

При обработке текстовых данных нередко возникает задача извлечения всех чисел из строки и получения их суммы. В Python это можно реализовать несколькими способами: через регулярные выражения, списковые включения и встроенные функции. Каждый из подходов имеет свои особенности и подходит для разных случаев.
Если строка может содержать числа в произвольных местах, включая отрицательные значения и числа с плавающей точкой, оптимальным решением будет использование модуля re. Например, выражение r’-?\d+(\.\d+)?’ позволяет находить как целые, так и дробные числа, включая отрицательные. После извлечения чисел их можно преобразовать с помощью map(float, …) и просуммировать функцией sum().
В случаях, когда строка содержит только положительные целые числа, разделённые пробелами или другими символами, можно использовать метод split() и фильтрацию через isdigit(). Такой способ быстрее, но не универсален и не распознаёт числа, встроенные в слова или содержащие знаки препинания.
Следует учитывать, что строки с шумами (например, «abc12.3def-7g») требуют точного регулярного выражения. Также важно конвертировать найденные подстроки в подходящий числовой тип: int или float, в зависимости от ожидаемого результата. Ошибки преобразования необходимо перехватывать через try/except, если данные могут быть невалидными.
Практика показывает, что регулярные выражения обеспечивают наибольшую гибкость при извлечении чисел из строки. При этом желательно заранее понимать структуру входных данных, чтобы выбрать наименее затратный по ресурсам способ.
Как извлечь все числа из строки с помощью регулярных выражений
Для извлечения чисел из строки в Python используется модуль re. Регулярное выражение \d+ находит все последовательности цифр, соответствующие целым положительным числам.
Пример кода:
import re
s = "В строке 3 числа: 15, 200 и 7"
numbers = re.findall(r'\d+', s)
print(numbers) # ['15', '200', '7']
Результат – список строковых представлений чисел. Чтобы преобразовать их в целые числа, используйте map(int, …) или генераторное выражение:
int_numbers = [int(n) for n in re.findall(r'\d+', s)]
Для извлечения отрицательных чисел применяют выражение -?\d+. Символ ? делает минус необязательным:
s = "Числа: -5, 10, -42"
numbers = [int(n) for n in re.findall(r'-?\d+', s)]
print(numbers) # [-5, 10, -42]
Если нужно учитывать десятичные дроби, используйте -?\d+(?:\.\d+)?. Тут (?:…) – это группа без сохранения, \. экранирует точку, а ? делает дробную часть необязательной:
s = "Числа: 3.14, -2.5, 100"
numbers = [float(n) for n in re.findall(r'-?\d+(?:\.\d+)?', s)]
print(numbers) # [3.14, -2.5, 100.0]
Для повышения надёжности регулярного выражения следует использовать границы слова \b, чтобы исключить части слов, например, в «abc123def»:
re.findall(r'\b\d+\b', "abc123def 456") # ['456']
Регулярные выражения позволяют точно управлять форматом извлекаемых чисел и работают быстрее по сравнению с посимвольным разбором строки.
Чем отличаются целые и вещественные числа при парсинге строки

Целые числа (int) и вещественные (float) обрабатываются по-разному из-за различий в синтаксисе. При парсинге строки регулярное выражение для целых чисел обычно выглядит как \b\d+\b, а для вещественных – \b\d+\.\d+\b. Вещественные числа требуют обязательного наличия точки, иначе они будут интерпретированы как целые.
Например, в строке «Цена: 12.50, скидка: 3» число 12.50 считается вещественным, а 3 – целым. Если использовать шаблон только для целых чисел, 12.50 будет пропущено или разобьётся на 12 и 50, что приведёт к искажению суммы.
При извлечении всех чисел стоит использовать комбинированное регулярное выражение: \b\d+\.\d+|\d+\b. Это позволит получить как целые, так и вещественные значения. Для преобразования строк в числа применяют float(), поскольку он распознаёт оба типа. Использование int() приводит к ошибке при попытке обработать дробное число.
Также важно учитывать формат чисел: «1.000» может означать одну тысячу в одном контексте и одно целое число в другом, если локаль использует запятую как десятичный разделитель. Для парсинга чисел с запятой как десятичным знаком требуется предварительная замена «,» на «.» перед конвертацией в float.
Наконец, для избежания потери точности при сложении большого количества вещественных чисел рекомендуется использовать math.fsum() вместо встроенной функции sum().
Как обработать отрицательные числа в строке
Для корректного суммирования отрицательных чисел в строке важно учесть знак минус как часть числа, а не как отдельный символ. Простое использование метода re.findall(r'\d+', s) приведёт к игнорированию знаков, поскольку он извлекает только положительные числа. Чтобы обрабатывать отрицательные, необходимо использовать более точное регулярное выражение.
