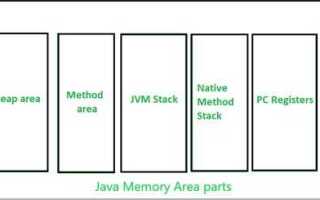
Механизм работы памяти в Java строится на динамическом управлении ресурсами с использованием множества объектов и автоматического управления памятью через сборщик мусора. Главная особенность заключается в том, что Java использует модель управления памятью, основанную на куче и стеке, что существенно влияет на производительность и безопасность приложений. Память в Java делится на несколько частей: область стека, куча, и постоянная память, каждая из которых выполняет свою роль в процессе выполнения программы.
Стек используется для хранения локальных переменных и информации о вызовах методов. Стек работает по принципу LIFO (Last In, First Out), то есть данные добавляются и удаляются в обратном порядке. Это обеспечивает быструю и эффективную работу с данными, однако стек ограничен по объему, и чрезмерное использование может привести к ошибке переполнения стека.
Основной частью памяти, с которой взаимодействует большинство объектов, является куча. Куча – это область памяти, где размещаются объекты, создаваемые через операторы, такие как new. В отличие от стека, куча значительно больше по объему, но требует более сложного управления. Сборщик мусора (Garbage Collector) автоматически освобождает память, которая больше не используется, что позволяет избежать утечек памяти. Однако частые обращения к сборщику могут негативно сказаться на производительности.
Постоянная память включает в себя область, где хранятся классы и строковые литералы. Данные, размещенные в постоянной памяти, существуют на протяжении всего времени работы программы. Это позволяет ускорить доступ к часто используемым данным, таким как классы или строки, и минимизировать время их загрузки в память.
Как Java управляет памятью с помощью сборщика мусора
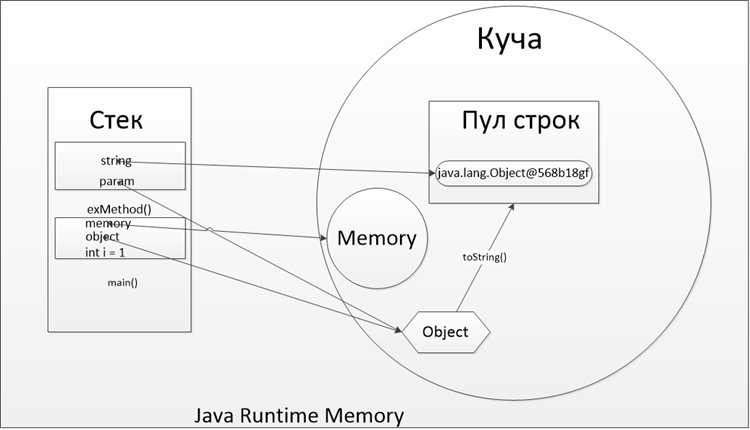
В Java управление памятью автоматизируется с помощью механизма сборщика мусора (Garbage Collector, GC). Он отвечает за освобождение памяти, занятой объектами, которые больше не используются, предотвращая утечки памяти и снижая необходимость ручного вмешательства разработчика в процессы управления ресурсами. Основная задача GC – отслеживание и удаление объектов, на которые больше нет ссылок, что позволяет эффективно управлять памятью приложения.
Сборщик мусора в Java работает на основе нескольких принципов. В первую очередь, Java использует систему с кучей (heap), которая делится на несколько частей: младшее поколение (young generation), старшее поколение (old generation) и постоянное поколение (permanent generation или metaspace в новых версиях). Объекты создаются в младшем поколении и, если они переживают несколько сборок мусора, перемещаются в старшее поколение.
Основные алгоритмы, используемые в Java GC, включают:
1. Алгоритм маркировки и удаления
Этот алгоритм состоит из двух фаз: маркировка и удаление. На этапе маркировки сборщик мусора выявляет все объекты, на которые существуют активные ссылки. Затем на этапе удаления уничтожаются все объекты, не имеющие ссылок, освобождая память.
2. Алгоритм копирования
В этом алгоритме память делится на две области. Когда одна область заполняется, объекты, которые все еще используются, копируются в другую область, а вся старая область очищается. Это позволяет эффективно управлять памятью и минимизировать фрагментацию.
3. Алгоритм инкрементальной сборки мусора
Этот метод включает сборку мусора по частям, что помогает избежать пауз, которые могут возникать при полном очищении памяти. Инкрементальная сборка распределяет нагрузку по времени, делая работу программы более стабильной.
