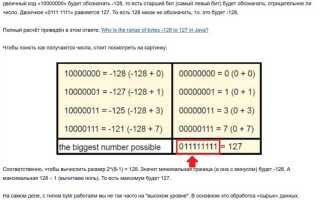
В Java преобразование байтов в символы осуществляется с помощью кодировок, которые определяют, как байты интерпретируются как символы. Наиболее часто используемые классы для этой операции – String и Charset. Для точности преобразования важно учитывать соответствие кодировок между байтовым потоком и строками.
Основной метод преобразования байтов в символы – использование конструктора String(byte[] bytes), который интерпретирует байтовый массив с учетом системы кодирования по умолчанию. Однако для специфичных задач, например, работы с различными языками или нестандартными символами, необходимо явно указать кодировку, например, UTF-8 или ISO-8859-1.
Пример: String str = new String(bytes, StandardCharsets.UTF_8);. Важно помнить, что выбор кодировки влияет на результат, так как один и тот же байт в разных кодировках может интерпретироваться как различные символы.
Кроме этого, стоит помнить, что при работе с потоком данных или при получении байтовых массивов, связанных с внешними источниками, всегда необходимо учитывать возможные ошибки преобразования. Для таких случаев подходит использование метода getBytes(), который позволяет конвертировать строку обратно в байтовый массив, но с учетом определенной кодировки.
Использование класса String для преобразования байтов в строки

Для преобразования массива байтов в строку в Java используется класс String. Это один из самых простых и эффективных способов работы с текстовыми данными, закодированными в байтовом формате. В Java строка представляется объектом класса String, который в свою очередь хранит символы в виде массива символов (char[]).
Самый распространённый метод для преобразования байтов в строку – это конструктор String(byte[] bytes). Он принимает массив байтов и использует системную кодировку по умолчанию для интерпретации байтов как символов. Однако, если кодировка отличается от стандартной, рекомендуется явно указать её с помощью перегруженной версии конструктора:
String(byte[] bytes, String charsetName)
Пример использования:
byte[] bytes = {65, 66, 67}; // Байты, представляющие символы 'A', 'B', 'C'
String result = new String(bytes, "UTF-8");
Важно помнить, что выбор правильной кодировки критичен. Если данные закодированы в одной кодировке, а для декодирования будет использована другая, это приведет к ошибкам интерпретации символов. Например, при использовании кодировки UTF-8 и попытке декодировать байты, закодированные в ISO-8859-1, результат может быть неожиданным.
При работе с байтовыми потоками, например, при чтении данных из файла или сети, можно использовать класс InputStreamReader, который автоматически выполняет преобразование байтов в строки с учётом выбранной кодировки. В этом случае класс String применяется для извлечения строки из потока данных.
Пример чтения данных с использованием InputStreamReader и преобразования в строку:
import java.io.*;
public class Example {
public static void main(String[] args) throws IOException {
byte[] bytes = Files.readAllBytes(Paths.get("file.txt"));
String result = new String(bytes, "UTF-8");
System.out.println(result);
}
}
Таким образом, класс String предоставляет гибкий и удобный способ преобразования байтов в строки. Важно всегда учитывать кодировку данных и, при необходимости, указывать её при создании строки. В противном случае могут возникнуть проблемы с отображением или обработкой текста, особенно когда дело касается мультиязычных данных или нестандартных символов.
Как преобразовать байты в символы с помощью класса CharsetDecoder
Класс CharsetDecoder в Java позволяет преобразовывать байтовые последовательности в строки символов, используя определённую кодировку. Этот процесс полезен, когда данные представлены в виде байтов, например, при чтении файлов или сетевых сообщений.
Для работы с CharsetDecoder необходимо создать объект декодера с использованием кодировки. Рассмотрим основные шаги для выполнения преобразования байтов в символы.
- Получение экземпляра
CharsetDecoder:
Сначала нужно создать объект CharsetDecoder, используя класс Charset. Например, для кодировки UTF-8 это будет выглядеть так:
CharsetDecoder decoder = Charset.forName("UTF-8").newDecoder();- Декодирование байтов в символы:
Для декодирования используйте метод decode(), который принимает объект ByteBuffer, содержащий байты, и возвращает объект CharBuffer с декодированными символами. Пример:
ByteBuffer byteBuffer = ByteBuffer.wrap(byteArray);
CharBuffer charBuffer = decoder.decode(byteBuffer);Важно следить за корректностью содержимого байтового буфера, иначе метод может выбросить исключение.
- Обработка ошибок декодирования:
При декодировании могут возникнуть ошибки, если байты не соответствуют ожидаемой кодировке. CharsetDecoder позволяет настроить поведение при таких ошибках с помощью метода onMalformedInput() и onUnmappableCharacter().
onMalformedInput()– задаёт обработку, когда последовательность байтов не соответствует ожидаемой кодировке.onUnmappableCharacter()– определяет, как вести себя, если символ не может быть отображён в целевой кодировке.
Пример настройки обработки ошибок:
CharsetDecoder decoder = Charset.forName("UTF-8").newDecoder()
.onMalformedInput(CodingErrorAction.REPLACE)
.onUnmappableCharacter(CodingErrorAction.REPLACE);- Завершение работы с декодером:
После завершения декодирования, объект CharsetDecoder может быть сброшен или использован повторно для других преобразований, если это необходимо. Чтобы корректно завершить обработку, можно использовать метод reset().
decoder.reset();Таким образом, использование CharsetDecoder позволяет эффективно и гибко преобразовывать байты в символы, учитывая особенности кодировки и возможные ошибки.
Ручное преобразование байтов в символы: работа с массивами байтов
Для преобразования байтов в символы в Java часто используется стандартный класс {@code String}, который автоматически выполняет декодирование байтов. Однако, иногда требуется ручное управление этим процессом, особенно когда необходимо задать конкретную кодировку или обработать байтовый массив нестандартным образом.
Основной метод для ручного преобразования байтов в строку – это использование класса {@code Charset}. Например, если мы работаем с массивом байтов, полученных в другой системе или переданных по сети, и знаем, что они закодированы в определённой кодировке, можно использовать следующий код:
byte[] byteArray = {...};
Charset charset = Charset.forName("UTF-8");
String decodedString = new String(byteArray, charset);В приведённом примере используется кодировка {@code UTF-8}, которая широко используется для кодирования текстовых данных. Важно правильно выбрать кодировку, так как ошибка в кодировке может привести к некорректному отображению символов.
При работе с байтовыми массивами важно учитывать их размер и границы. Неправильное определение длины массива может привести к {@code IndexOutOfBoundsException} или некорректной интерпретации данных. Чтобы избежать ошибок, необходимо точно следить за границами при извлечении байтов из массива.
Если нужно преобразовать только часть байтового массива, можно передать дополнительный параметр для указания длины. Например, чтобы декодировать первые 10 байтов, можно использовать следующий код:
String partialString = new String(byteArray, 0, 10, charset);При этом следует помнить, что каждый символ в строке может занимать разное количество байтов в зависимости от используемой кодировки. В UTF-8, например, один символ может занимать от 1 до 4 байтов.
В случае, если необходимо преобразовать байты в символы вручную, без использования встроенных классов, можно использовать цикл для итерации по байтам и их преобразования в {@code char} с учётом кодировки. Однако такой подход требует тщательной настройки кодировки и проверки каждого байта для корректного формирования символов.
Кроме того, при работе с байтами важно помнить о возможности ошибок кодировки. В случае ошибок преобразования (например, если байты не могут быть интерпретированы в заданной кодировке), будет выброшено исключение {@code UnsupportedEncodingException}. Поэтому рекомендуется использовать обработку исключений для защиты от таких ситуаций.
Решение проблем кодировки при преобразовании байтов в символы
При преобразовании байтов в символы на Java важно правильно учитывать кодировку данных. Проблемы могут возникать, когда байты, представляющие символы, не соответствуют ожидаемой кодировке, что приводит к искажению или потере информации.
Одной из распространенных ошибок является использование неверной кодировки при декодировании байтов. Например, при чтении данных из файла, где используется кодировка UTF-8, попытка декодировать эти байты как ISO-8859-1 может привести к получению неправильных символов. Чтобы избежать таких проблем, необходимо всегда явно указывать кодировку при создании объектов типа String, например:
String decodedString = new String(byteArray, StandardCharsets.UTF_8);
Использование стандартных кодировок, таких как UTF-8 или UTF-16, помогает минимизировать ошибки преобразования. Важно отметить, что Java предоставляет стандартный набор кодировок через класс StandardCharsets, что позволяет избежать ошибок, связанных с неправильно указанными кодировками.
Если байты поступают из разных источников с различными кодировками, необходимо привести их к одной общей кодировке, чтобы гарантировать корректность обработки. Для этого можно использовать класс CharsetDecoder, который позволяет более гибко контролировать процесс преобразования байтов в символы, включая управление ошибками и исключениями при несоответствии кодировок.
