языке, аналогичный подход можно использовать, но для русского алфавита. Если текст состоит из осмысленных слов, то правильный сдвиг будет тот, при котором появится нормальный текст.
Можно ли автоматизировать процесс поиска сдвига при расшифровке шифра Цезаря?
Да, можно использовать статистические методы для автоматического нахождения сдвига. Например, можно анализировать частотный состав букв в шифрованном сообщении и сравнить его с частотным распределением букв в языке. Однако, для этого нужно больше знаний о языке и более сложные алгоритмы, чем просто перебор всех сдвигов. В Python можно применить библиотеки для анализа частотности, такие как `collections` для подсчёта встречаемости символов и их сравнения с типичными частотами в языке.
Какие есть ограничения и уязвимости у шифра Цезаря?
Основным ограничением шифра Цезаря является его простота. Сдвиг в алфавите можно легко расшифровать методом полного перебора всех вариантов. Шифр не является стойким к криптоанализу, и его можно взломать за считанные секунды, если зашифрованный текст достаточно длинный. Это делает его бесполезным для защиты важной информации. Однако шифр Цезаря всё же может быть интересен как упражнение для обучения основам криптографии.