Java предлагает несколько вариантов сборщиков мусора, таких как:
- Serial GC: Однопоточный сборщик, который подходит для приложений с небольшим объемом данных и ограниченными требованиями к времени работы.
- Parallel GC: Многопоточный сборщик, оптимизирует использование процессорных ресурсов и подходит для многозадачных серверных приложений.
- G1 GC: Сборщик мусора, оптимизирующий паузы, разделяет кучу на регионы и выполняет сборку мусора на основе приоритетности.
- ZGC и Shenandoah: Современные низкопаузы GC, предназначенные для минимизации времени остановки приложения.
Для эффективного управления памятью в Java важно правильно выбрать и настроить сборщик мусора, учитывая характеристики приложения, такие как размер кучи, частота создания объектов и требования к времени отклика. Например, для высоконагруженных серверных приложений лучше использовать G1 или ZGC, которые оптимизируют время отклика и минимизируют паузы. Важно также мониторить использование памяти и время пауз с помощью инструментов профилирования, чтобы своевременно адаптировать настройки.
Особенности работы с кучей в Java: управление памятью для объектов
Аллокация памяти и фрагментация в куче происходит в два этапа. Во время первого этапа выделяется непрерывный блок памяти для каждого объекта. Однако со временем, когда объекты создаются и уничтожаются, память может фрагментироваться, что приводит к разбросу свободных областей памяти. Это снижает эффективность использования памяти и может увеличить время выполнения программы.
Для минимизации фрагментации Java использует младший и старший поколения в куче. Младшее поколение предназначено для хранения объектов, срок жизни которых, как правило, небольшой. Старшее поколение используется для объектов, которые долго существуют в памяти. Когда объекты из младшего поколения переживают несколько сборок мусора, они перемещаются в старшее поколение, где вероятность их удаления значительно ниже. Это разделение помогает уменьшить накладные расходы на сборку мусора, улучшая производительность.
Сборка мусора в Java состоит из нескольких типов коллекций: Minor GC и Major GC. Minor GC отвечает за очистку младшего поколения, в то время как Major GC очищает старшее поколение. Процесс сборки мусора заключается в освобождении памяти от объектов, которые больше не используются. Однако стоит помнить, что чрезмерные вызовы сборщика мусора могут негативно сказаться на производительности, особенно если работа с кучей плохо оптимизирована.
Тюнинг управления памятью может включать использование различных JVM-флагов для настройки размеров поколения или изменения поведения сборщика мусора. Например, установка флага -Xms позволяет задать начальный размер кучи, а -Xmx – максимальный. Это позволяет заранее управлять объемом памяти, выделяемым под кучу, и минимизировать количество операций по расширению или сжатию памяти.
Перераспределение памяти в куче требует внимательности при проектировании приложений. Программисты могут столкнуться с проблемой, когда неправильное управление жизненным циклом объектов приводит к утечкам памяти. Это особенно важно в многозадачных приложениях, где объекты могут быть созданы в разных потоках. Использование слабых ссылок (WeakReference) или явное удаление объектов, которые больше не нужны, может помочь избежать утечек и улучшить использование памяти.
Для повышения производительности можно использовать инструменты мониторинга JVM, такие как jconsole, VisualVM и GC logs, которые позволяют отслеживать поведение кучи и эффективность сборки мусора. Это помогает разработчикам оптимизировать работу приложения, улучшая использование памяти и минимизируя задержки при сборке мусора.
Как работает стек в Java: что важно знать для понимания локальных переменных
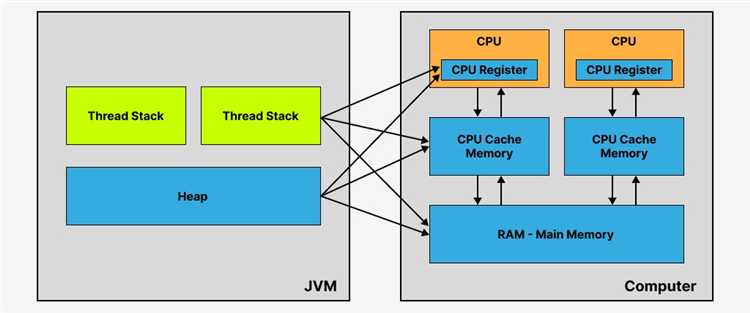
Стек в Java представляет собой область памяти, которая используется для хранения данных о методах, их вызовах и локальных переменных. Стек функционирует по принципу LIFO (Last In, First Out), что означает, что последние добавленные данные извлекаются первыми. Важное свойство стека – его ограниченный размер, который определяется системой и может вызвать переполнение стека (StackOverflowError) при чрезмерном потреблении памяти.
Локальные переменные и стек тесно связаны. Каждая локальная переменная в Java сохраняется в стеке, причем она существует только в пределах метода, в котором она была объявлена. Когда метод вызывается, для его выполнения на стеке выделяется новый фрейм (или кадр), который включает ссылки на локальные переменные, параметры метода и другие данные, необходимые для выполнения. После завершения метода его фрейм удаляется из стека.
Особенности хранения локальных переменных:
1. Типы данных: Примитивные типы (например, int, boolean) хранятся непосредственно в стеке. Это позволяет быстро получить доступ к этим данным, так как они не требуют дополнительного выделения памяти на куче. В отличие от примитивов, объекты и массивы хранятся в куче, а в стеке сохраняется только ссылка на объект.
2. Инициализация переменных: Локальные переменные в Java должны быть инициализированы перед использованием. Если переменная не была инициализирована, то компилятор Java не позволит ее использовать, предотвращая возможные ошибки, связанные с использованием неинициализированных данных.
3. Жизненный цикл локальных переменных: Локальная переменная существует только в момент выполнения метода. Как только метод завершает свою работу, его фрейм удаляется из стека, а все локальные переменные становятся недоступными. Это означает, что их память освобождается автоматически, без необходимости в явной очистке, как это происходит с объектами в куче.
4. Размер стека: Каждый метод вызывает новый фрейм в стеке. Если количество рекурсивных вызовов слишком велико, это может привести к переполнению стека. Следует избегать излишней рекурсии и контролировать глубину вызовов, чтобы не столкнуться с этим ограничением.
Практические рекомендации:
1. Осторожность с рекурсией: Рекурсивные методы могут быстро исчерпать размер стека, особенно при отсутствии явного базового случая. Для предотвращения переполнения используйте итеративные подходы, когда это возможно.
2. Минимизация использования большого объема данных в локальных переменных: Если метод использует большое количество локальных переменных, особенно объектов, это увеличивает размер фрейма стека и может привести к его переполнению. Разделение больших методов на несколько маленьких или использование объектов для хранения данных может снизить нагрузку на стек.
3. Управление памятью: Понимание работы стека помогает избегать избыточного потребления памяти. Например, при работе с большими объемами данных или сложной логикой следует по возможности перенаправлять данные на кучу, а не хранить их в локальных переменных.
Память для примитивных типов данных: хранение и доступ

Примитивные типы данных в Java занимают фиксированное количество памяти, что упрощает управление памятью и доступ к этим данным. Каждый примитивный тип данных имеет свою специфику хранения и способы доступа, что важно для оптимизации работы программ.
- Целочисленные типы:
byte,short,int,long. Эти типы используют статический размер памяти: byte– 1 байтshort– 2 байтаint– 4 байтаlong– 8 байт- Типы с плавающей запятой:
float,double. Они используются для представления вещественных чисел: float– 4 байтаdouble– 8 байт- Логический тип:
booleanзанимает 1 байт памяти, однако в реальности его хранение может зависеть от JVM. Иногда JVM может оптимизировать хранение, используя 1 бит на значение. - Символьный тип:
charпредставляет символ в кодировке UTF-16 и занимает 2 байта.
При доступе к примитивным данным JVM обрабатывает их по-разному. Примитивы хранятся в стеке или в куче, в зависимости от контекста:
- Если переменная примитивного типа объявлена локально, она обычно сохраняется в стеке. Это быстрое и эффективное хранилище с ограниченной продолжительностью жизни.
- Если примитивы передаются в методы или используются в объектах, они могут быть помещены в кучу, что позволяет JVM управлять их продолжительностью жизни через сборщик мусора.
Доступ к данным в стеке происходит быстрее, чем в куче, поскольку стек использует структуру данных LIFO (Last In, First Out), а доступ к данным в куче может быть более затратным из-за необходимости поиска и управления памятью.
Для эффективной работы с примитивными типами важно помнить следующее:
- Примитивы всегда копируются при передаче в методы, что означает отсутствие побочных эффектов при изменении значений в методах.
- Использование примитивных типов в качестве полей классов оптимально с точки зрения производительности, так как они не требуют дополнительных аллокаций памяти.
- Применение оберток (например,
IntegerилиDouble) полезно для работы с коллекциями и специфическими API, но такие типы имеют больше накладных расходов по сравнению с чистыми примитивами.
Таким образом, примитивные типы данных в Java имеют четкую структуру хранения и эффективный доступ, что играет ключевую роль в производительности приложений.
Что такое пул строк в Java и как он оптимизирует использование памяти
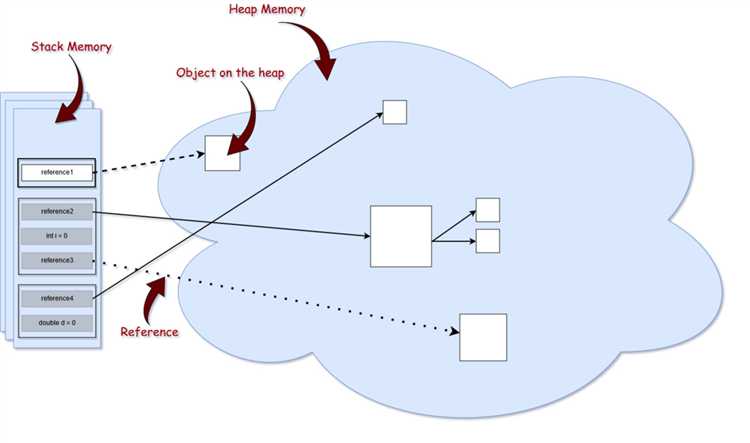
Когда в коде Java используется строка, которая уже присутствует в пуле строк, JVM (Java Virtual Machine) не создаёт новый объект строки, а возвращает ссылку на уже существующий. Это значительно снижает потребность в памяти, особенно в приложениях, где встречаются одинаковые строки, например, в базе данных или при обработке большого объема текста.
Каждая строка в Java является объектом класса String. Когда строка создаётся через строковый литерал (например, «Hello»), она сначала проверяется в пуле строк. Если такой литерал уже существует, JVM использует уже существующий объект. Если строки нет в пуле, она добавляется туда. Однако, строки, созданные через операторы `new` (например, `new String(«Hello»)`), не добавляются в пул, даже если такой литерал уже существует, что может привести к избыточному расходу памяти.
Пул строк значительно ускоряет выполнение программы за счёт исключения необходимости повторного выделения памяти для одинаковых строк. Это особенно актуально при обработке больших объёмов текстовых данных, где однотипные строки могут встречаться часто. Например, при работе с большими файлами или текстами, которые содержат одинаковые фразы или ключевые слова, пул строк уменьшает общий размер занимаемой памяти и ускоряет доступ к данным.
Тем не менее, важно учитывать, что пул строк в Java ограничен по размеру и хранит только строковые литералы и строки, явно добавленные в пул через методы, такие как `intern()`. Программистам следует быть осторожными при создании строк с помощью оператора `new`, чтобы избежать лишних объектов в памяти, которые не попадут в пул и будут занимать дополнительное место.
Использование пула строк – это полезная практика для оптимизации работы с памятью, однако важно следить за его пределами, так как чрезмерное добавление строк в пул может привести к перерасходу памяти. Рекомендуется избегать чрезмерного использования метода `intern()` и оценивать, насколько оправдано добавление каждой строки в пул.
Роль метаспейса в Java: хранение информации о классах
Метаспейс в Java представляет собой область памяти, которая используется для хранения данных о загруженных классах и их метаданных. В отличие от старого перманентного поколения (Permanent Generation), который был удален начиная с Java 8, метаспейс значительно улучшил управление памятью за счет использования системной памяти, а не ограниченного кучи JVM.
Метаспейс сохраняет информацию о классах, такую как имена классов, их методы, поля, константы и прочие метаданные, включая их загрузку и статическую инициализацию. Каждая загруженная версия класса размещается в метаспейсе, что позволяет ускорить доступ к метаданным и снижает нагрузку на сборщик мусора.
В отличие от прежней модели, метаспейс не ограничен фиксированным размером и может динамически расширяться в пределах доступной системной памяти. Это делает его более гибким и способным справляться с большими нагрузками, например, при работе с большим количеством классов в крупных приложениях.
Однако, как и любой другой ресурс памяти, метаспейс может исчерпать доступную память. В таких случаях JVM может выбросить исключение OutOfMemoryError. Чтобы предотвратить такие ситуации, важно следить за размером метаспейса и при необходимости настраивать параметры JVM с помощью флагов -XX:MetaspaceSize и -XX:MaxMetaspaceSize. Первый параметр определяет начальный размер метаспейса, а второй – его максимальный предел.
Важно понимать, что метаспейс не связан с кучей (heap) и не подвергается сборке мусора так же часто, как объекты в куче. Однако в случае, если классы больше не используются, их метаданные могут быть удалены из метаспейса, что способствует эффективному управлению памятью.
Рекомендуется следить за загрузкой классов и их количеством, особенно при работе с динамически генерируемыми или загружаемыми классами. В таких случаях можно оптимизировать процесс работы с метаспейсом путем настройки соответствующих параметров JVM, чтобы избежать чрезмерного использования системной памяти и предотвратить ошибки из-за нехватки метаспейса.
Как память используется при многозадачности и многопоточности в Java
В Java многозадачность и многопоточность тесно связаны с управлением памятью, поскольку каждый поток требует выделения собственного стека, а также взаимодействует с общими данными, хранящимися в куче (heap). Потоки работают параллельно, что требует эффективного управления памятью для предотвращения ошибок синхронизации и утечек.
Каждому потоку выделяется собственный стек, который содержит локальные переменные, а также информацию о вызовах методов. Размер стека каждого потока ограничен и может быть настроен при создании JVM. Стек отвечает за хранение данных, специфичных для потока, и его изоляция необходима для предотвращения перезаписи данных между потоками.
Куча (heap) используется для хранения объектов, общих для всех потоков. Механизм синхронизации и блокировки данных при доступе к общим объектам предотвращает одновременную запись несколькими потоками, что может привести к ошибкам. Например, для синхронизации используется ключевое слово synchronized или механизмы, такие как ReentrantLock. Без должной синхронизации может возникнуть состояние гонки, когда данные изменяются одновременно несколькими потоками, что может привести к некорректному поведению программы.
Важно понимать, что многопоточное приложение не всегда эффективно использует память. Например, при большом количестве потоков, каждый из которых требует выделения памяти для стека, нагрузка на систему может возрасти. Решение – ограничение количества потоков или использование пула потоков (например, через ExecutorService), который эффективно управляет количеством одновременно выполняемых потоков, снижая потребление памяти.
Кроме того, существует проблема управления памятью при завершении работы потоков. Неактивные или завершённые потоки могут не освобождать ресурсы, если за ними не наблюдают. Поэтому важно правильно управлять жизненным циклом потоков, освобождая ресурсы после их завершения, например, через метод shutdown() в ExecutorService.
Таким образом, управление памятью в многозадачной среде Java требует внимательного подхода к организации памяти как для отдельных потоков, так и для общих данных, а также эффективного использования инструментов синхронизации и пулов потоков для оптимизации производительности и предотвращения утечек памяти.
Как мониторить использование памяти в Java-программах
Мониторинг памяти в Java-программах позволяет отслеживать использование ресурсов и вовремя выявлять потенциальные проблемы. Существует несколько способов анализа использования памяти в Java, включая инструменты и встроенные средства.
Для мониторинга памяти в Java можно использовать следующие подходы:
- JVM-метрики через JMX – Java Management Extensions (JMX) позволяют получать информацию о работе JVM, включая использование памяти. Встроенные MBeans предоставляют данные о текущем состоянии памяти, количестве объектов в куче и других параметрах.
- VisualVM – инструмент с графическим интерфейсом, который позволяет отслеживать память и производительность JVM в реальном времени. VisualVM предоставляет подробные графики по использованию кучи, а также позволяет анализировать утечки памяти и проводить профилирование.
- Heap dumps – анализ дампов памяти помогает выявить утечки и проблемы с памятью. Для создания дампов используется параметр
-XX:+HeapDumpOnOutOfMemoryError, который автоматически создает дамп при возникновении ошибки OOM. - Java Flight Recorder (JFR) – инструмент для записи и анализа данных о работе JVM, включая информацию о памяти. JFR используется для долгосрочного мониторинга производительности и может быть полезен для анализа утечек и проблем с памятью.
Для автоматического мониторинга и анализа можно использовать следующие методы:
- Использование внешних мониторинговых инструментов – такие решения, как Prometheus и Grafana, позволяют собирать и визуализировать метрики памяти из Java-программ, интегрируясь с JMX или другими библиотеками для мониторинга.
- Профилирование памяти – профилировщики, такие как YourKit или JProfiler, помогают находить утечки памяти и анализировать распределение объектов в куче. Эти инструменты предоставляют подробную информацию о количестве объектов, которые занимают память, и их жизни в процессе выполнения.
Для эффективного мониторинга важно учитывать следующие аспекты:
- Регулярность – мониторинг должен проводиться на регулярной основе для выявления изменений в поведении программы, которые могут привести к утечкам памяти.
- Параллельность – необходимо учитывать влияние многозадачности и параллельных потоков на распределение памяти.
- Анализ паттернов использования памяти – анализируйте, как память используется в разные периоды работы программы, чтобы выявить возможные зоны с перегрузкой или утечками.
Знание этих инструментов и методов позволяет своевременно реагировать на проблемы с памятью и предотвращать негативные последствия для производительности программы.
Вопрос-ответ:
Что такое управление памятью в Java и какие методы используются для этого?
В Java управление памятью происходит автоматически через механизм сборщика мусора (Garbage Collector). Он следит за объектами, которые больше не используются, и освобождает занятую ими память. Основные методы, которые влияют на управление памятью, включают создание объектов с использованием оператора `new`, использование ссылок на объекты и явный вызов метода `System.gc()`, который сообщает сборщику мусора о возможности запуска процесса очистки памяти. Однако, этот метод не гарантирует немедленного выполнения сборщика мусора.
Как работает сборщик мусора в Java и когда он срабатывает?
Сборщик мусора в Java управляет памятью, автоматически освобождая её от объектов, которые больше не имеют ссылок. Он использует различные алгоритмы для эффективного освобождения памяти, такие как сборка по поколениям, при которой объекты делятся на несколько поколений в зависимости от их возраста. Когда количество объектов в старшем поколении достигает определенного порога, запуск сборщика мусора происходит. Однако точный момент его работы не предсказуем, поскольку он зависит от множества факторов, включая использование памяти, загрузку системы и настроенные параметры JVM.
Какие виды памяти существуют в Java и чем они отличаются?
В Java память делится на несколько типов: стек (stack), куча (heap) и метод-память. Стек используется для хранения локальных переменных и вызовов методов. Куча предназначена для динамического распределения памяти, где создаются все объекты, и управляется сборщиком мусора. Метод-память используется для хранения данных, связанных с методами класса. Отличия между ними заключаются в том, как происходит выделение памяти, а также в области их использования. Например, стек имеет фиксированный размер, а куча может расширяться.
Почему важно понимать управление памятью в Java для разработчика?
Понимание управления памятью в Java важно, потому что неправильное использование памяти может привести к утечкам, снижению производительности и даже сбоям в работе приложения. Например, если объекты не освобождаются вовремя, это может вызвать избыточное потребление памяти, что приведет к ошибке OutOfMemoryError. Знание принципов работы сборщика мусора помогает лучше контролировать производительность приложения и оптимизировать использование памяти. Также важно уметь настроить параметры JVM для улучшения работы с памятью в зависимости от потребностей приложения.
Что такое утечка памяти в Java и как её можно предотвратить?
Утечка памяти в Java происходит, когда объект остаётся в памяти, хотя он больше не используется. Это может случиться, например, если существуют ненужные ссылки на объект, которые не позволяют сборщику мусора освободить память. Чтобы предотвратить утечку памяти, важно следить за тем, чтобы не держать ссылки на объекты, которые больше не нужны, и использовать слабые ссылки в тех случаях, когда объект должен быть удалён сборщиком мусора, но ещё может быть доступен для других процессов. Также важно правильно управлять ресурсами, такими как соединения с базами данных и потоки, чтобы они не оставались открытыми слишком долго.
Как в Java управляется памятью и что нужно знать о её ключевых особенностях?
Память в Java управляется с помощью механизма автоматической сборки мусора (Garbage Collection). Этот процесс включает в себя освобождение памяти от объектов, которые больше не используются в программе. В Java память делится на несколько частей, таких как Heap и Stack. Stack используется для хранения локальных переменных и ссылок, тогда как Heap — для хранения объектов. Когда объект теряет все ссылки, он становится кандидатом для сборщика мусора, который освободит занимаемое им место. Важно отметить, что разработчики не управляют сборкой мусора напрямую, а полагаются на JVM (Java Virtual Machine) для этого. Это позволяет упрощать разработку, однако также стоит помнить, что неправильное использование памяти может приводить к утечкам или неоптимальному расходу ресурсов.