Дополнительной проблемой может быть потеря данных при преобразовании байтов в символы, если кодировка символов не поддерживает все байты исходных данных. В таком случае можно использовать методы, позволяющие игнорировать ошибочные байты или заменять их на специальные символы, например:
String decodedString = new String(byteArray, Charset.forName("UTF-8").newDecoder()
.onMalformedInput(CodingErrorAction.REPORT)
.onUnmappableCharacter(CodingErrorAction.REPLACE));
Этот подход позволяет точно контролировать процесс и предотвращать потерю информации.
Для получения корректного результата важно всегда помнить о правильной обработке исключений, которые могут возникать в случае несоответствия кодировок. Использование try-catch блоков для перехвата таких ошибок позволяет своевременно реагировать на проблемы и корректировать их.
Как избежать ошибок при конвертации данных из byte[] в строку
![Как избежать ошибок при конвертации данных из byte[] в строку](/wp-content/images5/kak-preobrazovat-schitannie-bajti-v-simvoli-java-8w9cat8i.jpg)
При преобразовании массива байтов в строку в Java важно учитывать кодировку. Ошибки возникают, если кодировка массива байтов не соответствует ожидаемой кодировке строки. Это особенно актуально при работе с текстами на разных языках, где символы могут занимать разное количество байтов.
Для правильного преобразования используйте конструктор строки, который принимает массив байтов и кодировку. Пример:
String str = new String(byteArray, "UTF-8");Использование кодировки по умолчанию может привести к ошибкам при декодировании, особенно если данные были закодированы в нестандартной или другой кодировке. Убедитесь, что кодировка, передаваемая в конструктор, соответствует той, в которой были закодированы данные.
Важно также проверить, что массив байтов не пуст. Пустой массив может быть не распознан корректно и привести к исключению или получению неожиданного результата. Пример обработки пустого массива:
if (byteArray != null && byteArray.length > 0) {
String str = new String(byteArray, "UTF-8");
} else {
// Обработка ошибки
}Другой распространённой ошибкой является неверное определение длины массива байтов. Если длина передаваемого массива меньше, чем фактическое количество данных, это приведет к повреждению строки. Для корректного использования массива байтов обязательно проверяйте его длину и целостность данных перед преобразованием.
Кроме того, используйте метод Charset.forName("UTF-8") вместо строки с кодировкой для лучшей совместимости:
String str = new String(byteArray, Charset.forName("UTF-8"));Для чтения данных из внешних источников, например, файлов или сетевых соединений, всегда проверяйте, что входные данные имеют правильную кодировку, особенно если они могут быть сжаты или зашифрованы. Неверная кодировка на этапе записи может привести к необратимым ошибкам при чтении.
Следуя этим рекомендациям, вы сможете избежать большинства распространённых ошибок при конвертации байтов в строку и обеспечить корректную обработку данных.
Практическое применение преобразования байтов в символы в реальных проектах
Примером реального применения является обработка данных, поступающих через HTTP-запросы. Когда клиент отправляет данные в виде байтов, сервер должен корректно интерпретировать эти байты, используя правильную кодировку (например, UTF-8), чтобы извлечь из них текст. В Java для таких целей используется класс `InputStreamReader`, который позволяет преобразовывать байты в символы, применяя нужную кодировку.
Другой пример – работа с текстовыми файлами в различных кодировках. Если данные, записанные в файле, не совпадают с ожидаемой кодировкой, то байты будут интерпретированы неверно. В таких случаях использование `BufferedReader` и указание правильной кодировки через конструктор помогает избежать ошибок при чтении данных, гарантируя точность преобразования байтов в символы.
В проектах, работающих с базами данных, часто встречаются ситуации, когда строковые данные передаются в виде байтовых массивов. Для корректного извлечения данных из базы данных в Java можно использовать методы, которые преобразуют байты в строки с учетом кодировки, например, `new String(byte[] data, Charset charset)`. Такой подход необходим для правильного отображения символов в локализованных приложениях, работающих с многоязычными данными.
Сетевые приложения, такие как чаты или почтовые клиенты, также активно используют преобразование байтов в символы. Когда данные передаются по сети, они часто сжимаются или шифруются, и необходимо преобразовать полученные байты обратно в строку для дальнейшей обработки. В таких случаях важно учитывать не только кодировку, но и возможные особенности передачи данных, такие как использование бинарных форматов.
При работе с большими объемами данных, где эффективность обработки критична, правильное управление кодировками также играет ключевую роль. Например, при использовании потоков для чтения или записи данных важно минимизировать количество преобразований, а также использовать буферизацию для ускорения работы с байтами.