Пример регулярного выражения:
import re
s = "Числа: -3, 12, и -7 в строке"
numbers = re.findall(r'-?\d+', s)
total = sum(map(int, numbers))
Выражение -?\d+ ищет последовательности цифр, перед которыми может быть один минус. Это покрывает как положительные, так и отрицательные значения. Однако оно не обрабатывает ситуации, где между минусом и числом могут быть пробелы или лишние символы.
Для более строгого контроля контекста чисел лучше использовать границы слова или явные условия:
numbers = re.findall(r'(?Здесь конструкция (?<!\d) исключает случай, когда минус является частью предыдущего числа, например в диапазоне 5-3, предотвращая ошибочное объединение цифр.
Рекомендуется всегда явно приводить результат к int перед суммированием, чтобы избежать ошибок при использовании других типов данных, например строк.
Можно ли найти числа в строке без регулярных выражений

Да, числа в строке можно находить без использования модуля re, применяя стандартные методы строк и базовые конструкции языка Python. Один из рабочих подходов – построчный разбор символов с формированием числовых фрагментов вручную.
Для начала стоит пройтись по строке посимвольно и собирать подряд идущие цифры в буфер. Как только встречается символ, не являющийся цифрой, нужно проверить, есть ли что-то в буфере. Если есть – это число, его можно преобразовать в int и сохранить. После этого буфер очищается.
Пример реализации:
def extract_numbers(text):
numbers = []
buffer = ''
for char in text:
if char.isdigit():
buffer += char
elif buffer:
numbers.append(int(buffer))
buffer = ''
if buffer:
numbers.append(int(buffer))
return numbers
s = "abc12def34gh5"
print(sum(extract_numbers(s))) # Выведет 51
Подход работает с целыми положительными числами. Чтобы добавить поддержку отрицательных значений, потребуется усложнение логики: учитывать знак перед числом, не допуская ложных срабатываний на дефисы в словах.
Метод не требует дополнительных библиотек, работает быстрее re.findall на коротких строках и легко адаптируется под конкретные задачи, включая фильтрацию по длине числа или диапазону значений.
Что делать, если числа разделены разными символами
Если числа в строке разделены не только пробелами, но и другими символами (запятыми, точками с запятой, двоеточиями, дефисами и т.д.), нужно использовать регулярные выражения для извлечения чисел.
- Импортируйте модуль
re. - Используйте шаблон
r'-?\d+(?:\.\d+)?'для поиска целых и дробных чисел, включая отрицательные. - Функция
re.findall()вернёт список всех чисел в виде строк. - Преобразуйте каждую строку в число с помощью
int()илиfloat()и выполните суммирование.
import re
s = "12, -5; 3.5:100-7"
numbers = re.findall(r'-?\d+(?:\.\d+)?', s)
total = sum(map(float, numbers))
print(total)
Если интересуют только целые числа, замените float на int и используйте шаблон r'-?\d+'.
Для строк с необычными символами, например @ или #, шаблон менять не нужно – re.findall() игнорирует разделители, если они не входят в выражение.
Как суммировать найденные числа, не теряя точность
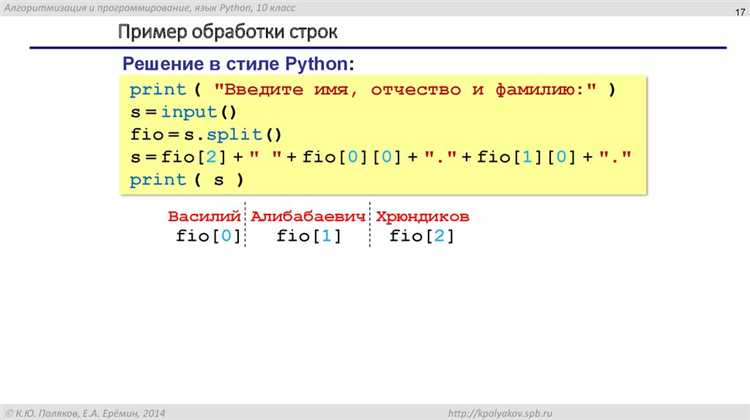
Для работы с целыми числами можно использовать стандартный тип int, который в Python поддерживает произвольную точность. Это означает, что даже очень большие целые числа будут корректно суммироваться без потери точности.
Для чисел с плавающей запятой Python использует тип float, но тут возможны ошибки округления. Это происходит из-за особенностей представления чисел с плавающей запятой в памяти. Если нужно сохранить точность при сложении, можно использовать Decimal из модуля decimal. Этот тип данных позволяет работать с числами с произвольной точностью и минимизирует ошибки округления.
Для правильной работы с Decimal следует сначала импортировать модуль:
from decimal import Decimal
Затем можно конвертировать строки в тип Decimal и производить сложение:
numbers = ['1.234', '2.456', '3.789'] sum_of_numbers = sum(Decimal(num) for num in numbers) print(sum_of_numbers)
Использование Decimal будет гарантировать точность даже при сложении чисел с множеством знаков после запятой, избегая проблем с округлением, которые характерны для float.
Кроме того, важно обращать внимание на то, как числа из строки конвертируются в типы данных. Например, использование метода float() может привести к потере точности при работе с длинными числами. В таких случаях предпочтительнее использовать Decimal или предварительно проверять, не вызывает ли конвертация в float ошибок округления.
Как обрабатывать строки со смешанным содержимым и вложенными числами
Когда строка содержит не только числа, но и текст, задача суммирования всех чисел становится сложнее. Для корректной обработки таких данных важно выделить числа, игнорируя все остальное. Если в строках могут встречаться вложенные числа (например, числа в скобках или через операторы), подход должен учитывать такие особенности.
Для начала нужно воспользоваться регулярными выражениями для извлечения чисел из строки. Регулярное выражение \d+ позволяет найти все последовательности цифр в строке. Однако, для извлечения чисел, окруженных текстом или знаками, регулярные выражения могут потребовать дополнительной настройки.
Рассмотрим пример обработки строки со смешанным содержимым:
import re
def sum_numbers_in_string(input_string):
numbers = re.findall(r'-?\d+', input_string) # Извлекаем числа, учитывая возможные минусы
return sum(map(int, numbers))
# Пример
input_string = "Цена товара: 100 рублей, скидка 20%, сумма после скидки (включая налог 10) = 80."
result = sum_numbers_in_string(input_string)
Этот код извлекает все числа из строки, включая те, что находятся в скобках, и складывает их. Регулярное выражение -?\d+ позволяет извлекать как положительные, так и отрицательные числа.
Чтобы правильно обработать строки с вложенными числами, можно использовать дополнительные проверки для выделения чисел в сложных структурах, таких как скобки или другие операторы. Например, можно учитывать только числа, которые находятся после определённых ключевых слов (например, "цена", "налог", "скидка") для конкретных типов данных.
- Важно: при извлечении чисел нужно учитывать возможные знаки "+" и "-" перед числом.
- Рекомендация: использовать регулярные выражения с флагом
re.IGNORECASE для учета регистра символов.
- Совет: для работы с вложенными скобками используйте более сложные регулярные выражения или подходы на основе стека.
Если необходимо работать с вложенными числами, например, с математическими выражениями, то будет полезно воспользоваться модулем ast, который позволяет безопасно оценивать выражения в строках. Пример:
import ast
def evaluate_expression(expression):
try:
result = ast.literal_eval(expression)
return result
except ValueError:
return None
expression = "3 + (5 * 2) - 7"
В этом случае выражение внутри скобок обрабатывается и суммируется как часть общей операции.
Таким образом, для обработки строк с числами и вложенными данными важно учитывать несколько ключевых факторов: использование регулярных выражений для извлечения чисел, настройка обработки вложенных данных и возможность использования сторонних модулей для обработки сложных математических выражений.
Вопрос-ответ:
Как можно посчитать сумму всех чисел в строке на Python?
Для того чтобы посчитать сумму всех чисел в строке на Python, можно воспользоваться регулярными выражениями и встроенными функциями. Например, можно извлечь все числа из строки с помощью регулярного выражения, а затем сложить их. Пример кода:
Что делать, если строка содержит числа с плавающей запятой?
Если строка содержит числа с плавающей запятой, необходимо использовать регулярные выражения, которые будут захватывать не только целые числа, но и числа с десятичной точкой. Вот пример кода, который может справиться с этой задачей:
Могу ли я использовать функцию sum для подсчета суммы чисел в строке?
Функция sum в Python работает с итерабельными объектами, такими как списки. Чтобы использовать sum для подсчета суммы чисел в строке, необходимо сначала извлечь все числа в список. Пример:
Как извлечь числа из строки с помощью регулярных выражений?
Для извлечения чисел из строки можно использовать регулярные выражения, которые ищут последовательности цифр. Если вам нужно извлечь числа с плавающей запятой, вы можете использовать более сложное регулярное выражение, которое захватывает и такие числа. Вот пример кода:
Что делать, если строка может содержать не только числа, но и текст?
Если строка может содержать как числа, так и текст, то необходимо использовать регулярные выражения для извлечения только чисел, игнорируя текст. Это можно сделать с помощью функции re.findall, которая вернет все совпадения для чисел в строке. После этого полученные числа можно преобразовать в целые или вещественные и сложить их. Вот пример:





